# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format='retina'
import numpy as np
import pandas as pd
from time import time
from joblib import cpu_count
from collections import Counter
from gensim.models import Word2Vec
from sklearn.datasets import fetch_20newsgroups
%watermark -a 'Ethen' -d -t -v -p numpy,scipy,pandas,sklearn,gensim
Word2vec (Skipgram)¶
At a high level Word2Vec is a unsupervised learning algorithm that uses a shallow neural network (with one hidden layer) to learn the vectorial representations of all the unique words/phrases for a given corpus. The advantage that word2vec offers is it tries to preserve the semantic meaning behind those terms. For example, a document may employ the words "dog" and "canine" to mean the same thing, but never use them together in a sentence. Ideally, the word2vec algorithm would be able to learn the context and place them together in similar vector semantic space.
We'll start off by using the Gensim's implementation of the algorithm to provide a high-level intuition.
# the .data attribute will access the raw data, where
# each element is a document
newsgroups_train = fetch_20newsgroups(subset='train')
# gensim’s Word2vec expects a sequence of sentences as its input,
# where each sentence a list of words. We'll be lazy for now
# and not perform any sort of text preprocessing
sentences = [doc.strip().split() for doc in newsgroups_train.data]
# example output of the data
print('raw data:\n\n', newsgroups_train.data[0])
print('example input:\n', sentences[0])
# apart from the input sentence, the only additional paramter
# we'll set is to specify use all possible cpu to train the model
workers = cpu_count()
start = time()
word2vec = Word2Vec(sentences, workers=workers)
elapse = time() - start
print('elapse time:', elapse)
# obtain the learned word vectors (.wv.vectors)
# and the vocabulary/word that corresponds to each word vector
word_vectors = pd.DataFrame(word2vec.wv.vectors, index=word2vec.wv.index2word)
print('word vector dimension: ', word_vectors.shape)
word_vectors.head()
After the model has learned the word vector for each valid word in our corpus, we can use them to look up related words and phrases (words that have similar semantic meaning) for a given term of interest by comparing distances between the vectors using distance metric such as cosine distance.
word2vec.wv.most_similar(positive=['computer'], topn=5)
Apart from finding similar words using distance metric such as cosine distance, word vectors have the remarkable property that analogies between words seem to be encoded in the difference between word vectors. For example there seems to be a constant male-female difference vector:
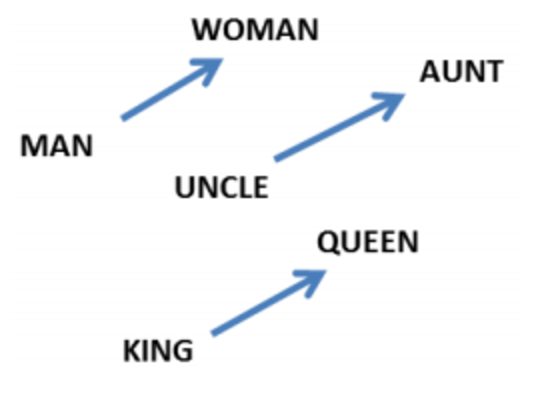
This property means we can also perform vector manipulation (e.g. addition and subtraction) with our word vectors. For example, you might have heard or saw the famous example of: King - male + female = queen. In the next section, we'll be taking a look at this model's inner workings. The explanations "borrows" heavily from the blogs listed below.
Model Details¶
The way the model works underneath the hood is that trains a neural network by do the following: Given a specific word in the middle of a sentence (the input word), look at the words nearby and pick one at random.
There is a window size hyperparameter to the algorithm that quantifies the word "nearby". A typical window size might be 5, meaning 5 words behind and 5 words ahead (10 in total). There are some implementations that does something even fancier: Instead of using a fix $k$ window around each word, the window is uniformly distributed from $1, 2, ..., K$, where $K$ is the max window size we specify.
The diagram below shows some of the training samples (word pairs) we would take from the sentence "The quick brown fox jumps over the lazy dog." We'll used a small window size of 2 just for the example. The word highlighted in blue is the input word.
