%load_ext watermark
%load_ext autoreload
%autoreload 2
import os
import ray
import torch
import logging
import pandas as pd
from ray.util.placement_group import (
placement_group,
placement_group_table,
remove_placement_group,
)
from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
from vllm import LLM, SamplingParams
%watermark -a 'Ethen' -d -v -u -p transformers,torch,numpy,pandas,ray,vllm
LLM Batch Inference with Ray and VLLM¶
This article builds towards a minimal LLM batch inference pipeline. We'll give a quick introduction to ray, VLLM, as well as tensor parallelism as part of this process before putting every piece of the building blocks together into the final solution.
Quick Introduction to Ray¶
# Create a single node Ray cluster pre-defined resources.
ray.init(
num_cpus=8,
num_gpus=4,
# avoid polluting notebook with log info
log_to_driver=False,
)
Ray enables arbitrary functions to be executed asynchronously on separate Python workers. Such functions are called Ray remote functions and their asynchronous invocations are called Ray tasks.
# By adding the `@ray.remote` decorator, a regular Python function
# becomes a Ray remote function
@ray.remote
def my_function():
return 1
# To invoke this remote function, use the `remote` method.
# This will immediately return an object ref (a future) and then create
# a task that will be executed on a worker process.
# This call is non-blocking
obj_ref = my_function.remote()
# The result can be retrieved with ``ray.get``.
assert ray.get(obj_ref) == 1
Actors extend Ray API from functions (tasks) to classes. An actor is essentially a stateful worker
# The ray.remote decorator indicates that instances of the Counter class are actors
# We can specify resource requirements as part remote
@ray.remote(num_cpus=1, num_gpus=1)
class Counter:
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
return self.value
def get_counter(self):
return self.value
# Create an actor from this class.
counter = Counter.remote()
# Call the actor.
obj_ref = counter.increment.remote()
assert ray.get(obj_ref) == 1
Ray's placement group can be used to reserve group of resouces across nodes. e.g. In distributed hyper parameter tuning, we must ensure all the resources needed for a given trial is made available at the same time, and packed resources required together, so node failures have minimal impact.
While creating these resource bundles, strategy allows us to specify whether these resources should be created to spread out on multiple nodes STRICT_SPREAD or have to be created within the same node STRICT_PACK.
We can schedule ray actors or tasks to a placement group once it has been created.
# a bundle is a collection of resources e.g. 1 CPU and 1 GPU,
# and placement group are represented by a list of bundles
pg = placement_group([{"CPU": 1, "GPU": 1}], strategy="STRICT_PACK")
ray.get(pg.ready())
# we can show placement group info through placement_group_table API
print(placement_group_table(pg))
# Create an actor to a placement group.
counter = Counter.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
placement_group_bundle_index=0
)
).remote()
obj_ref = counter.increment.remote()
assert ray.get(obj_ref) == 1
remove_placement_group(pg)
print(placement_group_table(pg))
Quick Introduction to vLLM¶
When interacting with vLLM, LLM is the main class for initiating vLLM engine, SamplingParams defines various parameters for the sampling process.
# we expect our model to be a modern instruct version that takes in chat message
messages = [
{"role": "user", "content": "Give me a short introduction to large language model."}
]
sampling_params = SamplingParams(n=1, max_tokens=512)
# we invoke chat method, compared to generate, it automatically applies
# the model's corresponding chat template
request_outputs = llm.chat(messages, sampling_params)
request_outputs
Given its output class, we will only parse out the generated text/response, as well as finish_reason. Finish reason can be useful for determining whether we are setting appropriate max generation token limit, i.e. prevent cropping model's unfinished response.
request_output = request_outputs[0]
finished_reasons = []
generated_texts = []
for request_output in request_outputs:
# we assume only sampling 1 output
output = request_output.outputs[0]
generated_texts.append(output.text)
finished_reasons.append(output.finish_reason)
predictions = {
"generated_texts": generated_texts,
"finished_reasons": finished_reasons
}
predictions
del llm
Quick Introduction to Tensor Parallelism¶
The following diagrams are directly copied from pytorch lightning's tensor parallelism illustration [3]
Data parallel is the most common form of parallelism due to its simplicity. Our model will be replicated across each device, and process data shards in parallel. Tensor parallelism is a form of model parallel technique used for large-scale models by distributing layers across multiple devices. This approach significantly reduces memory requirements per device, as each device only needs to store and process a portion of the weight matrix. There're two ways in which a linear layer can be distributed: column-wise or row-wise.
