# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format='retina'
import os
import re
import time
import requests
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from lightgbm import plot_importance
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, OrdinalEncoder
%watermark -a 'Ethen' -d -t -v -p numpy,pandas,sklearn,matplotlib,xgboost,lightgbm
LightGBM¶
Gradient boosting is a machine learning technique that produces a prediction model in the form of an ensemble of weak classifiers, optimizing for a differentiable loss function. One of the most popular types of gradient boosting is gradient boosted trees, that internally is made up of an ensemble of week decision trees. There are two different ways to compute the trees: level-wise and leaf-wise as illustrated by the diagram below:
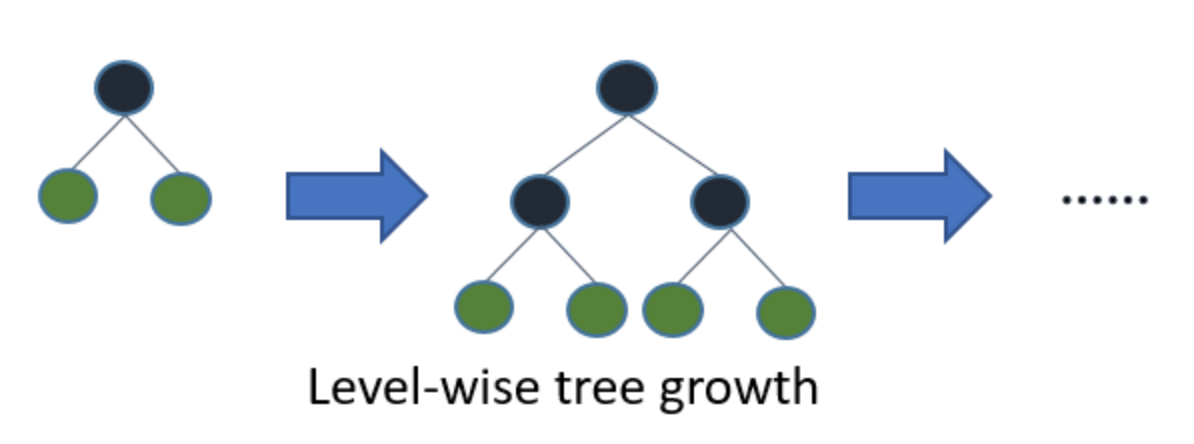
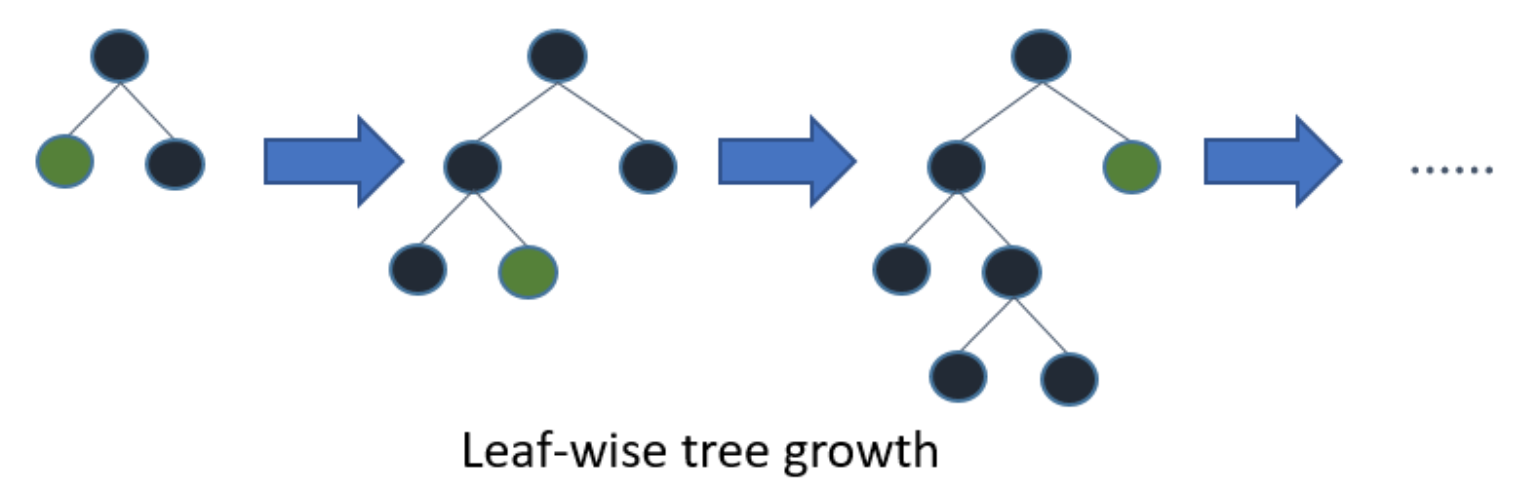
The level-wise strategy adds complexity extending the depth of the tree level by level. As a contrary, the leaf-wise strategy generates branches by optimizing a loss.
