# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', 'notebook_format'))
from formats import load_style
load_style(plot_style=False)
os.chdir(path)
# 1. magic to print version
# 2. magic so that the notebook will reload external python modules
%load_ext watermark
%load_ext autoreload
%autoreload 2
import math
import time
import logging
import requests
import threading
import multiprocessing
import concurrent.futures
from joblib import Parallel, delayed
%watermark -a 'Ethen' -d -t -v -p joblib,requests
Parallel Programming in Python¶
The essence of parallel programming is: If we have two tasks on our hand, task A and task B that does not depend on each other, we can run them simultaneously without having to wait for task A to finish before running running task B. In this tutorial, we're going to take a look at doing parallel computing in Python, we will go through the following:
- Why is parallelism tricky in Python (hint: it's because of the GIL—the global interpreter lock).
- Threads vs. Processes: Different ways of achieving parallelism. When to use one over the other?
- Parallel vs. Concurrent: Why in some cases we can settle for concurrency rather than parallelism.
- Building a simple but practical example using the various techniques discussed.
Global Interpreter Lock¶
The Global Interpreter Lock (GIL) is one of the most controversial subjects in the Python world. In CPython, the most popular implementation of Python, the GIL is a mutex (mutually exclusive object) that makes things thread-safe. The GIL makes it easy to integrate with external libraries that are not thread-safe, and it makes non-parallel code faster. This comes at a cost, though. Due to the GIL, we can't achieve true parallelism via multithreading. Basically, two different native threads of the same process can't run Python code at the same time.
Things are not that bad, though, and here's why: stuff that happens outside the GIL realm is free to be parallel. In this category fall long-running tasks like I/O and libraries like Numpy (Numpy works around this limitation by running external code in C).
Threads vs. Processes¶
From the last section, we learned that unlike other programming language, Python is not truly multithreaded as it can't run multiple threads simultaneously on multiple cores/CPUs due to the GIL. Before we move on, let's take a step back and understand what is a thread, what is a process and the distinction between them?
- A process is a program that is in execution. In other words, code that are running (e.g. Jupyter notebook, Google Chrome, Python interpreter). Multiple processes are always running in a computer, and they are executed in parallel.
- A process can spawn multiple threads (sub-processes) to handle subtasks. They live inside processes and share the same memory space (they can read and write to the same variables). Ideally, they run in parallel, but not necessarily. The reason why processes aren't enough is because applications need to be responsive and listen for user actions while updating the display and saving a file.
e.g. Microsoft Word. When we open up Word, we're essentially creating a process (an instance of the program). When we start typing, the process spawns a number of threads: one to read keystrokes, another to display text on the screen, a thread to autosave our file, and yet another to highlight spelling mistakes. By spawning multiple threads, Microsoft takes advantage of "wasted CPU time" (waiting for our keystrokes or waiting for a file to save) to provide a smoother user interface and make us more productive.
Here's a quick comparison table:
| Process | Threads |
|---|---|
| Processes don't share memory | Threads share memory |
| Spawning/switching processes is more expensive | Spawning/switching threads requires less resources |
| No memory synchronisation needed | Needs synchronization mechanisms to ensure we're correctly handling the data |
There isn't a one size fits all solution. Choosing one is greatly dependent on the context and the task we are trying to achieve.
- Multiprocessing can speed up Python operations that are CPU intensive because they benefit from multiple cores/CPUs and avoid the GIL problem.
- Multithreading has no benefit in Python for CPU intensive tasks because of GIL problem (this problem is unique to CPython), however, it is often better than multiprocessing at I/O, network operations or other tasks that rely on external systems because the threads can combine their work more efficiently (they exist in the same memory space) while multiprocessing needs to pickle the results and combine them at the end of the work.
Side note: do not mistake parallel for concurrent. Remember that only the parallel approach takes advantage of multi-core processors, whereas concurrent programming intelligently schedules tasks so that if a piece of code is waiting on long-running operations, we can run a different but independent part of the code to ensure our CPU is always busy and working. i.e. Only processes achieve true parallelism
Python's Parallel Programming Ecosystem¶
Python has built-in libraries for doing parallel programming. Here, we'll cover the most popular ones:
- threading: The standard way of working with threads in Python. It is a higher-level API wrapper over the functionality exposed by the
_threadmodule, which is a low-level interface over the operating system's thread implementation. - multiprocessing: Offers a very similar interface to the threading module but using processes instead of threads.