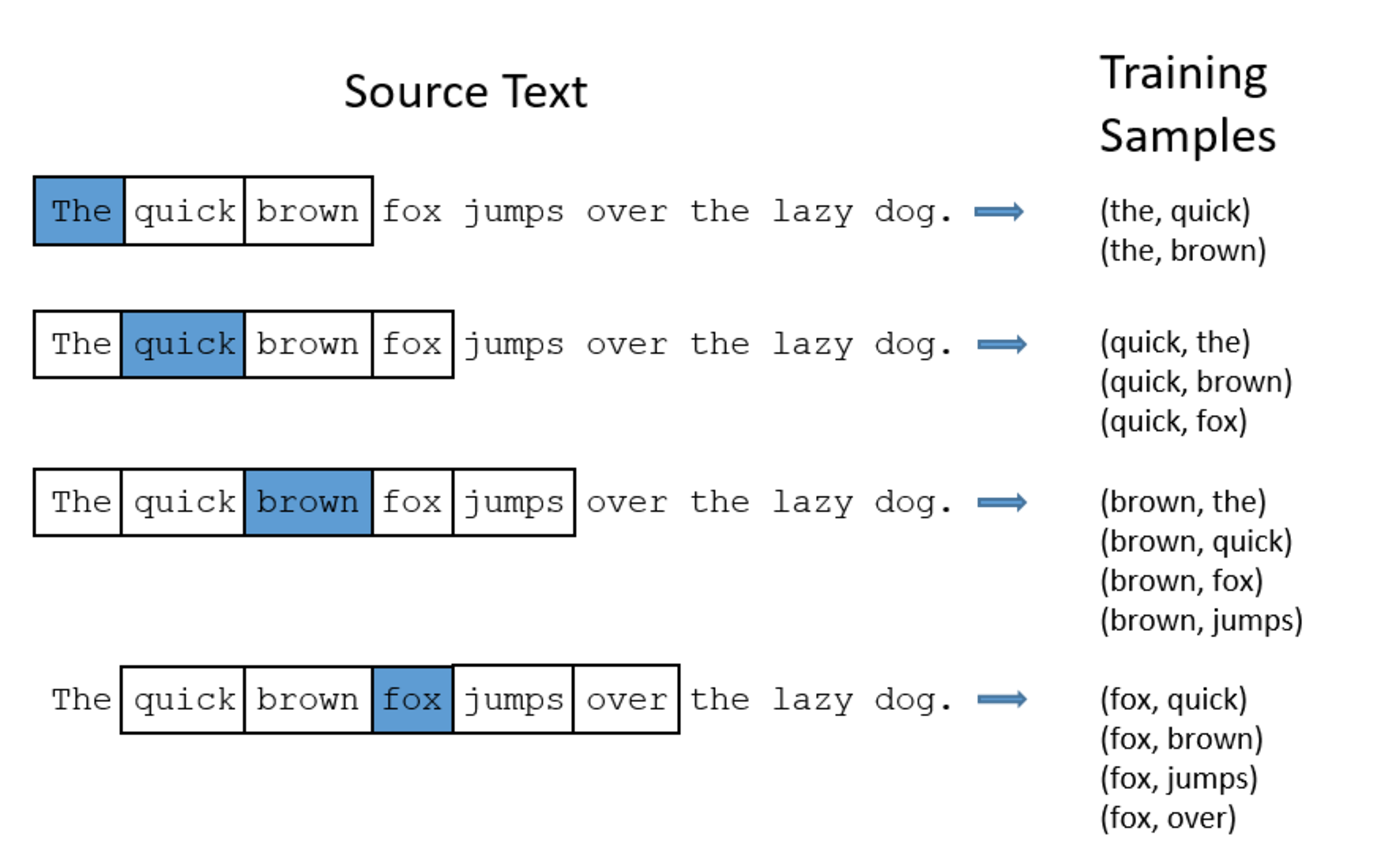
After feeding a bunch of word pairs to the network, it is going to tell us the probability for every word in our vocabulary being "nearby" word that we chose. The output probabilities are going to relate to how likely it is find each vocabulary word nearby our input word. For example, if we gave the trained network the input word "Soviet", the output probabilities should be much higher for words like "Union" and "Russia" than for unrelated words like "watermelon" and "kangaroo".
So how is this all represented? First of all, we know we can't feed a word just as a text string to a neural network (or probably any machine learning model), i.e. we need a way to represent the words to the network. To do this, we first build a vocabulary of words from our training documents. We'll assume that our corpus has a vocabulary size of 10,000.
We're going to represent an input word like "ants" as a one-hot vector. This vector will have 10,000 components (one for every unique word in our vocabulary) and we'll place a "1" in the position corresponding to the word "ants", and 0s in all of the other positions. The output of the network is a single vector (also with 10,000 components) containing, for every word in our vocabulary, the probability that a randomly selected nearby word is that vocabulary word. Here's the architecture of our single-layer neural network.
