# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
import os
import torch
import evaluate
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
from time import perf_counter
from torch.utils.data import DataLoader
from datasets import load_dataset, DatasetDict, disable_progress_bar
from datasets.utils.logging import set_verbosity_error
from transformers import (
pipeline,
Trainer,
TrainingArguments,
AutoConfig,
AutoTokenizer,
AutoModelForSequenceClassification,
DataCollatorWithPadding
)
device = "cuda" if torch.cuda.is_available() else "cpu"
# prevent dataset from floading outputs to our notebook
disable_progress_bar()
set_verbosity_error()
%watermark -a 'Ethen' -d -u -v -p torch,datasets,transformers,evaluate,numpy,pandas
Response Knowledge Distillation¶
In this documentation, we'll deep dive into a technique called knowledge distillation that's commonly used to compress large model, a.k.a. teacher model, into a smaller model, a.k.a student model. The hope is that these student models, which typically have fewer layers or/and fewer neurons per layer will be capable of reproducing the behavior of teacher models while being more light weight. In other words, making the model more cost efficient when it comes to serving in production setting without lossing too much performance. And just to clarify, as knowledge distillation is a broad topic, there are two primary types of knowledge distillation, task-specific knowledge distillation (left) and task-agnostic knowledge distillation (right). Here, our primary focus will be the former.
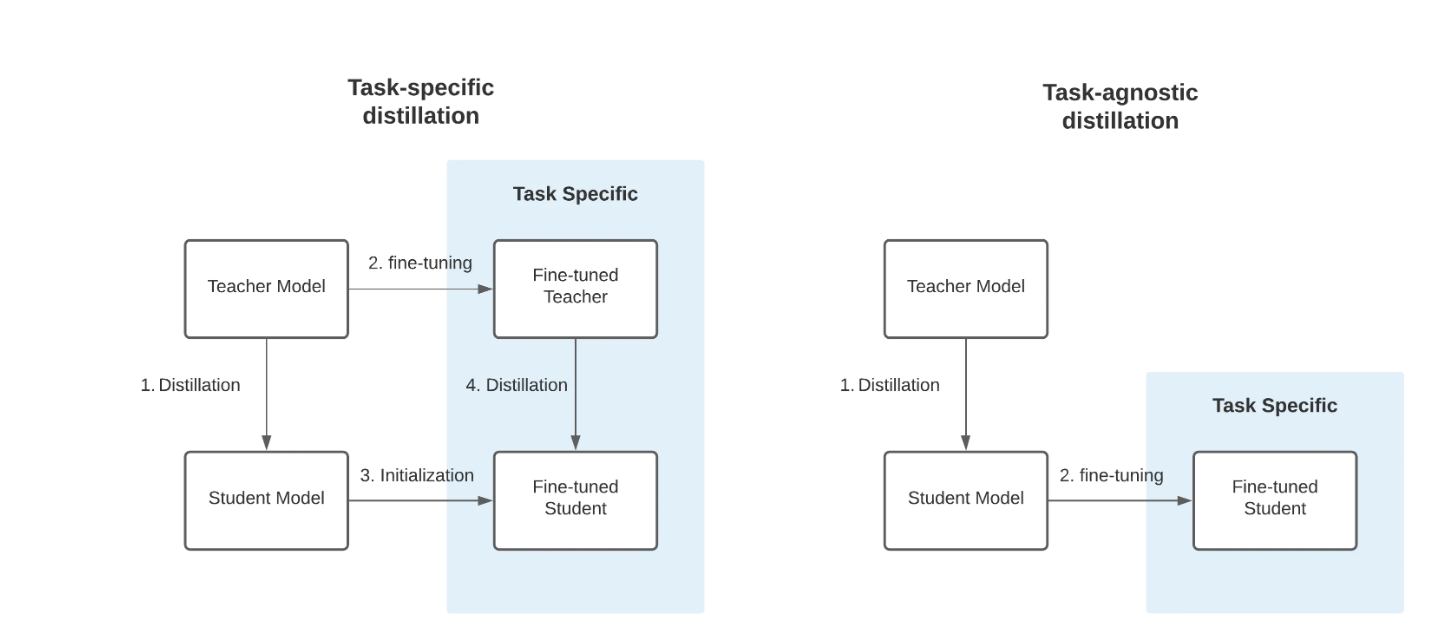
Task specific response knowledge distillation involves optimizing a weighted combination of two objective functions
\begin{align} L = \alpha L_{CE} + (1 - \alpha) L_{KD} \text{, where } \alpha \in [0, 1] \end{align}$L_{CE}$ is the cross entropy loss between the student logit $z_s$ and our one hot encoded ground truth labels $y$:
\begin{align} L_{CE} = - \sum^c_{j=1}y_j \text{log} \sigma_j(z_s, 1) \end{align}Where $\sigma_i$ is our softmax output that takes the model's logit, $z$ ($z_t$ stands for teacher model's logit, whereas $z_s$ stands for student model's logit), as well as a temperature scaling parameter, $T$, as its inputs. $\sigma_i = \frac{exp\left(z_i / T \right)}{\sum_{j} \exp\left(z_j / T \right)}$. Here, the temperature parameter for softmax function is 1, which makes this the standard loss function that we generally optimize towards in supervised classification settings.