The level-wise strategy grows the tree level by level. In this strategy, each node splits the data prioritizing the nodes closer to the tree root. The leaf-wise strategy grows the tree by splitting the data at the nodes with the highest loss change. Level-wise growth is usually better for smaller datasets whereas leaf-wise tends to overfit. Leaf-wise growth tends to excel in larger datasets where it is considerably faster than level-wise growth.
A key challenge in training boosted decision trees is the computational cost of finding the best split for each leaf. Conventional techniques find the exact split for each leaf, and require scanning through all the data in each iteration. A different approach approximates the split by building histograms of the features. That way, the algorithm doesn’t need to evaluate every single value of the features to compute the split, but only the bins of the histogram, which are bounded. This approach turns out to be much more efficient for large datasets, without adversely affecting accuracy.
With all of that being said LightGBM is a fast, distributed, high performance gradient boosting that was open-source by Microsoft around August 2016. The main advantages of LightGBM includes:
- Faster training speed and higher efficiency: LightGBM use histogram based algorithm i.e it buckets continuous feature values into discrete bins which fasten the training procedure.
- Lower memory usage: Replaces continuous values to discrete bins which result in lower memory usage.
- Better accuracy than any other boosting algorithm: It produces much more complex trees by following leaf wise split approach rather than a level-wise approach which is the main factor in achieving higher accuracy. However, it can sometimes lead to overfitting which can be avoided by setting the max_depth parameter.
- Compatibility with Large Datasets: It is capable of performing equally good with large datasets with a significant reduction in training time as compared to XGBoost.
- Parallel learning supported.
The significant speed advantage of LightGBM translates into the ability to do more iterations and/or quicker hyperparameter search, which can be very useful if we have a limited time budget for optimizing your model or want to experiment with different feature engineering ideas.
Data Preprocessing¶
This notebook compares LightGBM with XGBoost, another extremely popular gradient boosting framework by applying both the algorithms to a dataset and then comparing the model's performance and execution time. Here we will be using the Adult dataset that consists of 32561 observations and 14 features describing individuals from various countries. Our target is to predict whether a person makes <=50k or >50k annually on basis of the other information available. Dataset consists of 32561 observations and 14 features describing individuals.
