# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(plot_style=False)
os.chdir(path)
# magic to print version
%load_ext watermark
%watermark -a 'Ethen' -d -u -v
Understanding Iterables, Iterators and Generators¶
Iterables, Iterators¶
Let's begin by looking at a simple for loop.
x = [1, 2, 3]
for element in x:
print(element)
It functions as expected. Our code prints the number 1, 2, 3 and then terminates. In this document, we'll dive deeper into what's happening behind the scenes. i.e. How does the loop construct fetch individual elements from object it's looping over and determine when to stop?
The short answer to this question is Python's iterator protocol:
Objects that support iter and next dunder methods automatically work with for-in loops.
Let's first introduce some terminologies.
- An iterator is:
- Object which defines a
__next__method and will produce the next value when we callnext()on it. If there are no more items, it raisesStopIterationexception. - Object that is self-iterable (meaning that it has an iter method that returns self).
- Object which defines a
- An iterable is anything that can be looped over. It either:
- Has an
__iter__method which returns an iterator for that object when you call iter() on it, or implicitly in a for loop. - Defines a
__getitem__method that can take sequential indexes starting from zero (and raises an IndexError when the indexes are no longer valid)
- Has an
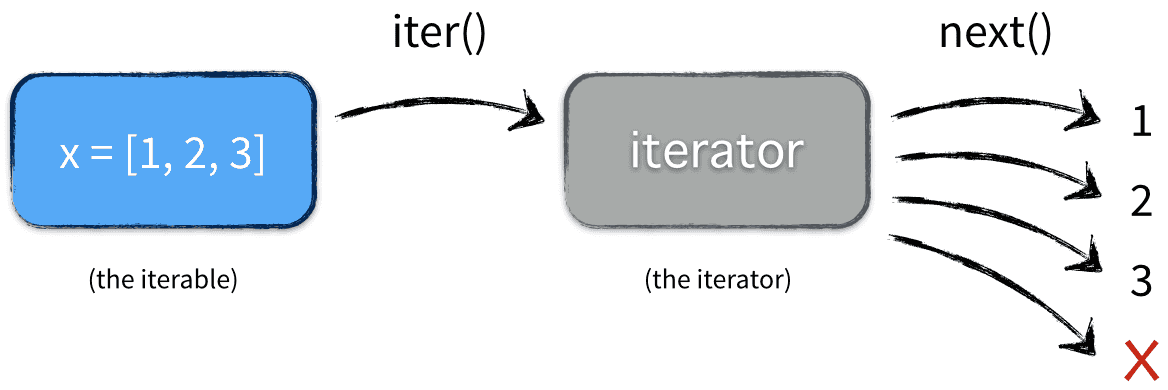
Don't worry if it's a bit abstract at first glance. It will becomes much clearer as we work through a couple of examples. When Python sees a statement like for obj in object it will first call iter(object) to make it a iterator.
# the built-in function iter takes an
# iterable object and returns an iterator
iterator = iter(x)
# here x is the iterable
print(type(x))
print(type(iterator))
Then we can loop through all available elements using next built-in function.
# each time we call the next method on the iterator,
# it will give us the next element
print(next(iterator))
print(next(iterator))
print(next(iterator))
But notice what happens if we call next on the iterator again.
# if there are no more elements in the iterator,
# it raises a StopIteration exception
try:
print(next(iterator))
except StopIteration as e:
print('StopIteration raised')
It raises a StopIteration exception to signal we've exhausted all available values in the iterator. Based on this experiment, we now know iterators use exceptions to structure control flow. To signal the end of iteration, a Python iterator raises the built-in StopIteration exception. To sum it up, when we write:
x = [1, 2, 3]
for element in x:
...
This is what's actually happening under the hood:
Now, let's dive deeper. We'll implement a class that enables us to prints a value for some maximum number of times and use it in a for obj in object loop.
- When we invoke
iterfunction on our object, it effectively translates to calling.__iter__()dunder method which returns the iterator object. - Subsequent loop will iteratively call the iterator object's
__next__method to fetch values from it. - For practical reasons, iterable class can implement both
__iter__()and__next__()in the same class, and have__iter__()return self. This makes the class both an iterable and its own iterator. However, it is perfectly valid to return a different object as the iterator.
class Repeat:
def __init__(self, value, max_repeats):
self.value = value
self.max_repeats = max_repeats
self._count = 0
def __iter__(self):
# simply return the iterator object, since
# all that matters is that __iter__ returns a
# object with a __next__ method, which we
# will implement below
return self
def __next__(self):
# implement the stopping criterion
if self._count >= self.max_repeats:
raise StopIteration
self._count += 1
# simply returns the same value after iteration
return self.value
repeater = Repeat(value='Hello', max_repeats=3)
for item in repeater:
print(item)
This implementation gives us the desired result. Iteration stops after max_repeats is met. This mental model will seem familiar to readers that have worked with database cursors: We first initialize the cursor and prepare it for reading, then we can fetch our data into local variables as needed from it, one element at a time. Because there will never be more than one element in memory, this approach is highly memory-efficient.
Note that we can also take this class and implement it using the iter and next function way.
repeater = Repeat(value='Hello', max_repeats=3)
iterator = iter(repeater)
while True:
try:
item = next(iterator)
except StopIteration:
break
print(item)
But as we can see being able to write a three-line for-in loop instead of an eight lines long while loop is quite a nice improvement. It makes the code easier to read and more maintainable. And this is the reason why iterators in Python are such a powerful tool.