$L_{KD}$ For knowledge distillation loss part, we are essentially add a KL-divergence loss between teacher model's response with student model's response. By adding this loss function, we are training our student model so it will become better at mimicking similar predictions as the teacher.
\begin{align} L_{KD} = - T^2 \sum^c_{j=1}\sigma_j(z_t, T) \text{log} \frac{\sigma_j(z_t, T)}{\sigma_j(z_s, T)} \end{align}The idea behind temperature scaling is that teacher model tend to assign extremely high predicted scores to the true class, as such it doesn't provide too much additional information beyond what dataset's ground truth label was already provided. To tackle this issue, temperature scaling acts as a scaling parameter to "soften" our predictions. The intuition behind this it allows us to learn "ish" concepts in our data, e.g. we have a 1-ish 7 (a 7 that looks like a 1, or more formally, although our model predicted 7 with the highest score, it still assign some amount of score to 1). Note:
- When a student model is a lot smaller than a teacher model, we tend to keep a smaller temperature. Because as we raise this temperature parameter, the resulting predicted distribution may start to contain too much "knowledge" for the student to capture effectively.
- Once our student model has been trained, temperature parameter $T$, is set back to 1 during inferencing stage.
- There's a multiplication term $T^2$, in our knowledge distillation loss. Since magnitudes of the gradients produced by soft targets scale as $1/T^2$. It's important to add a multiplication term back to ensure contribution from the ground truth hard target and the teacher's predicted soft target remains roughly equal.
As we can see, the main idea behind response knowledge distillation is that while training our student model, instead of solely optimizing for our task's original loss function using dataset's ground truth label (e.g. in classification task this may be cross entropy loss), we will augment it with the teacher model's predicted output probability. In our loss function we will have a parameter $\alpha$ that controls weighting between the two loss function.
Data Preprocessing¶
For this example, we will be using qqp (Quora Question Pairs2) text classification task from the glue benchmark. These are collection of question pairs from the community question-answering website Quora. Our task is to determine whether a pair of questions are semantically equivalent.
dataset_dict = load_dataset('glue', 'qqp')
dataset_dict
example = dataset_dict['train'][3]
example
Teacher Model¶
To establish our baseline, we'll piggyback on one of the pretrained models available from huggingface hub. In this case, we'll pick a teacher model that is already trained on our targeted dataset.
teacher_checkpoint = 'textattack/bert-base-uncased-QQP'
teacher_tokenizer = AutoTokenizer.from_pretrained(teacher_checkpoint)
teacher_model = AutoModelForSequenceClassification.from_pretrained(teacher_checkpoint).to(device)
print('# of parameters: ', teacher_model.num_parameters())
We generate a sample prediction using our tokenizer and model. Double confirming our result matches with the pipeline wrapper class.
tokenized = teacher_tokenizer(
example['question1'],
example['question2'],
return_tensors='pt'
).to(teacher_model.device)
tokenized
teacher_model.eval()
with torch.no_grad():
output = teacher_model(**tokenized)
batch_scores = F.softmax(output.logits, dim=-1)
batch_scores
classifier = pipeline("text-classification", model=teacher_checkpoint, device=teacher_model.device)
output = classifier({"text": example['question1'], "text_pair": example['question2']})
output
Student Model¶
As always, we are free to choose different student models and compare results, though as a general principle, we typically avoid distilling different model family against each other, as different inputs/tokens will result in different embeddings, and knowledge transfering different spaces tend to not work well.