- concurrent.futures: A module part of the standard library that provides an even higher-level abstraction layer over threading/multiprocessing.
threading¶
We'll first take a look at the threading API. Before we create/initialize a thread, we define a simple function that simply sleeps for a specified amount of time.
def sleeper(n_time):
name = threading.current_thread().name
print('I am {}. Going to sleep for {} seconds'.format(name, n_time))
time.sleep(n_time)
print('{} has woken up from sleep'.format(name))
We then initialize our thread with the Thread class from the threading module.
target: accepts the function that we're going to execute.name: naming the thread; this allows us to easily differentiate between threads when we have multiple threads.args: pass in the argument to our function here.
# we call .start to start executing the function from the thread
n_time = 2
thread = threading.Thread(target = sleeper, name = 'thread1', args = (n_time,))
thread.start()
When we run a program and something is sleeping for a few seconds, we would have to wait for that portion to wake up before we can continue with the rest of the program, but the concurrency of threads can bypass this behavior. Suppose we consider the main program as the main thread and our thread as its own separate thread, the code chunk below demonstrates the concurrency property, i.e. we don't have to wait for the calling thread to finish before running the rest of our program.
# hello is printed "before" the wake up message from the function
thread = threading.Thread(target = sleeper, name = 'thread2', args = (n_time,))
thread.start()
print()
print('hello')
Sometimes, we don't want Python to switch to the main thread until the thread we defined has finished executing its function. To do this, we can use .join method, this is essentially what people called the blocking call. It blocks the interpreter from accessing or executing the main program until the thread finishes it task.
# hello is printed "after" the wake up message from the function
thread = threading.Thread(target = sleeper, name = 'thread3', args = (n_time,))
thread.start()
thread.join()
print()
print('hello')
The following code chunk showcase how to initialize and utilize multiple threads.
n_time = 2
n_threads = 5
start = time.time()
# create n_threads number of threads and store them in a list
threads = []
for i in range(n_threads):
name = 'thread{}'.format(i)
thread = threading.Thread(target = sleeper, name = name, args = (n_time,))
threads.append(thread)
# we can start the thread while we're creating it, or move
# this to its own loop (as shown below)
thread.start()
# we could instead start the thread in a separate loop
# for thread in threads:
# thread.start()
# ensure all threads have finished before executing main program
for thread in threads:
thread.join()
elapse = time.time() - start
print()
print('Elapse time: ', elapse)
From the result above, we can observe from the elapse time that it doesn't take n_threads * (the time we told the sleep function to sleep) amount of time to finish all the task, which is pretty neat!
concurrent.futures¶
As mentioned previously, the concurrent.futures module is part of the standard library which provides a high level API for launching asynchronous tasks. This module features the Executor class which is an abstract class and it can not be used directly, however, it has two very useful concrete subclasses – ThreadPoolExecutor and ProcessPoolExecutor. As their names suggest, one uses multithreading and the other one uses multiprocessing as their backend. In both case, we get a pool of threads or processes and we can submit tasks to this pool. The pool would assign tasks to the available resources (threads or pools) and schedule them to run.
Both executors have a common method – map(). Like the built in function, the map method allows multiple calls to a provided function, passing each of the items in an iterable to that function. Except, in this case, the functions are called concurrently.
From the documentation: For multiprocessing, this iterable is broken into chunks and each of these chunks is passed to the function in separate processes. We can control the chunk size by passing a third parameter, chunk_size. By default the chunk size is 1. For very long iterables, using a large value for chunksize can significantly improve performance compared to the default size of 1. With ThreadPoolExecutor, chunksize has no effect.