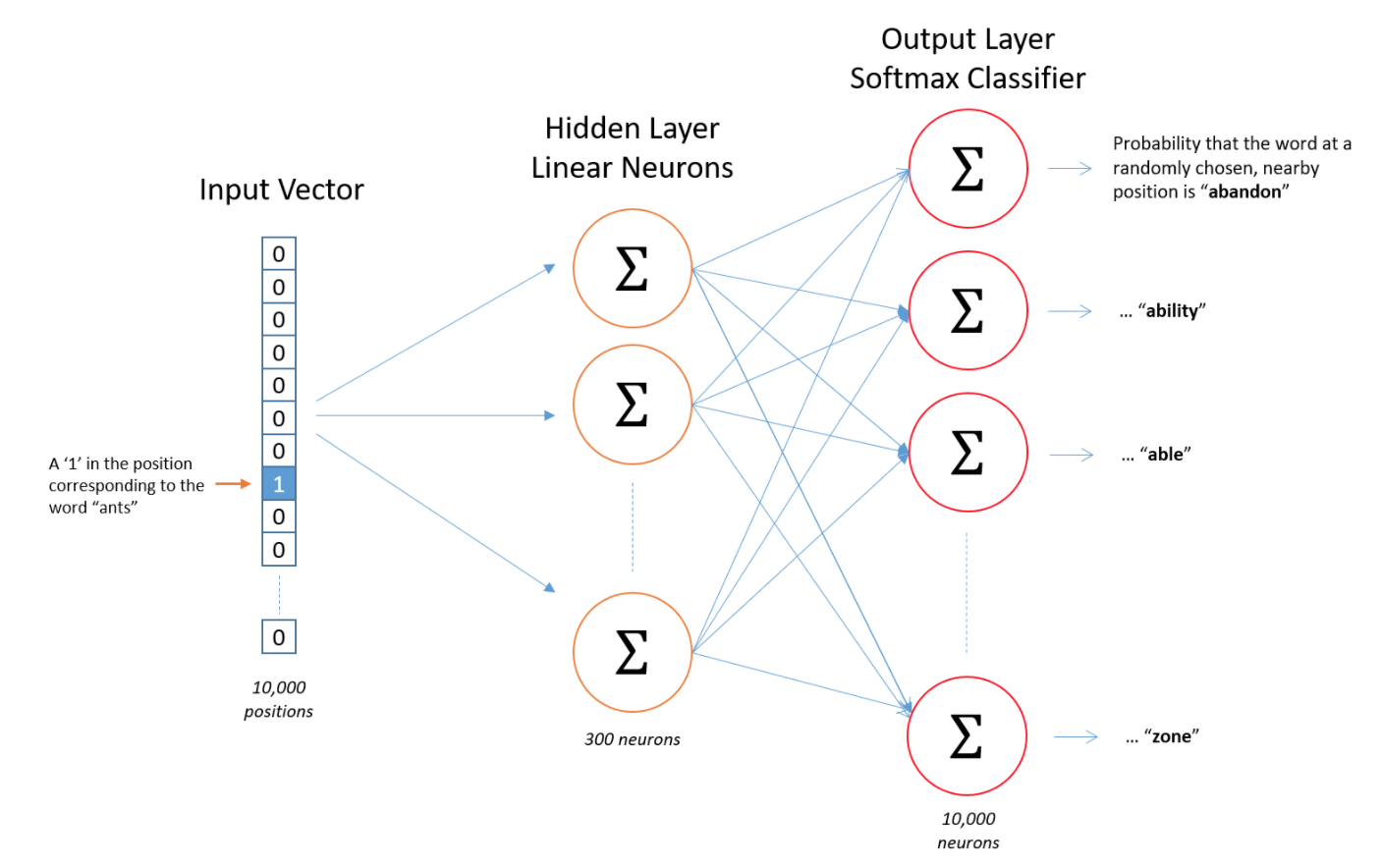
There is no activation function on the hidden layer neurons, but the output neurons use softmax. We’ll come back to this later.
When training this network on word pairs, the input is a one-hot vector representing the input word and the training output is also a one-hot vector representing the output word. But when we evaluate the trained network on an input word, the output vector will actually be a probability distribution (i.e., a bunch of floating point values, not a one-hot vector).