In the next code chunk, apart from the typically step of initiating our student model using .from_pretrained method, we also copy some additional config such as number of labels as well as label id to label name mapping from the teacher model's config.
student_checkpoint = 'distilbert-base-uncased'
student_tokenizer = AutoTokenizer.from_pretrained(student_checkpoint)
student_config = AutoConfig.from_pretrained(
student_checkpoint,
num_labels=teacher_model.config.num_labels,
id2label=teacher_model.config.id2label,
label2id=teacher_model.config.label2id
)
def student_model_init():
student_model = AutoModelForSequenceClassification.from_pretrained(
student_checkpoint,
config=student_config
).to(device)
return student_model
student_model = student_model_init()
print('# of parameters: ', student_model.num_parameters())
def tokenize_dataset(dataset, tokenizer):
def tokenize_fn(batch):
return tokenizer(batch["question1"], batch["question2"], truncation=True)
return dataset.map(
tokenize_fn,
batched=True,
num_proc=8,
remove_columns=["question1", "question2", "idx"]
)
dataset_dict_student_tokenized = tokenize_dataset(dataset_dict, student_tokenizer)
dataset_dict_student_tokenized['train'][0]
For model performance, we'll compute some of the standard text classification metrics, Huggingface evaluate allows us to combine multiple metric's calculation in one go using the .combine method. As roc_auc expects a different input (it requires the predicted score instead of predicted labels) compared to f1, precision, recall, we load it separately.
clf_metrics = evaluate.combine(["f1", "precision", "recall"])
roc_auc_metric = evaluate.load("roc_auc")
results = clf_metrics.compute(predictions=[0, 1], references=[0, 1])
print(results)
def compute_metrics(pred):
scores, labels = pred
predictions = np.argmax(scores, axis=1)
metrics = clf_metrics.compute(predictions=predictions, references=labels)
metrics['roc_auc'] = roc_auc_metric.compute(prediction_scores=scores[:, 1], references=labels)['roc_auc']
return metrics
In the next few code chunk, we'll first train a student model with and without knowledge distillation for comparison.
batch_size = 64
num_train_epochs = 2
learning_rate = 0.0001
weight_decay = 0.01
student_finetuned_checkpoint = "distilbert-base-uncased-finetuned-qqp"
student_training_args = TrainingArguments(
output_dir=student_finetuned_checkpoint,
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=weight_decay,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True
)
student_trainer = Trainer(
model_init=student_model_init,
args=student_training_args,
tokenizer=student_tokenizer,
train_dataset=dataset_dict_student_tokenized["train"],
eval_dataset=dataset_dict_student_tokenized["validation"],
compute_metrics=compute_metrics
)
student_trainer.train()
In order for us to finetune a model using knowledge distillation, we will subclass the TrainingArguments to include our two hyperparameters, $\alpha$ and $T$, as well as Trainer to mainly overwrite its compute_loss method so we can add our knowledge distillation loss term.