# example from the documentation page
# https://docs.python.org/3/library/concurrent.futures.html#processpoolexecutor-example
def is_prime(n):
"""
References
----------
https://math.stackexchange.com/questions/1343171/why-only-square-root-approach-to-check-number-is-prime
"""
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('{} is prime: {}'.format(number, prime))
This quick introduction should do it for now. In the next section, we'll define both an I/O task (reading a file, API calls, scraping URLs) and a CPU intensive task after that we'll benchmark the two tasks by running them serially, using multithreading and using multiprocessing.
def only_sleep():
"""Wait for a timer to expire"""
process_name = multiprocessing.current_process().name
thread_name = threading.current_thread().name
print('Process Name: {}, Thread Name: {}'.format(
process_name, thread_name))
time.sleep(4)
def crunch_numbers():
"""Do some computations """
process_name = multiprocessing.current_process().name
thread_name = threading.current_thread().name
print('Process Name: {}, Thread Name: {}'.format(
process_name, thread_name))
x = 0
while x < 10000000:
x += 1
def experiment(target, n_workers):
"""
run the target function serially, using threads,
using process and output the run time
"""
# Run tasks serially
start_time = time.time()
for _ in range(n_workers):
target()
end_time = time.time()
print("Serial time=", end_time - start_time)
print()
# Run tasks using processes
start_time = time.time()
processes = [multiprocessing.Process(target = target) for _ in range(n_workers)]
for process in processes:
process.start()
for process in processes:
process.join()
end_time = time.time()
print("Parallel time=", end_time - start_time)
print()
# Run tasks using threads
start_time = time.time()
threads = [threading.Thread(target = target) for _ in range(n_workers)]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
end_time = time.time()
print("Threads time=", end_time - start_time)
n_workers = 4
experiment(target = only_sleep, n_workers = n_workers)
Here are some observations:
- In the case of the serial approach, things are pretty obvious. We're running the tasks one after the other. All four runs are executed by the same thread of the same process.
- Using processes we cut the execution time down to a quarter of the original time, simply because the tasks are executed in parallel. Notice how each task is performed in a different process and on the MainThread of that process.
- Using threads we take advantage of the fact that the tasks can be executed concurrently. The execution time is also cut down to a quarter, even though nothing is running in parallel. Here's how that goes: we spawn the first thread and it starts waiting for the timer to expire. We pause its execution, letting it wait for the timer to expire, and in this time we spawn the second thread. We repeat this for all the threads. The moment the timer of the first thread expires, we switch execution to it and terminate it. The algorithm is repeated for the second and for all the other threads. At the end, the result is as if things were ran in parallel. Also notice that different threads branch out and live inside the same process: MainProcess.
You may even notice that the threaded approach is quicker than the truly parallel one. That's due to the overhead of spawning processes. As we noted previously, spawning and switching processes is much more expensive and requires more resources.
Let's perform the same routine but this time on the crunch_numbers function.
n_workers = 4
experiment(target = crunch_numbers, n_workers = n_workers)
The main difference here is in the result of the multithreaded approach. This time it performs very similarly to the serial approach, and here's why: since it performs computations and Python doesn't perform real parallelism, the threads are basically running one after the other until they all finish. In fact it might even be slower, as we need to take into account the overhead of launching multiple threads.
Practical Application¶
In this section, we're going to walk through all the different paradigms by building a classic application that checks the uptime of websites. The purpose of these apps is to notify us when our website is down so that we can quickly take action. Here's how they work:
- The application goes very frequently over a list of website URLs and checks if those websites are up.
- Every website should be checked every 5-10 minutes so that the downtime is not significant.
- Instead of performing a classic HTTP GET request, it performs a HEAD request so that it does not affect our traffic significantly.
- If the HTTP status is in the danger ranges (400+, 500+), the owner is notified by email, text-message, or push notification.
Here's why it's essential to take a parallel/concurrent approach to the problem. As the list of websites grows, going through the list serially won't guarantee us that every website is checked every five minutes or so. The websites could be down for hours, and the owner won't be notified.