Generators¶
A generator is an object that lazily produces values, i.e. generates values on demand. It can be either:
- A function that incorporates the
yieldkeyword (yield expression).- When called, it does not execute immediately, but returns a generator object.
- Upon involing
next()method on the function, it starts the actual execution. Once this function encounters theyieldkeyword, it pauses execution at that point, saves its context and returns its value to the caller - Subsequent calls to
next()resume execution until another yield is encountered or end of function is reached.
- A generator expression, which is syntactic construct for creating an anonymous generator object. These are like list comprehensions but enclosed in
()instead of[].
# generator expression:
# note that unlike list comprehension;
# the elements are lazily evaluated, i.e. they
# take up less memory since they are not created
# all at once, but instead return one element at
# a time whenever needed
nloop = 3
# The generator object is now created, ready to
# be iterated over
generator = (x ** 2 for x in range(nloop))
# the real processing happens during the iteration
for value in generator:
print(value)
# generator function:
def gen(nloop):
for x in range(nloop):
yield x ** 2
generator = gen(nloop)
for value in generator:
print(value)
One important thing to note about generator is that it only produces the result a single time. In other words, once we're done iterating through our generator for the first time, we won't get any results the second time around when we iterate over an already-exhausted generator.
# no results
for value in generator:
print(value)
This is something that's extremely important to keep in mind when working with generators. If we wish to iterate over its content for more than once, we can always make a copy by converting it to a list.
# we can now loop through it for more than once
iterable = list(gen(nloop))
for value in iterable:
print(value)
for value in iterable:
print(value)
This approach solves the problem, but to understand why this is not always ideal. We need to step back and understand the rationale behind using generators.
The real advantage or true power of using generator is it gives us the ability to iterate over sequence lazily, which in turn reduces memory usage. For example, imagine a simulator producing gigabytes of data per second. Clearly we can't put everything neatly into a Python list first and then start munching, since this copy could cause our program to run out of memory and crash. Ideally, we must process the information as it comes in. The recommended way to deal with this, is to have a class that implements the __iter__ dunder method.
class Gen:
def __init__(self, nloop):
self.nloop = nloop
def __iter__(self):
# the method will create a iterator object
# every time it is looped over, or technically
# every time this __iter__ method is called, such
# as when the object hits a for loop
for x in range(self.nloop):
yield x ** 2
iterable = Gen(nloop = nloop)
for value in iterable:
print(value)
for value in iterable:
print(value)
This type of streaming approach is used a lot in the Gensim library. e.g. with helper class such as LineSetence we can feed chunks/batches of documents into the memory to train the model instead of having to load the entire corpus into memory.
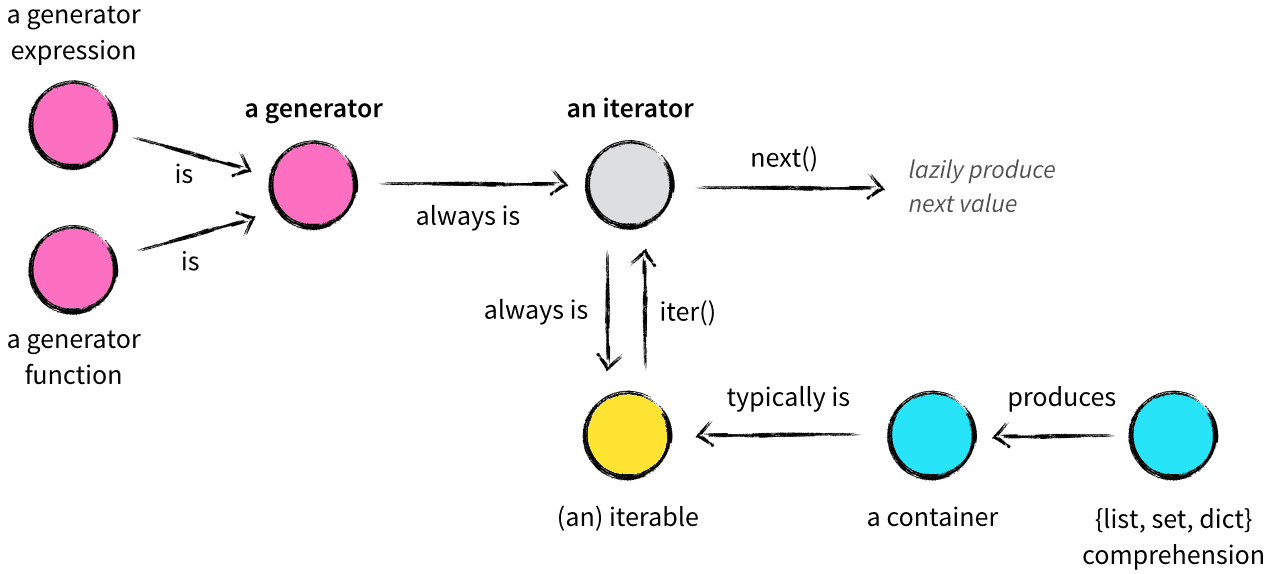
To wrap up, the following diagram summarizes the relationship between iterable, iterator and generator.