# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format='retina'
import os
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from subprocess import call
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
%watermark -a 'Ethen' -d -t -v -p numpy,pandas,sklearn,matplotlib
Technical Skills Tips and Tricks¶
In machine learning, there are many ways to build a solution and each way assumes something different. Many times, it's not obvious how to navigate and identify which assumptions are reasonable. Hopefully, you will learn something from these tips and create a more robust solution.
Taking the default loss function for granted¶
When evaluating binary classification algorithm, area under the curve is a great default to start with, but when it comes to real world applications this off-the-shelf loss function is rarely optimum for the business problem we're trying to solve for.
Take for example, fraud detection. In order to align business objectives what we might want is to penalize false negatives in proportion to the dollar amount lost due to fraud. Using area under the curve might give us a decent result, but it probably won't give us the best result.
Using the same algorithm/method for all problems¶
Many will use the algorithm/method that they are the most comfortable/familiar with on every use case they can imagine. This might lead to poor results due to bad assumptions.
Ideally, once we have preprocessed our data, we should feed it into many different models and see what the results are. After that, we will have a good idea of what models work best and what models don't work so well. Of course based on experience, we've might realized some methods just works well or just don't work well with some types of problems. e.g. Support Vector Machine is extremely powerful in text classification (high-dimensional dataset).
Ignoring outliers¶
Outliers can be important or completely ignored, just based on context. Take for example, pollution forecasting. Large spikes in air pollution can occur and it's a good idea to look at them and understand why they occurred. In the case of outliers caused by some type of sensor error, it's safe to ignore them and remove them from the dataset.
From a model perspective, some are more sensitive to outliers than others. e.g. For gradient boosted trees, it might try to mitigate making errors on those outliers and put unneccessary amount of focus on them, whereas a vanilla decision tree might just treat the outlier as a misclassification.
Not properly dealing with cyclical features¶
Hours of the day, days of the week, months in a year and wind directions are all example of features that are cyclical. Many won't think of converting these type of features into representation that can preserve information such as hour 23 and hour 0 should be close to each other.
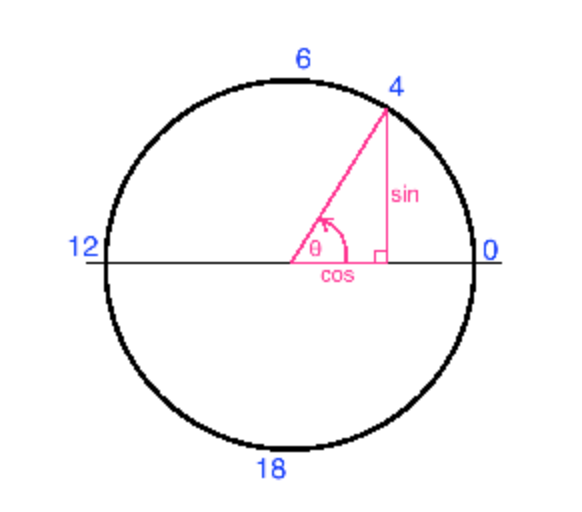
Sticking to the hour example, the best way to handle this is to calculate the sin and cos component so that we represent our cyclical feature as (x,y) coordinates of a circle. In this representation hour, 23 and hour 0 are right next to each other numerically, just as they should be.
In the following section, we will explore this feature engineering approach on the bike sharing dataset to see if it actually improves the performance of the model. The goal is to predict how many bikes are being used at an given hour
data_dir = 'bike_sharing'
if not os.path.isdir(data_dir):
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip'
call('curl -O ' + url, shell=True)
call('mkdir ' + data_dir, shell=True)
call('unzip Bike-Sharing-Dataset.zip -d ' + data_dir, shell=True)
data_path = os.path.join(data_dir, 'hour.csv')
df = pd.read_csv(data_path)
print('dimension:', df.shape)
df.head()
There are a bunch of features in here that are likely valuable to predict cnt, the count of users riding bikes (the sum of "casual" riders and "registered" riders). Here we'll just focus on the cyclical features: mnth (month) and hr (hour).