Let's start by writing some utilities:
def check_website(address):
"""Utility function: check if a website is down, if so, notify the user"""
try:
ping_website(address)
except WebsiteDownException:
notify_owner(address)
class WebsiteDownException(Exception):
"""Exception if the website is down"""
pass
def ping_website(address, timeout = 20):
"""
Check if a website is down. A website is considered down
if either the status_code >= 400 or if the timeout expires
Throw a WebsiteDownException if any of the website down conditions are met
"""
try:
response = requests.head(address, timeout = timeout)
if response.status_code >= 400:
logging.warning('Website {} returned status code={}'.format(address, response.status_code))
raise WebsiteDownException()
except requests.exceptions.RequestException:
logging.warning('Timeout expired for website {}'.format(address))
raise WebsiteDownException()
def notify_owner(address):
"""
Send the owner of the address a notification that their website is down
For now, we're just going to sleep for 0.5 seconds but this is where
you would send an email, push notification or text-message
"""
logging.info('Notifying the owner of {} website'.format(address))
time.sleep(0.5)
Next we need some actual websites to try our system out. Create your own list or use the ones listed in the next code chunk first for experimentation. Normally, we'd keep this list in a database along with owner contact information so that you can contact them. Since this is not the main topic of this tutorial, and for the sake of simplicity, we're just going to use this Python list.
You might have noticed two really long domains in the list that are not valid websites. Those domains were added on purpose to be sure we have some websites down on every run.
WEBSITE_LIST = [
'http://envato.com',
'http://amazon.co.uk',
'http://amazon.com',
'http://facebook.com',
'http://google.com',
'http://google.fr',
'http://google.es',
'http://google.co.uk',
'http://internet.org',
'http://gmail.com',
'http://stackoverflow.com',
'http://github.com',
'http://heroku.com',
'http://really-cool-available-domain.com',
'http://djangoproject.com',
'http://rubyonrails.org',
'http://basecamp.com',
'http://trello.com',
'http://yiiframework.com',
'http://shopify.com',
'http://another-really-interesting-domain.co',
'http://airbnb.com',
'http://instagram.com',
'http://snapchat.com',
'http://youtube.com',
'http://baidu.com',
'http://yahoo.com',
'http://live.com',
'http://linkedin.com',
'http://yandex.ru',
'http://netflix.com',
'http://wordpress.com',
'http://bing.com']
First, we'll try the serial approach and use this as our baseline.
start_time = time.time()
for address in WEBSITE_LIST:
check_website(address)
end_time = time.time()
print('Time for serial: {} secs'.format(end_time - start_time))
n_workers = 4
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers = n_workers) as executor:
futures = {executor.submit(check_website, address) for address in WEBSITE_LIST}
# more detailed explanation of the wait command
# https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.wait
_ = concurrent.futures.wait(futures)
end_time = time.time()
print('Time for multithreading: {} secs'.format(end_time - start_time))
# process does not result in the same performance gain as thread
start_time = time.time()
with concurrent.futures.ProcessPoolExecutor(max_workers = n_workers) as executor:
futures = {executor.submit(check_website, address) for address in WEBSITE_LIST}
_ = concurrent.futures.wait(futures)
end_time = time.time()
print('Time for multiprocessing: {} secs'.format(end_time - start_time))
Another library for performing parallel programming is joblib. This is my personal favorite and it is also used by the machine learning package scikit-learn to perform hyperparameter search.
start_time = time.time()
# we start off by defining a Parallel class
# the backend uses multiprocessing by default,
# here we change it to threading as the task is I/O bound;
# we can set n_jobs to -1 uses all the available cores
parallel = Parallel(n_jobs = n_workers, backend = 'threading')
# we wrapped our function with delayed and pass in our list of parameters
result = parallel(delayed(check_website)(address) for address in WEBSITE_LIST)
end_time = time.time()
print('Time for joblib threading: {} secs'.format(end_time - start_time))
This is the end of our journey into the world of parallel programming in Python, here are some conclusions we can draw:
- There are several paradigms that help us achieve high-performance computing in Python.
- Only processes achieve true parallelism, but they are more expensive to create.
- In Python, use process for CPU bound tasks and thread for I/O bound task.
For a more in-depth introduction of joblib, check out the following link. Blog: A Library for Many Jobs
Synchronous Versus Asynchronous¶
Another terminology that we often encounter in this parallel programming space is asynchronous.