def get_data():
file_path = 'adult.csv'
if not os.path.isfile(file_path):
def chunks(input_list, n_chunk):
"""take a list and break it up into n-size chunks"""
for i in range(0, len(input_list), n_chunk):
yield input_list[i:i + n_chunk]
columns = [
'age',
'workclass',
'fnlwgt',
'education',
'education_num',
'marital_status',
'occupation',
'relationship',
'race',
'sex',
'capital_gain',
'capital_loss',
'hours_per_week',
'native_country',
'income'
]
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data'
r = requests.get(url)
raw_text = r.text.replace('\n', ',')
splitted_text = re.split(r',\s*', raw_text)
data = list(chunks(splitted_text, n_chunk=len(columns)))
data = pd.DataFrame(data, columns=columns).dropna(axis=0, how='any')
data.to_csv(file_path, index=False)
data = pd.read_csv(file_path)
return data
data = get_data()
print('dimensions:', data.shape)
data.head()
label_col = 'income'
cat_cols = [
'workclass',
'education',
'marital_status',
'occupation',
'relationship',
'race',
'sex',
'native_country'
]
num_cols = [
'age',
'fnlwgt',
'education_num',
'capital_gain',
'capital_loss',
'hours_per_week'
]
print('number of numerical features: ', len(num_cols))
print('number of categorical features: ', len(cat_cols))
label_encode = LabelEncoder()
data[label_col] = label_encode.fit_transform(data[label_col])
y = data[label_col].values
data = data.drop(label_col, axis=1)
print('labels distribution:', np.bincount(y) / y.size)
test_size = 0.1
split_random_state = 1234
df_train, df_test, y_train, y_test = train_test_split(
data, y, test_size=test_size,
random_state=split_random_state, stratify=y)
df_train = df_train.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
print('dimensions:', df_train.shape)
df_train.head()
We'll perform very little feature engineering as that's not our main focus here. The following code chunk only one hot encodes the categorical features. There will be follow up discussions on this in later section.
from sklearn.preprocessing import OneHotEncoder
one_hot_encoder = OneHotEncoder(sparse=False, dtype=np.int32)
one_hot_encoder.fit(df_train[cat_cols])
cat_one_hot_cols = one_hot_encoder.get_feature_names(cat_cols)
print('number of one hot encoded categorical columns: ', len(cat_one_hot_cols))
cat_one_hot_cols[:5]
def preprocess_one_hot(df, one_hot_encoder, num_cols, cat_cols):
df = df.copy()
cat_one_hot_cols = one_hot_encoder.get_feature_names(cat_cols)
df_one_hot = pd.DataFrame(
one_hot_encoder.transform(df[cat_cols]),
columns=cat_one_hot_cols
)
df_preprocessed = pd.concat([
df[num_cols],
df_one_hot
], axis=1)
return df_preprocessed
df_train_one_hot = preprocess_one_hot(df_train, one_hot_encoder, num_cols, cat_cols)
df_test_one_hot = preprocess_one_hot(df_test, one_hot_encoder, num_cols, cat_cols)
print(df_train_one_hot.shape)
df_train_one_hot.dtypes
Benchmarking¶
The next section compares the xgboost and lightgbm's implementation in terms of both execution time and model performance. There are a bunch of other hyperparameters that we as the end-user can specify, but here we explicity specify arguably the most important ones.
time.sleep(5)
lgb = LGBMClassifier(
n_jobs=-1,
max_depth=6,
subsample=1,
n_estimators=100,
learning_rate=0.1,
colsample_bytree=1,
objective='binary',
boosting_type='gbdt')
start = time.time()
lgb.fit(df_train_one_hot, y_train)
lgb_elapse = time.time() - start
print('elapse:, ', lgb_elapse)
time.sleep(5)
# raw xgboost
xgb = XGBClassifier(
n_jobs=-1,
max_depth=6,
subsample=1,
n_estimators=100,
learning_rate=0.1,
colsample_bytree=1,
objective='binary:logistic',
booster='gbtree')
start = time.time()
xgb.fit(df_train_one_hot, y_train)
xgb_elapse = time.time() - start
print('elapse:, ', xgb_elapse)
XGBoost includes a tree_method = 'hist'option that buckets continuous variables into bins to speed up training, we also set grow_policy = 'lossguide' to favor splitting at nodes with highest loss change, which mimics LightGBM.