The next section is where the magic happens. We map each cyclical feature onto a circle such that the lowest value for that feature appears right next to the largest value. We compute the x and y component of that point using sin and cos trigonometric functions. Here's what it looks like for the "hours" variable. Zero (midnight) is on the right, and the hours increase counterclockwise around the circle. In the end, 23:59 is very close to 00:00, as it should be.
We can apply similar transformation for the "month" variable, one extra step is that we also shift the values down by one such that it ranges from 0 to 11, this step is only for convenience.
# Now instead of hours ranging from 0 to 23,
# we have two new features "hr_sin" and "hr_cos" which
# each ranges from 0 to 1, and we'll use these two features
# as inputs to our model as oppose to the raw form
hour_col = 'hr'
df['hr_sin'] = np.sin(df[hour_col] * (2. * np.pi / 24))
df['hr_cos'] = np.cos(df[hour_col] * (2. * np.pi / 24))
month_col = 'mnth'
df['mnth_sin'] = np.sin((df[month_col] - 1) * (2. * np.pi / 12))
df['mnth_cos'] = np.cos((df[month_col] - 1) * (2. * np.pi / 12))
plt.scatter(df['hr_sin'], df['hr_cos'])
plt.show()

The claim is that the transformed features should improve the performance of our model, let's give it a shot. We'll use a model pipeline that consists of standardizing the numeric features and feeding those features into a Linear Regression. We'll use a 10-fold cross validation and report the negative mean squared error.
# model pipeline
standardize = StandardScaler()
linear = LinearRegression()
pipeline = Pipeline([
('standardize', standardize),
('linear', linear)])
# input features and labels
label_col = 'cnt'
input_cols = ['mnth', 'hr']
y = df[label_col].values
X = df[input_cols].astype(np.float64)
# sklearn's LinearRegression may give harmless errors
# https://github.com/scipy/scipy/issues/5998
warnings.filterwarnings(
action='ignore', module='scipy', message='^internal gelsd')
cv = 10
scoring = 'neg_mean_squared_error'
results = cross_val_score(pipeline, X, y, cv=cv, scoring=scoring)
print('CV Scoring Result: mean =', np.mean(results), 'std =', np.std(results))
input_cols = ['mnth_sin', 'mnth_cos', 'hr_sin', 'hr_cos']
X = df[input_cols].values
# negative mean squared error, the closer the value is to 0, the better
results = cross_val_score(pipeline, X, y, cv=cv, scoring=scoring)
print('CV Scoring Result: mean =', np.mean(results), 'std =', np.std(results))
By taking this extra feature engineering step of transforming the month and hour feature into a more representative form, our model had an easier time learning the underlying relationship, which resulted in an increase in model performance.
L1/L2 regularization without standardizing features¶
Using regularization methods such L1 and L2 regularizations is a common way to prevent models from overfitting, however, keep in mind that it is important to standardize the features and put them on equal footing before applying this technique.
Misinterpreting feature importance¶
Tree-based models or linear models are commonly used algorithms as they have the capability of giving us feature importance or coefficients without having to rely on other external methods. When intrepreting these result, there are a couple of caveats to keep in mind.
- If the features are co-linear, the importance can shift from one feature to another. The more features the data set has the more likely the features are co-linear and the less reliable simple interpretations of feature importance are. Thus it is recommended to remove multicollinearity before feeding the data into our model.
- Linear model such as linear and logistic regression outputs coefficients. Many times these coefficients will cause people to believe that the bigger the value of the coefficient, the more important the feature is. Not that this is wrong, but we need to make sure that we standardized our dataset beforehand as the scale of the variable will change the absolute value of the coefficient.
Take Away:
- Always build a custom loss function that closely matches your solution objectives.
- If we use the same algorithm over and over again we might not be getting the best results that it can.