In synchronous programming, the tasks are assigned to a thread one after another, as depicted with the diagram below:

In a multi-threaded environment, we can take up these tasks in parallel.

In contrary to synchronous programming, in the world of asynchronous programming, once a thread start executing a task it can hold it in middle, save the current state and start executing another task.

If we look at the diagram above, we can see that a single thread is still tasked to complete all the tasks, but the tasks can interleave between one another.
Asynchronous programming becomes even more interesting under a multi-threaded environment. Tasks can be interleaved on different threads.
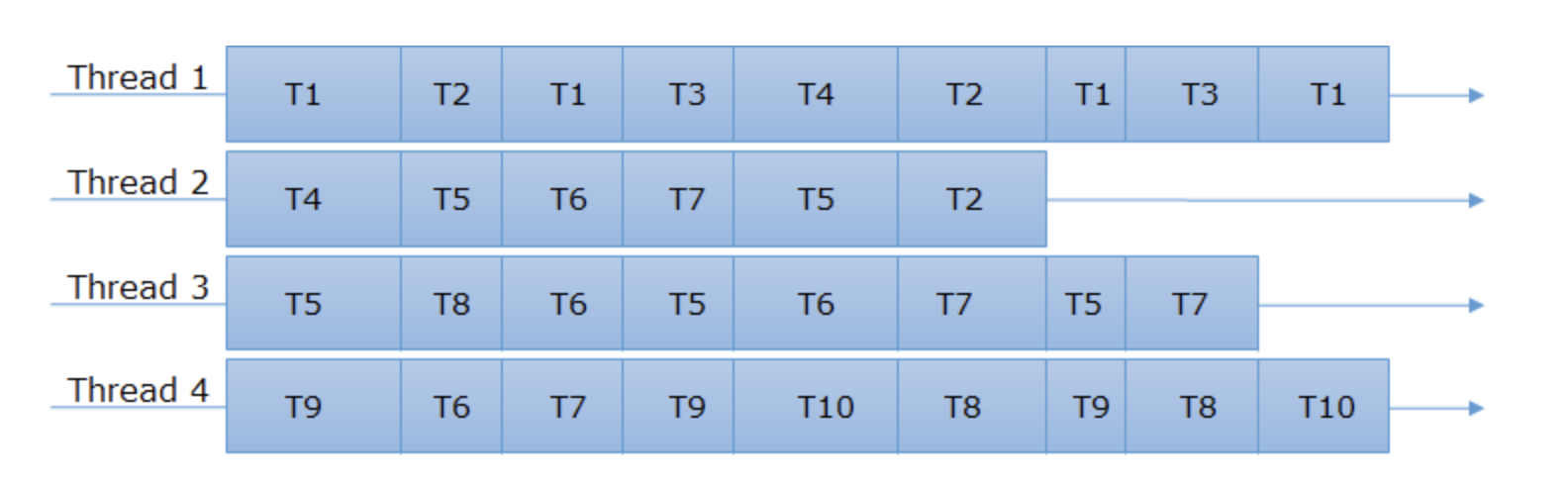
As we can see that T4 was started first in Thread 1 and completed by Thread 2.
When faced with a decision on whether to use multi-processing, multi-threading, asynchronous programming, we can use this cheat sheet.
if io_bound:
if io_very_slow:
print("Use Asyncio")
else:
print("Use Threads")
else:
print("Multi Processing")
- CPU Bound => Multi Processing.
- I/O Bound, Fast I/O, Limited Number of Connections => Multi Threading.
- I/O Bound, Slow I/O, Many connections => Asyncio (Asynchronous library in Python, which we have not covered in this post).
Reference¶
- Youtube: Python Threading - Multithreading Playlist
- Forum: Python Parallel Processing - Tips and Applications
- Blog: A Library for Many Jobs
- Blog: Python: A Quick Introduction To The concurrent.futures Module
- Blog: Introduction to Parallel and Concurrent Programming in Python
- Blog: Concurrency vs Multi-threading vs Asynchronous Programming : Explained
- Blog: Async Python: The Different Forms of Concurrency