An alternative diagram that depicts that Skip-gram model architecture well:
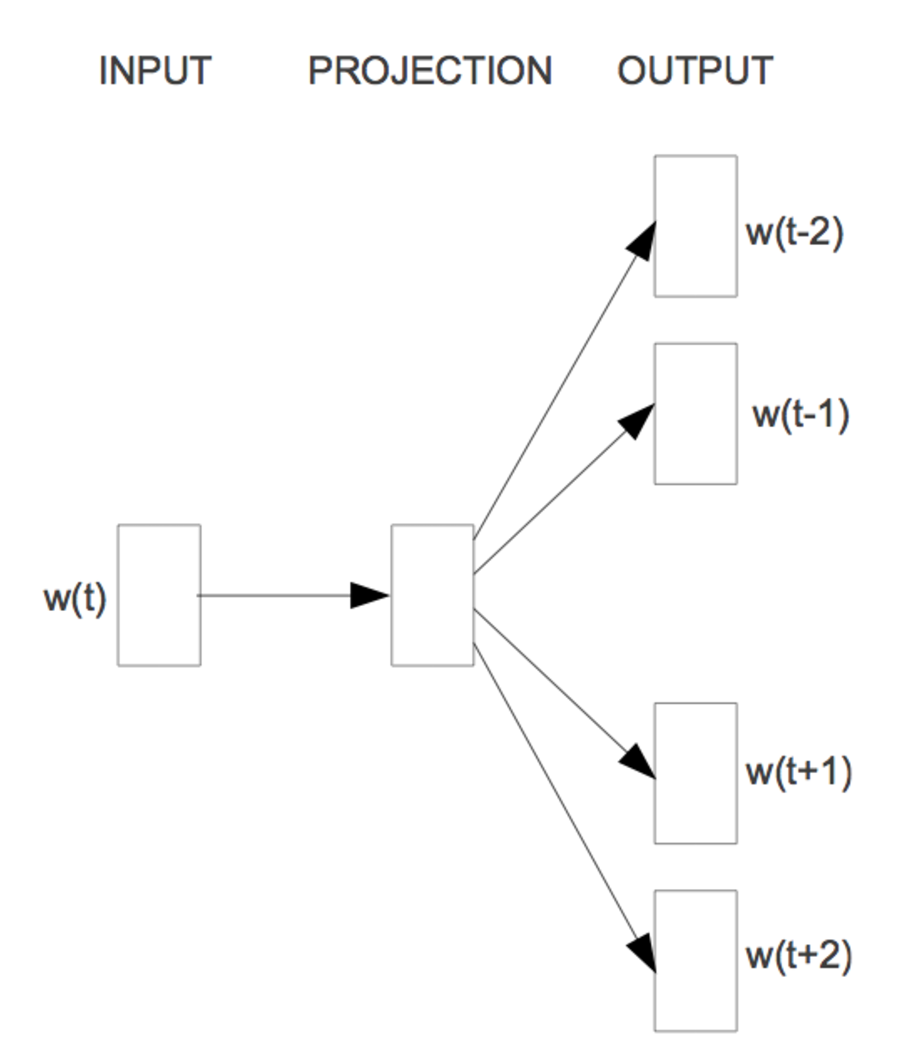
Where we're using the centre word $w_{(t)}$ to predict the surrounding words and the training objective is to learn word vector representations, a.k.a projections that are good at predicting the nearby words.
The Hidden Layer¶
Let's say that we wish to learn word vectors with 300 features. The number of features is a hyperparameter that we would have to tune to our application to see which one yields the best result. So the hidden layer is going to be represented by a weight matrix with 10,000 rows (one for every word in our vocabulary) and 300 columns (one for every hidden neuron).
Now if we look at what would happen when we multiply the 1 x 10,000 one-hot vector representation of the word with a 10,000 x 300 matrix that represents the hidden layer's weight, it will effectively just select the matrix row corresponding to the "1". The following figure is a small example that does a matrix multiplication of a 1 x 5 one hot vector with a 5 x 3 hidden layer's weight to give you a visual.
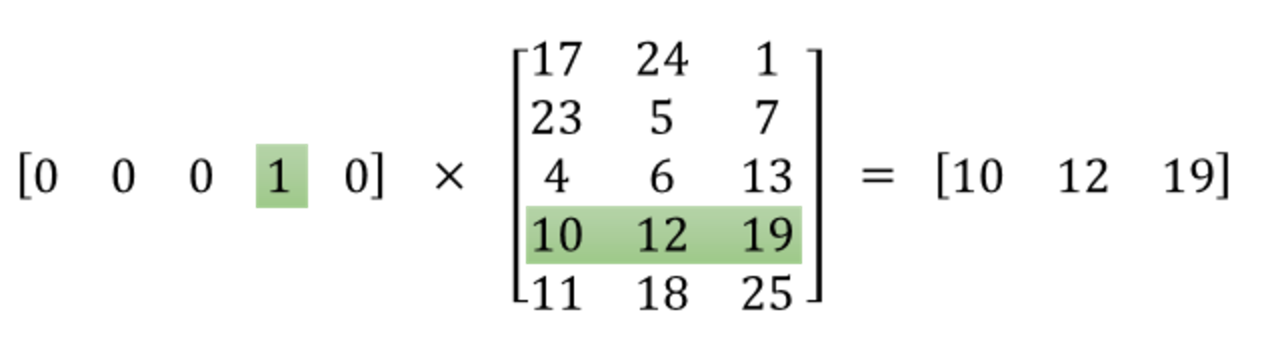
This means that the hidden layer of this model is really just operating as a lookup table and the output of the hidden layer is essentially the "word vector" for the input word.