time.sleep(5)
xgb_hist = XGBClassifier(
n_jobs=-1,
max_depth=6,
subsample=1,
n_estimators=100,
learning_rate=0.1,
colsample_bytree=1,
objective='binary:logistic',
booster='gbtree',
tree_method='hist',
grow_policy='lossguide')
start = time.time()
xgb_hist.fit(df_train_one_hot, y_train)
xgb_hist_elapse = time.time() - start
print('elapse:, ', xgb_hist_elapse)
# evaluate performance
y_pred = lgb.predict_proba(df_test_one_hot)[:, 1]
lgb_auc = roc_auc_score(y_test, y_pred)
print('auc score: ', lgb_auc)
y_pred = xgb.predict_proba(df_test_one_hot)[:, 1]
xgb_auc = roc_auc_score(y_test, y_pred)
print('auc score: ', xgb_auc)
y_pred = xgb_hist.predict_proba(df_test_one_hot)[:, 1]
xgb_hist_auc = roc_auc_score(y_test, y_pred)
print('auc score: ', xgb_hist_auc)
# comparison table
results = pd.DataFrame({
'elapse_time': [lgb_elapse, xgb_hist_elapse, xgb_elapse],
'auc_score': [lgb_auc, xgb_hist_auc, xgb_auc]})
results.index = ['LightGBM', 'XGBoostHist', 'XGBoost']
results
From the resulting table, we can see that there isn't a noticeable difference in auc score between the two implementations. On the other hand, there is a significant difference in the time it takes to finish the whole training procedure. This is a huge advantage and makes LightGBM a much better approach when dealing with large datasets.
For those interested, the people at Microsoft has a blog that has a even more thorough benchmark result on various datasets. Link is included below along with a summary of their results:
Blog: Lessons Learned From Benchmarking Fast Machine Learning Algorithms
Our results, based on tests on six datasets, are summarized as follows:
- XGBoost and LightGBM achieve similar accuracy metrics.
- LightGBM has lower training time than XGBoost and its histogram-based variant, XGBoost hist, for all test datasets, on both CPU and GPU implementations. The training time difference between the two libraries depends on the dataset, and can be as big as 25 times.
- XGBoost GPU implementation does not scale well to large datasets and ran out of memory in half of the tests.
- XGBoost hist may be significantly slower than the original XGBoost when feature dimensionality is high.
Categorical Variables in Tree-based Models¶
Many real-world datasets include a mix of continuous and categorical variables. The property of the latter is that their values has zero inherent ordering. One major advantage of decision tree models and their ensemble counterparts, such as random forests, extra trees and gradient boosted trees, is that they are able to operate on both continuous and categorical variables directly (popular implementations of tree-based models differ as to whether they honor this fact). In contrast, most other popular models (e.g., generalized linear models, neural networks) must instead transform categorical variables into some numerical format, usually by one-hot encoding them to create a new dummy variable for each level of the original variable. e.g.
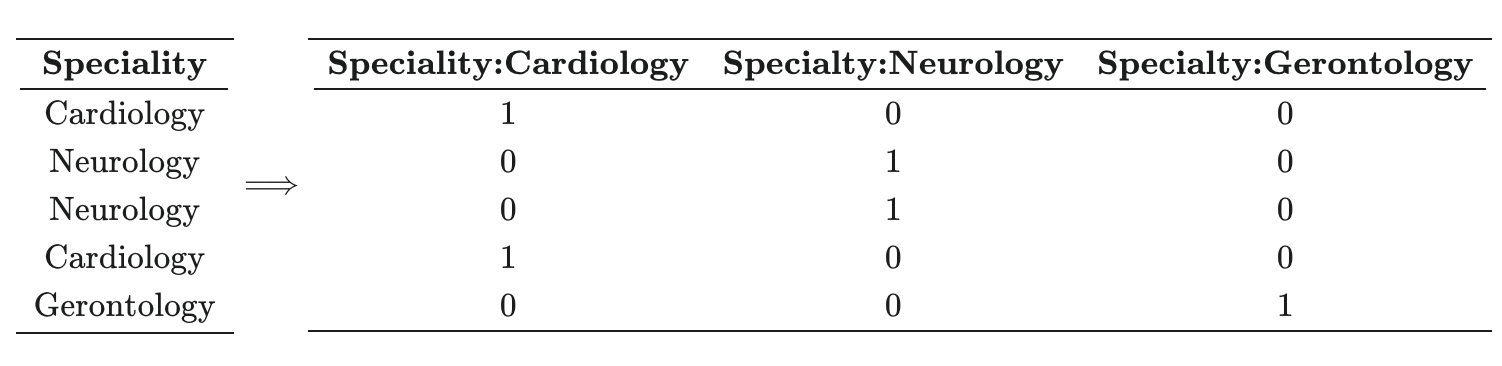
One drawback of one hot encoding is that they can lead to a huge increase in the dimensionality of the feature representations. For example, one hot encoding U.S. states adds 49 dimensions to to our feature representation.