class DistillationTrainingArguments(TrainingArguments):
def __init__(self, *args, alpha=0.5, temperature=1.5, **kwargs):
super().__init__(*args, **kwargs)
self.alpha = alpha
self.temperature = temperature
class DistillationTrainer(Trainer):
def __init__(self, *args, teacher_model=None, **kwargs):
super().__init__(*args, **kwargs)
self.teacher = teacher_model
# place teacher on same device as student
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
self.kl_div_loss = nn.KLDivLoss(reduction="batchmean")
def compute_loss(self, model, inputs, return_outputs=False):
# compute student and teacher output
outputs_student = model(**inputs)
with torch.no_grad():
outputs_teacher = self.teacher(**inputs)
# Soften probabilities and compute distillation loss
# note, the kl divergence loss expects the input to be in log-space
# https://pytorch.org/docs/stable/generated/torch.nn.KLDivLoss.html
distillation_loss = self.kl_div_loss(
F.log_softmax(outputs_student.logits / self.args.temperature, dim=-1),
F.softmax(outputs_teacher.logits / self.args.temperature, dim=-1)
) * (self.args.temperature ** 2)
# Return weighted student loss
loss = self.args.alpha * outputs_student.loss + (1. - self.args.alpha) * distillation_loss
return (loss, outputs_student) if return_outputs else loss
student_distillation_checkpoint = "distilbert-base-uncased-finetuned-distillation-qqp"
student_distillation_training_args = DistillationTrainingArguments(
output_dir=student_distillation_checkpoint,
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=weight_decay,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
alpha=0.8
)
student_distillation_trainer = DistillationTrainer(
model_init=student_model_init,
args=student_distillation_training_args,
tokenizer=student_tokenizer,
teacher_model=teacher_model,
train_dataset=dataset_dict_student_tokenized['train'],
eval_dataset=dataset_dict_student_tokenized['validation'],
compute_metrics=compute_metrics
)
student_distillation_trainer.train()
Benchmark¶
When determining which model to move forward with production, we usually look at model performance, latency, as well as memory (a.k.a model size). We'll create a helper class for measuring these key aspects, run our models through it for a fair comparison.
class Benchmark:
def __init__(
self,
dataset,
latency_warmup: int = 10,
latency_rounds: int = 100,
perf_batch_size: int = 128,
perf_round_digits: int = 3
):
self.dataset = dataset
self.latency_warmup = latency_warmup
self.latency_rounds = latency_rounds
self.perf_batch_size = perf_batch_size
self.perf_round_digits = perf_round_digits
self.temp_model_path = "model.pt"
def run(self, tokenizer, model, run_name):
"""run benchmark for a given tokenizer and model
we can provide a run_name to differentiate the results
from different runs in the final dictionary.
e.g.
{
"run_name": {
'size_mb': 417.73,
'num_parameters': 109483778,
'latency_avg_ms': 8.33,
'latency_std_ms': 1.16,
'f1': 0.878,
'precision': 0.867,
'recall': 0.89,
'roc_auc': 0.968
}
}
"""
model.eval()
size = self.compute_size(model)
latency = self.compute_latency(tokenizer, model)
performance = self.compute_performance(tokenizer, model)
# merge various metrics into one single dictionary
metrics = {**size, **latency, **performance}
return {run_name: metrics}
def predict(self, example, tokenizer, model):
inputs = tokenizer(
example["question1"],
example["question2"],
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model(**inputs.to(model.device))
return output
def compute_size(self, model):
"""save the model's parameter temporarily to local path for calculating model size.
Once calculation is done, purge the checkpoint.
Size is reported in megabtyes.
https://pytorch.org/tutorials/beginner/saving_loading_models.html
"""
torch.save(model.state_dict(), self.temp_model_path)
size_mb = os.path.getsize(self.temp_model_path) / (1024 * 1024)
size_mb = round(size_mb, 2)
os.remove(self.temp_model_path)
print(f"Model size (MB): {size_mb}")
print(f"# of parameters: {model.num_parameters()}")
return {"size_mb": size_mb, "num_parameters": model.num_parameters()}
def compute_latency(self, tokenizer, model):
"""
Pick the first example of the input dataset, compute the average latency as well as
standard deviation over a configurable number of runs.
Latency is reported in milliseconds.
