# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(plot_style=False)
os.chdir(path)
# 1. magic to print version
# 2. magic so that the notebook will reload external python modules
%load_ext watermark
%load_ext autoreload
%autoreload 2
import numpy as np
import pandas as pd
%watermark -a 'Ethen' -d -t -v -p numpy,pandas
Understanding Pandas Data Type¶
When working using pandas with small data (under 100 megabytes), performance is rarely a problem. When we move to larger data (100 megabytes to multiple gigabytes), performance issues can make run times much longer, and cause code to fail entirely due to insufficient memory. While tools like Spark can handle large data sets (100 gigabytes to multiple terabytes), taking full advantage of their capabilities usually requires more expensive hardware. And unlike pandas, they lack rich feature sets for high quality data cleaning, exploration, and analysis. For medium-sized data, we're better off trying to get more out of pandas, rather than switching to a different tool.
In this documentation, we'll learn about memory usage with pandas, how to make pandas DataFrame smaller and faster, simply by selecting the appropriate data types for columns.
drinks = pd.read_csv('http://bit.ly/drinksbycountry')
drinks.head()
We'll first look at the memory usage of each column, because we're interested in accuracy, we'll set the argument deep to True to get an accurate number.
# drinks.info(memory_usage = 'deep')
# also works, it gives slightly different information
drinks.memory_usage(deep=True)
Under the hood, pandas groups the columns into blocks of values of the same type, because each data type is stored separately, we’re going to examine the memory usage by each data type.
for dtype in ('float', 'int', 'object'):
selected_dtype = drinks.select_dtypes(include = [dtype])
mean_usage_b = selected_dtype.memory_usage(deep=True).mean()
# we can do / 1024 ** 2 to convert bytes to megabytes
print("Average memory usage for {} columns: {:03.2f} B".format(dtype, mean_usage_b))
Immediately we can see that most of our memory is used by our object columns. We'll look at those later, but first lets see if we can improve on the memory usage for our numeric columns.
Optimizing Numeric Columns¶
For blocks representing numeric values like integers and floats, pandas combines the columns and stores them as a NumPy ndarray. The NumPy ndarray is built around a C array, and the values are stored in a contiguous block of memory. This storage model consumes less space and allows us to access the values themselves quickly.
Many types in pandas have multiple subtypes that can use fewer bytes to represent each value. For example, the float type has the float16, float32, and float64 subtypes. The number portion of a type's name indicates the number of bits that type uses to represent values. For example, the subtypes we just listed use 2, 4, 8 and 16 bytes, respectively. The following table shows the subtypes for the most common pandas types:
| memory usage | float | int | uint | datetime | bool |
|---|---|---|---|---|---|
| 1 bytes | int8 | uint8 | bool | ||
| 2 bytes | float16 | int16 | uint16 | ||
| 4 bytes | float32 | int32 | uint32 | ||
| 8 bytes | float64 | int64 | uint64 | datetime64 |
An int8 value uses 1 byte (or 8 bits) to store a value, and can represent 256 values (2^8) in binary. This means that we can use this subtype to represent values ranging from -128 to 127 (including 0). And uint8, which is unsigned int, means we can only have positive values for this type, thus we can represent 256 values ranging from 0 to 255.
We can use the numpy.iinfo class to verify the minimum and maximum values for each integer subtype. Let's look at an example:
int_types = ['uint8', 'int8', 'int16']
for int_type in int_types:
print(np.iinfo(int_type))
We can use the function pd.to_numeric() to downcast our numeric types. We’ll use DataFrame.select_dtypes to select only the integer columns, then we’ll optimize the types and compare the memory usage.
def mem_usage(pandas_obj):
"""memory usage of a pandas DataFrame or Series"""
# we assume if not a DataFrame it's a Series
if isinstance(pandas_obj, pd.DataFrame):
usage_b = pandas_obj.memory_usage(deep=True).sum()
else:
usage_b = pandas_obj.memory_usage(deep=True)
return '{:03.2f} B'.format(usage_b)
drinks_int = drinks.select_dtypes(include=['int'])
converted_int = drinks_int.apply(pd.to_numeric, downcast='unsigned')
print(mem_usage(drinks_int))
print(mem_usage(converted_int))
Lets do the same thing with our float columns.