Column-wise Parallelism:

- Weight matrix is divided evenly along the column dimension.
- Each device receives identical input and performs a matrix multiplication with its allocated portion of the weight matrix.
- Final output is formed by concatenating results from all devices.
Row-wise Parallelism:

- Row-wise parallelism divides rows of the weight matrix evenly across devices. Given the weight matrix now has fewer rows, input also needs to be split along the inner dimension.
- Each device then performs a matrix multiplication with its portion of the weight matrix and inputs.
- Outputs from each device can be summed up element-wise (all-reduce) to form the final output.
Combined Column- and Row-wise Parallelism:
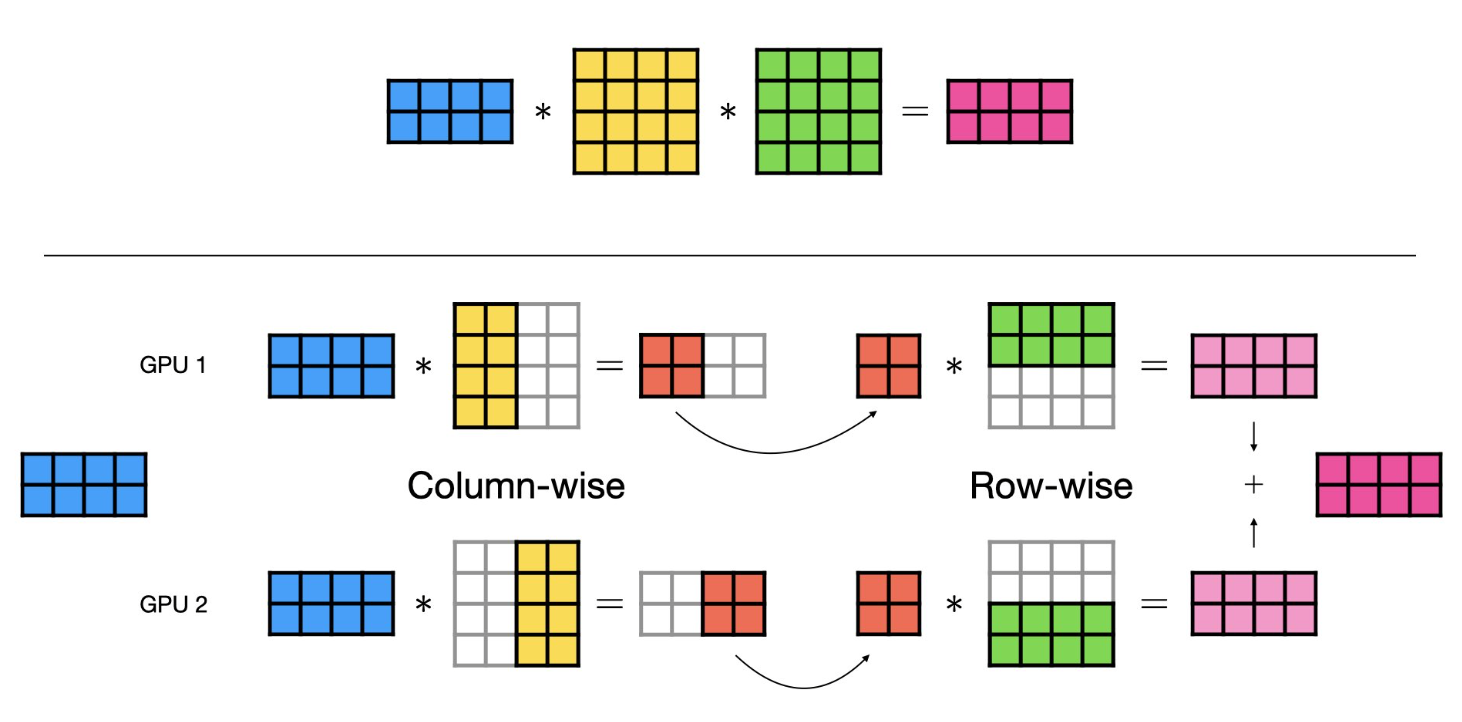
- This hybrid approach is particularly effective for model architectures that have sequential linear layers, such as MLPs or Transformers.