"""
example = self.dataset[0]
latencies = []
for _ in range(self.latency_warmup):
_ = self.predict(example, tokenizer, model)
for _ in range(self.latency_rounds):
start_time = perf_counter()
_ = self.predict(example, tokenizer, model)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
latency_avg_ms = round(1000 * np.mean(latencies), 2)
latency_std_ms = round(1000 * np.std(latencies), 2)
print(f"Average latency (ms): {latency_avg_ms} +\- {latency_std_ms}")
return {"latency_avg_ms": latency_avg_ms, "latency_std_ms": latency_std_ms}
def compute_performance(self, tokenizer, model):
"""compute f1/precision/recall/roc_auc metrics around sequence classification."""
clf_metrics = evaluate.combine(["f1", "precision", "recall"])
roc_auc_metric = evaluate.load("roc_auc")
scores = []
predictions = []
references = []
dataset_tokenized = tokenize_dataset(self.dataset, tokenizer)
data_collator = DataCollatorWithPadding(tokenizer)
data_loader = DataLoader(dataset_tokenized, batch_size=self.perf_batch_size, collate_fn=data_collator)
for example in data_loader:
labels = example.pop("labels")
with torch.no_grad():
output = model(**example.to(model.device))
score = F.softmax(output.logits, dim=-1)
prediction = score.argmax(dim=-1)
scores += tensor_to_list(score[:, 1])
predictions += tensor_to_list(prediction)
references += tensor_to_list(labels)
metrics = clf_metrics.compute(predictions=predictions, references=references)
metrics["roc_auc"] = roc_auc_metric.compute(prediction_scores=scores, references=references)["roc_auc"]
for metric, value in metrics.items():
metrics[metric] = round(value, self.perf_round_digits)
return metrics
def tensor_to_list(tensor):
return tensor.cpu().numpy().tolist()
benchmark_metrics_dict = {}
benchmark = Benchmark(dataset_dict["validation"])
benchmark_metrics = benchmark.run(teacher_tokenizer, teacher_model, "bert_uncased_teacher")
benchmark_metrics_dict.update(benchmark_metrics)
benchmark_metrics = benchmark.run(
student_tokenizer,
student_trainer.model,
"distilbert_student"
)
benchmark_metrics_dict.update(benchmark_metrics)
benchmark_metrics = benchmark.run(
student_tokenizer,
student_distillation_trainer.model,
"distilbert_distillation_student"
)
benchmark_metrics_dict.update(benchmark_metrics)
pd.DataFrame.from_dict(benchmark_metrics_dict, orient="index")
The final table is a comparison on our teacher model (bert), and two student model (distilbert), where one of the students was trained with knowledge distilation loss, and the other wasn't. Quick observations are: we can definitely shrink our model size and improve latency by using a student model without much loss in terms of model performance. Note, we also didn't spend too much time tuning additional loss weighting, $\alpha$, and temperature scaling, $T$ hyperparameters that comes with knowledge distillation.
Notes¶
It is not surprising that large models tend to give superior performance. As software and hardware continues to advance, the barrier for training or accessing these large models will continue to lower, making scaling up still a promising approach to obtain better performance for whatever applications we care about. Despite that being said, there will always be scenarios where smaller models are preferable, and knowledge distillation [6] is a popular way for compressing our large models into less expensive ones while still retaining majority of its performance.
As mentioned in DistilBERT [7], they were able to compress a 110 million parameters BERT-base model to 66 million parameters DistilBERT model while retaining 97% of the original performance when measured on GLUE benchmark's dev set. If we were to distill a pre-trained model ourselves, it might be worth mentioning that a better student initialization strategy is to make sure our students are "well read" [8]. i.e. Our students typically have the same architecture with the only variations on smaller number of layers, instead of initializing them via truncating teacher layers or by taking one layer out of two like in DistilBERT, we should initialized from weights that have also gone through similar pre-training procedure as our teacher.
Reference¶
- [1] Blog: Task-specific knowledge distillation for BERT using Transformers & Amazon SageMaker
- [2] Blog: Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT
- [3] Blog: Knowledge Distillation: Principles, Algorithms, Applications
- [4] Blog: Weeknotes: Distilling distilled transformers
- [5] Doc: Neural Network Distiller - Knowledge Distillation
- [6] Paper: Geoffrey Hinton, Oriol Vinyals, et al. - Distilling the Knowledge in a Neural Network - 2015
- [7] Paper: Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf - DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter - 2019
- [8] Paper: Iulia Turc, Ming-Wei Chang, Kenton Lee, Kristina Toutanova - Well-Read Students Learn Better: On the Importance of Pre-training Compact Models - 2019