drinks_float = drinks.select_dtypes(include=['float'])
converted_float = drinks_float.apply(pd.to_numeric, downcast='float')
print(mem_usage(drinks_float))
print(mem_usage(converted_float))
Optimizing object types¶
The object type represents values using Python string objects, partly due to the lack of support for missing string values in NumPy. Because Python is a high-level, interpreted language, it doesn't have fine grained-control over how values in memory are stored.
We'll use sys.getsizeof() to prove this out, first by looking at individual strings, and then items in a pandas series.
from sys import getsizeof
s1 = 'working out'
s2 = 'memory usage for'
s3 = 'strings in python is fun!'
for s in [s1, s2, s3]:
print(getsizeof(s))
obj_series = pd.Series(['working out',
'memory usage for',
'strings in python is fun!'])
obj_series.apply(getsizeof)
We can see that the size of strings when stored in a pandas series are identical to their usage as separate strings in Python. This limitation causes strings to be stored in a fragmented way that consumes more memory and is slower to access. Each element in an object column is really a pointer that contains the "address" for the actual value's location in memory. For more information about this part consider referring to the following link. Blog: Why Python is Slow: Looking Under the Hood
To overcome this problem, Pandas introduced Categoricals in version 0.15. The category type uses integer values under the hood to represent the values in a column, rather than the raw values. Pandas uses a separate mapping dictionary that maps the integer values to the raw ones. This arrangement is useful whenever a column contains a limited set of values. When we convert a column to the category dtype, pandas uses the most space efficient int subtype that can represent all of the unique values in a column.
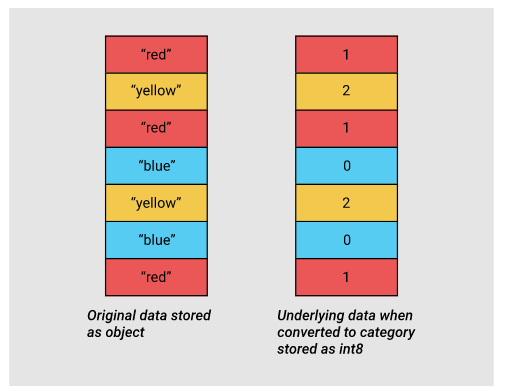
Since the country and continent columns are strings, they are represented as object types in pandas. Now let's say, instead of storing strings, we want to store the continent column as integers to reduce the memory required to store them by converting it to categorical type. To apply this conversion, we simply have to convert the column type to category using the .astype method.
# convert and print the memory usage
continent_col = 'continent'
continent = drinks[continent_col]
continent_cat = drinks[continent_col].astype('category')
print(continent.head())
print(continent_cat.head())
# drinks.memory_usage(deep = True)
As we can see, apart from the fact that the type of the column has changed, the data looks exactly the same. Pandas internals will smooth out the user experience so we don’t notice that we’re actually using a compact array of integers.
Let’s take a look at what's happening under the hood. In the following code chunk, we use the Series.cat.codes attribute to return the integer values the category type uses to represent each value.
# this is simply showing the first 5 row)
continent_cat.cat.codes[:5]
This column doesn’t have any missing values, but if it did, the category subtype handles missing values by setting them to -1.
We can also access the unique categories using the Series.cat.categories attribute. This information servers as the lookup table that stores the mappings of the integer representation to the original category.
continent_cat.cat.categories
Lastly, let’s look at the memory usage for this column before and after converting to the category type.
print('original: ', mem_usage(continent))
print('categorical: ', mem_usage(continent_cat))
We can see that by converting the continent column to integers we're being more space-efficient. Apart from that it can actually speed up laters operations, e.g. sorting, groupby as we're storing the strings as compactly as integers. Let's apply this notion again to the country column.
country_col = 'country'
country = drinks[country_col]
country_cat = drinks[country_col].astype('category')
print('original: ', mem_usage(country))
print('categorical: ', mem_usage(country_cat))
This time, the memory usage for the country column is now larger. The reason is that the country column's value is unique. If all of the values in a column are unique, the category type will end up using more memory because the column is storing all of the raw string values in addition to the integer category codes.