The Output Layer¶
The 1 x 300 word vector for "ants" then gets fed to the output layer. The output layer is a Softmax regression classifier. There's another documentation on Softmax Regression here, but the gist of it is that each output neuron, one per word in our vocabulary will produce an output probability between 0 and 1 and the sum of all these output values will add up to 1.
Specifically, each output neuron has a weight vector which it multiplies against the word vector from the hidden layer, then it applies the function exp(x) to the result. Finally, in order to get the outputs to sum up to 1, we divide this result by the sum of the results from all 10,000 output nodes. Here's an illustration of calculating the output probability for the word "car".
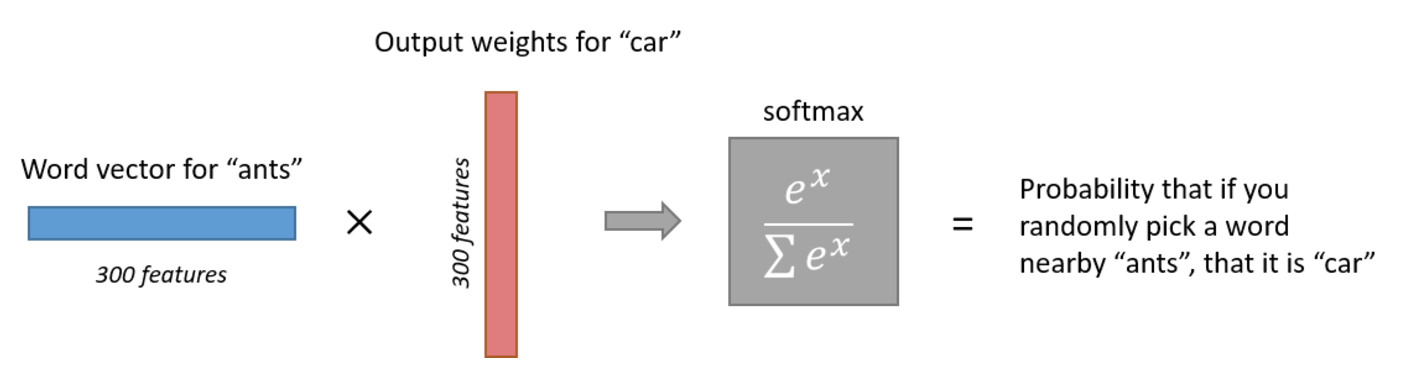
Note that neural network does not know anything about the offset of the output word relative to the input word. In other words, it does not learn a different set of probabilities for the word before the input versus the word after.
Recall that in the beginning of the documentation, we mentioned that the goal for word2vec is to represent each word in the corpus as the vector representation while trying to preserve semantic meaning. This means that if two different words have very similar "contexts" (that is, what words are likely to appear around them), then our model needs to output very similar results for these two words. And one way for the network to output similar context predictions for these two words is if the word vectors are similar. So to hit the notion home, if two words have similar contexts, then word2vec is motivated to learn similar word vectors for these two words!
Improving Word2vec¶
You may have noticed that the skip-gram neural network contains a huge number of weights ... For our example with 300 features and a vocab of 10,000 words, that's 3M weights in the hidden layer and output layer each! Training this on a large dataset would be slow and prone to overfitting, so the word2vec authors introduced a number of tweaks to make training feasible.
- Modifying the optimization objective with a technique they called "Negative Sampling", which causes each training sample to update only a small percentage of the model's weights.
- Subsampling frequent words to decrease the number of training examples.
- Treating common word pairs or phrases as single word in the model.
It's worth noting that subsampling frequent words and applying Negative Sampling not only reduced the compute burden of the training process, but also improved the quality of their resulting word vectors as well.