- The output of a column-wise parallel layer is maintained in its distributed form and directly fed into a subsequent row-wise parallel layer. This strategy minimizes inter-device data transfers, optimizing computational efficiency.
Batch Inference¶
We will now combine the knowledge we accumulated around ray core, VLLM and add in ray data for building a batch inference pipeline using 2D parallelism, data parallel plus tensor parallel [1] [2].
Our example demonstrates parallelization configured for multiple GPUs within a single machine. However, the primary application of 2D parallelism is in multi-node environments, where it often involves applying data parallelism for inter-node, and tensor parallelism for intra-node. Reason being tensor parallelism necessitates blocking collective calls, making rapid communication crucial for maintaining high throughput.
Data Parallelism (across nodes)
<----------------------------->
Node 0 Node 1
+------------+ +------------+
| GPU 0 | | GPU 0 |
| ↕ | | ↕ |
| GPU 1 | | GPU 1 |
+------------+ +------------+
↕ ↕
Tensor Parallel Tensor Parallel
Legend:
↔ Data Parallelism: Horizontal scaling across nodes
↕ Tensor Parallelism: Vertical scaling across all GPUs within a node# we pick a smaller model to quickly showcase the concept, it's very likely
# a pure data parallel approach is faster for this model
pretrained_model_name_or_path = "Qwen/Qwen2.5-1.5B-Instruct"
# Set tensor parallelism per instance.
tensor_parallel_size = 2
# Set number of instances. Each instance will use tensor_parallel_size GPUs.
num_instances = 4
concurrency = num_instances // tensor_parallel_size
prediction_path = "vllm_prediction"
sampling_params = SamplingParams(n=1, temperature=0.6, max_tokens=512)
# Create a Ray Dataset from the list of dictionaries, so we can quickly mock some input data
# in real world scenarios, read from actual data ray.data.read_parquet / ray.data.read_text
data_dicts = [{"messages": messages}] * 32
ds = ray.data.from_items(data_dicts).repartition(concurrency)
# Define a class for inference.
# Use class to initialize the model just once in `__init__`
# and re-use it for inference across multiple batches.
class LLMPredictor:
def __init__(
self,
pretrained_model_name_or_path: str,
sampling_params: SamplingParams,
tensor_parallel_size: int = 1,
):
self.llm = LLM(
pretrained_model_name_or_path,
tensor_parallel_size=tensor_parallel_size,
dtype=torch.bfloat16,
)
self.sampling_params = sampling_params
# Logic for inference on 1 batch of data.
def __call__(self, batch):
batch_messages = [text.tolist() for text in batch["messages"]]
request_outputs = self.llm.chat(batch_messages, self.sampling_params)
finished_reasons = []
generated_texts = []
for request_output in request_outputs:
# we assume only sampling 1 output
output = request_output.outputs[0]
generated_texts.append(output.text)
finished_reasons.append(output.finish_reason)
return {
"generated_texts": generated_texts,
"finished_reasons": finished_reasons
}
def scheduling_strategy_fn():
"""For tensor_parallel_size > 1, we need to create one bundle per tensor parallel worker"""
pg = placement_group(
[{"CPU": 1, "GPU": 1}] * tensor_parallel_size,
strategy="STRICT_PACK"
)
return dict(
scheduling_strategy=PlacementGroupSchedulingStrategy(
pg, placement_group_capture_child_tasks=True)
)
# define resources required for each actor
resources_kwarg = {}
if tensor_parallel_size == 1:
# For tensor_parallel_size == 1, we simply set num_gpus=1.
resources_kwarg["num_gpus"] = 1
else:
# Otherwise, we have to set num_gpus=0 and provide
# a function that will create a placement group for
# each instance.
resources_kwarg["num_gpus"] = 0
resources_kwarg["ray_remote_args_fn"] = scheduling_strategy_fn
ds_prediction = ds.map_batches(
LLMPredictor,
concurrency=concurrency,
batch_size=4,
fn_constructor_kwargs={
"pretrained_model_name_or_path": pretrained_model_name_or_path,
"tensor_parallel_size": tensor_parallel_size,
"sampling_params": sampling_params,
},
**resources_kwarg,
)
ds_prediction.write_parquet(prediction_path)
# reading some sample output to showcase valid
# LLM inference result
pd.read_parquet(prediction_path).iloc[:3].values