- Always look at the data closely before we start our work and determine if outliers should be ignored or looked at more closely.
- If we have cyclical features, we should convert them to take advantage of the cyclical pattern.
- Regularization is great but can cause headaches if we don't have standardized features.
- Understanding what features are most essential to a result is important, but do make sure to not misinterpret them.
Just like with any projects/industries, the devil is in the details, and even fancy plots can hide bias and error. In order to achieve good result, it's important to double-check our process to ensure we're not making some common errors.
Soft Skills Tips and Tricks¶
Important questions to ask¶
What are the Key Performance Indicators (KPI) in this domain?¶
As a data scientist in an organization, the sooner we understand how people on our team's work is measured against, the better. This helps us understand project prioritization and we need to be able to show.
What are the relevant/classic case studies in this domain?¶
The industry, the organization, and our team has faced issues in the past that have been resolved or studied. There is a set of working knowledge that people in the group, company, and other companies will have about what worked and what didn't. Yes, we may be applying new techniques or using new frameworks, but it will all be flavored by what has been done in the past. This means that we should try and get the historical context to not only helps us understand decisions managers and senior members of the team will make, but also hone our personal approach to data science problems.
Who are the industry thought leaders (internal & external)?¶
Within industries and organizations there are thought leaders who are driving the agenda, experiments, knowledge, and how to think about what is going on within the small world they inhabit and lead. Every group and organization will have different people they inherently trust and listen to. We should know who they are, try to familiarize ourselves with their work, and become conversant in their viewpoints, world views, and recommendations. This will help us better understand how the team and organization learns about cutting edge techniques and applications, as well as gives us a natural topic to talk about. This will also help us stay on top of industry news, gossip, firings, hirings, and the softer-side of the industry.
Mentality to have¶
Help the business first¶
Stacking outputs as features to go for the best models is not exactly what we are paid for. Instead we should aim for generating a actionable solution or get get a minimum viable product first. This does not mean we shouldn't work on improving the model, it's simply saying premature optimization is the root of all evil. When starting a project aim for the low hanging fruit first, there will come a time to improve our models or add complexity as needed.
As a side note, from time to time, our business partner might be asking for a very small data pull. Don't ignore these requests and think that they are trivial since they might be able to provide the necessary insights to aid the business. When given such data request, make sure they support a decision and that decision will improve the business if it has the data – and when they do, swallow the pride and run those 30 lines of SQL query.
Always be learning but don't fall for the hype¶
Deep learning ..., Distributed systems ... Sometimes we will not need all the fancy stuff that we've learned and it will be a distraction. Use familiar tools and if it ain't broken don't fix it. Consider that using any project younger than a few year may result in unavoidable pains (breaking APIs, bugs). Allow ourselves only a couple of new pieces of technology per work project. This is not saying that we can't work or keep up with the new and cool stuff. After all we should constantly be open to learning new knowledge. This is just reminding us, don't use the state-of-art tool because it's state-of-art, use it because it's required to solve to problem at hand. Another way to put it is: be boring until you can't.
Regarding this topic, the blog post at the following link might be worth a read. Blog: No, you don't need ML/AI. You need SQL
Talk & Learn from colleagues¶
Already mentioned in the important questions to ask section. Learn from software engineers. Chances are they know more about best practices, tooling and devops than we do as a data scientist. Learn from non-technical peers. They know how we can help them from a business perspective, may understand the data much better and will recognize data quality issues faster than we will. Our feature engineering work will benefit a lot from their insight. Talk to our peers. Learn about the history of projects started by our colleagues. Ask about issues they encountered along the way. Try to take different paths or revisit them. When working on the project, it is also nice to look for peer reviews. Peer reviewer can provide feedbacks from a different standpoint, suggest better approaches and better sanity-checks than the consumers of our project can.