Negative Sampling¶
Training a neural network means taking a training example and adjusting all of the neuron weights slightly so that it predicts that training sample more accurately. In other words, each training sample will tweak all of the weights in the neural network. As we discussed above, the size of our word vocabulary means that our skip-gram neural network has a tremendous number of weights, all of which would be updated slightly by every one of our billions of training samples! Negative sampling addresses this by having each training sample only modify a small percentage of the weights, rather than all of them. Here's how it works:
When training the network on the word pair ("fox", "quick"), we want the "correct output" of the network, that is the output neuron corresponding to "quick" to output a 1, and for all of the other thousands of output neurons to output a 0.
With negative sampling, we are instead going to randomly select just a small number of "negative" words (let's say 5) to update the weights for. (In this context, a "negative" word is one for which we want the network to output a 0 for). We will also still update the weights for our "positive" word (which is the word "quick" in our current example).
The paper says that selecting 5-20 words works well for smaller datasets, and we can get away with only 2-5 words for large datasets.
Recall that the output layer of our model has a weight matrix that's 300 x 10,000. So we will just be updating the weights for our positive word ("quick"), plus the weights for 5 other words that we want to output 0. That's a total of 6 output neurons, and 1,800 weight values total. That's only 0.06% of the 3M weights in the output layer!
In the hidden layer, only the weights for the input word are updated (this is true whether you're using Negative Sampling or not).
Mathematical Notation¶
This section goes back and re-visit the mathematical notation for Word2vec skipgram's objective function. Hopefully, the math won't look so daunting after having an understanding of the model from a non-mathematical standpoint.
In this model, we are given a corpus of words $w$ and their contexts $c$ (the word pair of the targeted word that we've sampled). Our goal is to set the parameters $\theta$ of $p(c | w; \theta)$ to maximize our objective function $J_\theta$, i.e. the corpus probability, with regards to our model parameters $\theta$:
$$ \begin{align} J_{\theta} &= arg\underset{\theta}{max} \prod_{w \in Text} \bigg[ \prod_{c \in C(w)} p(c | w; \theta) \bigg] \end{align} $$Here $C(w)$ is word $w$'s set of contexts.
One approach for parameterizing the $p(c | w; \theta)$ part of the skip-gram model is the classic softmax objective function:
$$ \begin{align} p(c | w; \theta) &= \dfrac{exp(v_c \cdot v_w)}{ \sum_{c' \in C} exp(v_c' \cdot v_w)} \end{align} $$Where:
- $v_c$ and $v_w$ are the vector representations for word $c$ and $w$ respectively
- $C$ is the set of all available contexts
While the objective function above can be computed, it is computationally expensive to do so due to the summation $\sum_{c' \in C} exp(v_c' \cdot v_w)$ since there can be thousands if not million of them. And this is where negative sampling comes in.
Instead of trying to estimate the probability of the word pair directly, we train a model to differentiate the target word from noise (negative sample). We can thus reduce the problem of predicting the correct word to a binary classification task, where the model tries to distinguish positive/genuine data from noise/negative samples.
We know for the word pair we generated from the data, we want to maximize its probability, i.e.
$$ \begin{align} arg\underset{\theta}{max} \prod_{(w, c) \in D} p(D = 1 \big| c, w; \theta) \end{align} $$Here:
- $D$ is the set of all word and context pairs we extract from the text
- $p(D = 1 \big| w, c)$ the probability that the word pair $(w, c)$ came from the corpus data
We then generate the set $D'$ of random (w, c) pairs, assuming they are all incorrect. The name "negative sampling" stems from the set $D'$ of randomly sampled negative examples. Note that when we pick one random word from the vocabulary, there is some tiny chance that the picked word is actually a valid context. If we consider the large number of vocabulary we have, we can argue that the probability is really really tiny, but a lot of the packages still do take care of removing these "accidents".
Since this is a binary classification loss, we can use logistic regression to minimize the negative log-likelihood, leading to the objective function:
\begin{align} J_{\theta} &= arg\underset{\theta}{max} \prod_{(w, c) \in D} p(D = 1 \big| c, w; \theta) \prod_{(w, c) \in D'} p(D = 0 \big| c, w; \theta) \\ &= arg\underset{\theta}{max} \prod_{(w, c) \in D} p(D = 1 \big| c, w; \theta) \prod_{(w, c) \in D'} \big(1 - p(D = 1 \big| c, w; \theta)\big) \\ &= arg\underset{\theta}{max} \sum_{(w, c) \in D} log \big(p(D = 1 \big| c, w; \theta)\big) \sum_{(w, c) \in D'} log \big(1 - p(D = 1 \big| c, w; \theta)\big) \\ &= arg\underset{\theta}{max} \sum_{(w, c) \in D} log \big( \dfrac{1}{1 + \text{exp}(-v_c \cdot v_w)} \big) \sum_{(w, c) \in D'} log \big (1 - \dfrac{1}{1 + \text{exp}(-v_c \cdot v_w)} \big) \\ &= arg\underset{\theta}{max} \sum_{(w, c) \in D} log \big( \dfrac{1}{1 + \text{exp}(-v_c \cdot v_w)} \big) \sum_{(w, c) \in D'} log \big (\dfrac{1}{1 + \text{exp}(v_c \cdot v_w)} \big) \\ \end{align}Note that there're various other approaches to approximate the expensive softmax objective function. Negative sampling is soley discussed here because it is fast and works really really well. If you would like to go deeper with this topic, the following link might be a good place to start. Blog: On word embeddings - Part 2: Approximating the Softmax
Selecting Negative Samples¶
One little detail that's missing from the description above is how do we select the negative samples.