To understand why we don't need to perform one hot encoding for tree-based models, we need to refer back to the logic of tree-based algorithms. At the heart of the tree-based algorithm is a sub-algorithm that splits the samples into two bins by selecting a feature and a value. This splitting algorithm considers each of the features in turn, and for each feature selects the value of that feature that minimizes the impurity of the bins.
This means tree-based models are essentially looking for places to split the data, they are not multiplying our inputs by weights. In contrast, most other popular models (e.g., generalized linear models, neural networks) would interpret categorical variables such as red=1, blue=2 as blue is twice the amount of red, which is obviously not what we want.
ordinal_encoder = OrdinalEncoder(dtype=np.int32)
ordinal_encoder.fit(df_train[cat_cols])
def preprocess_ordinal(df, ordinal_encoder, cat_cols, cat_dtype='int32'):
df = df.copy()
df[cat_cols] = ordinal_encoder.transform(df[cat_cols])
df[cat_cols] = df[cat_cols].astype(cat_dtype)
return df
df_train_ordinal = preprocess_ordinal(df_train, ordinal_encoder, cat_cols)
df_test_ordinal = preprocess_ordinal(df_test, ordinal_encoder, cat_cols)
print(df_train_ordinal.shape)
df_train_ordinal.dtypes
time.sleep(5)
lgb = LGBMClassifier(
n_jobs=-1,
max_depth=6,
subsample=1,
n_estimators=100,
learning_rate=0.1,
colsample_bytree=1,
objective='binary',
boosting_type='gbdt')
start = time.time()
lgb.fit(df_train_ordinal, y_train)
lgb_ordinal_elapse = time.time() - start
print('elapse:, ', lgb_ordinal_elapse)
y_pred = lgb.predict_proba(df_test_ordinal)[:, 1]
lgb_ordinal_auc = roc_auc_score(y_test, y_pred)
print('auc score: ', lgb_ordinal_auc)
# comparison table
results = pd.DataFrame({
'elapse_time': [lgb_ordinal_elapse, lgb_elapse, xgb_hist_elapse, xgb_elapse],
'auc_score': [lgb_ordinal_auc, lgb_auc, xgb_hist_auc, xgb_auc]})
results.index = ['LightGBM Ordinal', 'LightGBM', 'XGBoostHist', 'XGBoost']
results
From the result above, we can see that it requires even less training time without sacrificing any sort of performance. What's even more is that we now no longer need to perform the one hot encoding on our categorical features. The code chunk below shows this is highly advantageous from a memory-usage perspective when we have a bunch of categorical features.
print('OneHot Encoding')
print('number of columns: ', df_train_one_hot.shape[1])
print('memory usage: ', df_train_one_hot.memory_usage(deep=True).sum())
print()
print('Ordinal Encoding')
print('number of columns: ', df_train_ordinal.shape[1])
print('memory usage: ', df_train_ordinal.memory_usage(deep=True).sum())
# plotting the feature importance just out of curiosity
# change default style figure and font size
plt.rcParams['figure.figsize'] = 10, 8
plt.rcParams['font.size'] = 12
# like other tree-based models, it can also output the
# feature importance plot
plot_importance(lgb, importance_type='gain')
plt.show()

For tuning LightGBM's hyperparameter, the documentation page has some pretty good suggestions. LightGBM Documentation: Parameters Tuning
Reference¶
- LightGBM Documentation: Parameters Tuning
- Blog: xgboost’s New Fast Histogram (tree_method = hist)
- Blog: Which algorithm takes the crown: Light GBM vs XGBOOST?
- Blog: Are categorical variables getting lost in your random forests?
- Blog: Lessons Learned From Benchmarking Fast Machine Learning Algorithms
- Stackoverflow: Why tree-based model do not need one-hot encoding for nominal data?