Thus we're actually creating 193 (shown below) unqiue categories, and we also have to store a lookup table for that.
country_cat.cat.categories.size
In summary, if we're working with an object column of strings, convert it to category type to make it for efficient. But this must be based on the assumption that the column takes a limited number of unique values, like in this case, the continent column only has 6 unique values.
Selecting Types While Reading the Data In¶
So far, we've explored ways to reduce the memory footprint of an existing dataframe. By reading the dataframe in first and then iterating on ways to save memory, we were able to understand the amount of memory we can expect to save from each optimization better. As we mentioned earlier in the mission, however, we often won't have enough memory to represent all the values in a data set. How can we apply memory-saving techniques when we can't even create the dataframe in the first place?
Fortunately, we can specify the optimal column types when we read the data set in. The pandas.read_csv() function has a few different parameters that allow us to do this. The dtype parameter accepts a dictionary that has (string) column names as the keys and numpy type objects as the values.
col_types = {'beer_servings': 'uint32',
'continent': 'category',
'country': 'object',
'spirit_servings': 'uint32',
'total_litres_of_pure_alcohol': 'float32',
'wine_servings': 'uint32'}
# we can see that the column's memory usage is significantly
# smaller than before (the DataFrame at the beginning)
df_drinks = pd.read_csv('http://bit.ly/drinksbycountry', dtype=col_types)
df_drinks.memory_usage(deep=True)
Or instead of manually specifying the type, we can leverage a function to automatically perform the memory reduction for us.
def reduce_mem_usage(df, blacklist_cols=None):
"""
Iterate through all the columns of the dataframe and downcast the
data type to reduce memory usage.
The logic is numeric type will be downcast to the smallest possible
numeric type. e.g. if an int column's value ranges from 1 - 8, then it
fits into an int8 type, and will be downcast to int8.
And object type will be converted to categorical type.
Parameters
----------
df : pd.DataFrame
Dataframe prior the memory reduction.
blacklist_cols : collection[str], e.g. list[str], set[str]
A collection of column names that won't go through the memory
reduction process.
Returns
-------
df : pd.DataFrame
Dataframe post memory reduction.
References
----------
https://www.kaggle.com/gemartin/load-data-reduce-memory-usage
"""
start_mem = compute_df_total_mem(df)
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
blacklist_cols = blacklist_cols if blacklist_cols else set()
for col in df.columns:
if col in blacklist_cols:
continue
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
else:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = compute_df_total_mem(df)
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
def compute_df_total_mem(df):
"""Returns a dataframe's total memory usage in MB."""
return df.memory_usage(deep=True).sum() / 1024 ** 2
df_drinks = pd.read_csv('http://bit.ly/drinksbycountry')
df_drinks = reduce_mem_usage(df_drinks, blacklist_cols=['country'])
df_drinks.memory_usage(deep=True)
The idea is that after performing the memory reduction, we should save this dataframe back to disk so in the future, we won't have to go through this process every time. (Assuming we'll be reading this data again and again).
Ordered Categorical¶
Another usage of category is to specify its order to perform sorting.
# toy dataset that contains
# the id for a product and
# its corresponding customer review
df = pd.DataFrame({
'ID': [100, 101, 102, 103],
'quality': ['good', 'very good', 'good', 'excellent']
})
df
# if we do a sort on quality, it will be
# sorted alphabetically (default sorting for strings)
df.sort_values('quality')
# we can use an instance of CategoricalDtype to specify our own ordering
cat_dtype = pd.api.types.CategoricalDtype(
categories=['good', 'very good', 'excellent'], ordered=True)
df['quality'] = df['quality'].astype(cat_dtype)
df.sort_values('quality')
# we can even use boolean method on this new ordering
df.loc[df['quality'] > 'good']