The negative samples are chosen using the unigram distribution. Essentially, the probability of selecting a word as a negative sample is related to its frequency, with more frequent words being more likely to be selected as negative samples. Instead of using the raw frequency for $w_i$, $\text{freq}(w_i)$, in the original word2vec paper, each word is given a weight that's equal to it's frequency (word count) raised to the 3/4 power. The probability for selecting a word is just it's weight divided by the sum of weights for all words.
$$ \begin{align} P(w_i) = \frac{ {\text{freq}(w_i)}^{3/4} }{\sum_{j=0}^{n} \left({\text{freq}(w_j)}^{3/4} \right) } \end{align} $$This decision to raise the frequency to the 3/4 power appears to be empirical; as the author claims it outperformed other functions (e.g. just using unigram distribution).
Side note: The way this selection is implemented in the original word2vec C code is interesting. They have a large array with 100M elements (which they refer to as the unigram table). They fill this table with the index of each word in the vocabulary multiple times, and the number of times a word’s index appears in the table is given by $P(w_i) \times \text{table_size}$. Then, to actually select a negative sample, we just generate a random integer between 0 and 100M, and use the word at that index in the table. Since the higher probability words occur more times in the table, we're more likely to pick those.
Subsampling Frequenct Words¶
Word2vec has two additional parameters for discarding some of the input words: words appearing less
than min-count times are not considered as either words or contexts, and in addition frequent words are down-sampled as defined by the sample parameter.
There are two potential issues with frequently appeared words like "the":
- When looking at word pairs that includes "the", e.g. ("fox", "the"), "the" doesn't tell us much about the meaning of "fox", since it appears in the context of pretty much every word.
- We will have more than enough samples of ("the", "the other word for the word pair") than we need to learn a good vector for "the".
Word2Vec implements a "subsampling" scheme to address this. For each word we encounter in our training text, there is a chance that we will discard it from the text. The probability that we cut the word is related to the word's frequency.
$$ \begin{align} \text{probability of keeping the word } w_i &= (\sqrt{\frac{z(w_i)}{0.001}} + 1) \cdot \frac{0.001}{z(w_i)} \end{align} $$Where:
- $z(w_i)$ is the fraction of the total words in the corpus that are that word. For example, if the word "peanut" occurs 1,000 times in a 1 billion word corpus, then z("peanut") = 1E-6.
- There is also a parameter called
samplewhich controls how much subsampling occurs, and the default value is 0.001. Smaller values ofsamplemean words are less likely to be kept
Here are some interesting observations of this subsampling function (again this is using the default sample value of 0.001).
- $\text{probability of keeping the word } w_i = 1$ (100% chance of being kept) when $z(w_i) <= 0.0026$. This means that only words which represent more than 0.26% of the total words will be subsampled
- $\text{probability of keeping the word } w_i = 0.5$ (50% chance of being kept) when $z(w_i) <= 0.00746$
- $\text{probability of keeping the word } w_i = 0.033$ (3.3% chance of being kept) when $z(w_i) = 1.0$. That is, if the corpus consisted entirely of word $w_i$, which of course is ridiculous
Detecting Phrases¶
Word pair like "Boston Globe" (a newspaper) has a much different meaning than the individual words "Boston" and "Globe". So it makes sense to treat "Boston Globe", wherever it occurs in the text, as a single word with its own word vector representation.