Educate our consumers¶
Communication is key as we will often be presenting our analysis and results to people who are not data experts. Part of our job is to educate them on how to interpret and draw conclusions from our analysis data. This is especially important when the analysis has a high risk of being misinterpreted. We are responsible for providing the context and a full picture of the analysis and not just the number a consumer asked for.
Be skeptical and check for reproducibility¶
As we work with the data, we must be a skeptic of the insights that we are gaining. When we have an interesting phenomenon we should ask both "What other data could I gather to validate how awesome this is?" or "What could I find that would invalidate this phenomenon?". If we are building models of the data, you want those models to be stable across small perturbations in the underlying data. Using different time ranges or random sub-samples of our data will tell us how reliable/reproducible this model is. And speaking of reproducibility, leaving "paper trails" and making it easy for other people (including the future you) to reproduce the work are extremely important.
Expect and accept ignorance and mistakes¶
There are many limits to what we can learn from data and mistakes can still occur. Admitting our mistake is a strength but it is not usually immediately rewarded. But proactively owning up to our mistakes will translate into credibility and will ultimately earn us respect with colleagues and leaders who are data-wise.
Notes Worth Reading¶
Paper: P. Domingos A few useful things to know about machine learning (2012): Like any discipline, machine learning has a lot of "folk wisdom" that can be hard to come by, but is crucial for success. This article summarized some of the most salient items.
e.g. It's generalization that counts: The most common mistake among machine learning beginners is to test on the training data and have the illusion of success. Remember, if we are hired to build a predictive model, be sure to set some data aside from the beginning, and only use it to test the model at the very end, followed by learning the model on the full dataset. The following links also talks about this topic. [Blog: How (and why) to create a good validation set][Blog: Do You Re-train on the Whole Dataset After Validating the Model?]
Blog: The Ten Fallacies of Data Science: includes some gotchas to look out for when starting a data science project in the real world. e.g. double check to make sure relevant data is accessible, relatively consistent before agreeing to specific deadlines for the completion of the analysis.
Slideshare: Feature Engineering: Contains lots of feature engineering ideas that are worth knowing/trying. Applied machine learning is basically feature engineering, as we all probably heard of the saying "more data beats clever algorithms, but better data beats more data".
Notes: Rules of Machine Learning: Best Practices for ML Engineering: Extracted from the notes' overview section.
To make great product, do machine learning like the great engineer you are not like the great machine learning expert you aren't
In the applied machine learning field, most of the problem that we will face, are in fact, engineering problems. Even with all of the open source machine learning toolkit at our disposable, often times great gains comes from encorporating great features not great machine learning algorithms. So the basic approach is:
- make sure our pipeline is solid end to end
- start with a reasonable objective
- add common-sense features
- make sure our pipeline stays update to date
This approach will make a lot of people happy for a long period of time. Diverge from this approach and start looking into cutting-edge machine learning only when there are no more simple tricks to get us further.
Blog: Lessons on How to Lie with Statistics: Advice on how to be data literate & a responsible data producer and consumer.
- View Correlations with Skepticism. Always check for confounding variables.
- Relationships Don’t Last Forever. When we identify a relationship, don't assume it lasts forever be it in the positive or negative direction.
- Always look at the axes on the chart. The trend might not be as big as we think if we examine the chart closely.
- Small Samples Produce Shocking Statistics. The smaller the sample size, the more extreme the values. Always look out for sample size when reading summary statistics.
- Look at all the Numbers that Describe a Dataset. Looking at the whole distribution will lead to a clearer picture as a single number such as average should be complemented by ranges/standard errors/quantiles to provide a holistic view.
- Use Comparisons to a Common Baseline. It's usually comparison that matters, don't let a single/isolated number sway our rational thinking.
- Look for Bias in Sample Selection. Is the sample representative of the population that we're interested in.
- Be Wary of "Big Names" on Studies and Scrutinize Authority. A fun alternative way of phrasing this is: "In god we trust, all others must bring data", a study with a big name attached should get as much scrutiny as others.