The formula our phrase models will use to determine whether two tokens $A$ and $B$ constitute a phrase is:
$$ \begin{align} \frac{count(A B) - count_{min}}{count(A) \cdot count(B)} \cdot N > threshold \end{align} $$Where:
- $count(A)$ is the number of times token $A$ appears in the corpus
- $count(B)$ is the number of times token $B$ appears in the corpus
- $count(A B)$ is the number of times the tokens $A B$ appear in the corpus in this specific order
- $N$ is the total size of the corpus vocabulary
- $count_{min}$ is a user-defined parameter to ensure that accepted phrases occur a minimum number of times,
- $threshold$ is a user-defined parameter to control how strong of a relationship between two tokens the model requires before accepting them as a phrase
As we can infer the formula is designed to make phrases out of words which occur together often relative to the number of individual occurrences. And a higher threshold value will favors phrases made of infrequent words in order to avoid making phrases out of common words like "and the" or "this is".
Implementation¶
The following code chunks 1) basic preprocess the raw text. 2) trains a Phrase model to glue words that commonly appear next to each other into bigrams. 3) trains the Word2vec model.
There also a pure python script here if you're interested.
import os
import re
from string import punctuation
from nltk.corpus import stopwords
from gensim.models import Phrases
from gensim.models import Word2Vec
from gensim.models.phrases import Phraser
from gensim.models.word2vec import LineSentence
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
def export_unigrams(unigram_path, texts, stop_words):
"""
Preprocessed the raw text and export it to a .txt file,
where each line is one document, for what sort of preprocessing
is done, please refer to the `normalize_text` function
Parameters
----------
unigram_path : str
output file path of the preprocessed unigram text.
texts : iterable
iterable can be simply a list, but for larger corpora,
consider an iterable that streams the sentences directly from
disk/network using Gensim's Linsentence or something along
those line.
stop_words : set
stopword set that will be excluded from the corpus.
"""
with open(unigram_path, 'w', encoding='utf_8') as f:
for text in texts:
cleaned_text = normalize_text(text, stop_words)
f.write(cleaned_text + '\n')
def normalize_text(text, stop_words):
# remove special characters\whitespaces
text = re.sub(r'[^a-zA-Z\s]', '', text, re.I | re.A)
# lower case & tokenize text
tokens = re.split(r'\s+', text.lower().strip())
# filter stopwords out of text &
# re-create text from filtered tokens
cleaned_text = ' '.join(token for token in tokens if token not in stop_words)
return cleaned_text
# a set of stopwords built-in to various packages
# we can always expand this set for the
# problem that we are working on, here we also included
# python built-in string punctuation mark
STOPWORDS = set(stopwords.words('english')) | set(punctuation) | set(ENGLISH_STOP_WORDS)
# create a directory called 'model' to
# store all outputs in later section
MODEL_DIR = 'model'
if not os.path.isdir(MODEL_DIR):
os.mkdir(MODEL_DIR)
UNIGRAM_PATH = os.path.join(MODEL_DIR, 'unigram.txt')
if not os.path.exists(UNIGRAM_PATH):
start = time()
export_unigrams(UNIGRAM_PATH, texts=newsgroups_train.data, stop_words=STOPWORDS)
elapse = time() - start
print('text preprocessing, elapse', elapse)
PHRASE_MODEL_CHECKPOINT = os.path.join(MODEL_DIR, 'phrase_model')
if os.path.exists(PHRASE_MODEL_CHECKPOINT):
phrase_model = Phrases.load(PHRASE_MODEL_CHECKPOINT)
else:
# use LineSentence to stream text as oppose to
# loading it all into memory
unigram_sentences = LineSentence(UNIGRAM_PATH)
start = time()
phrase_model = Phrases(unigram_sentences)
elapse = time() - start
print('training phrase model, elapse', elapse)
phrase_model.save(PHRASE_MODEL_CHECKPOINT)
def export_bigrams(unigram_path, bigram_path, phrase_model):
"""
Use the learned phrase model to create (potential) bigrams,
and output the text that contains bigrams to disk
Parameters
----------
unigram_path : str
input file path of the preprocessed unigram text
bigram_path : str
output file path of the transformed bigram text
phrase_model : gensim's Phrase model object
References
----------
Gensim Phrase Detection
- https://radimrehurek.com/gensim/models/phrases.html
"""
# after training the Phrase model, create a performant
# Phraser object to transform any sentence (list of
# token strings) and glue unigrams together into bigrams
phraser = Phraser(phrase_model)
with open(bigram_path, 'w') as fout, open(unigram_path) as fin:
for text in fin:
unigram = text.split()
bigram = phraser[unigram]
bigram_sentence = ' '.join(bigram)
fout.write(bigram_sentence + '\n')
BIGRAM_PATH = os.path.join(MODEL_DIR, 'bigram.txt')
if not os.path.exists(BIGRAM_PATH):
start = time()
export_bigrams(UNIGRAM_PATH, BIGRAM_PATH, phrase_model)
elapse = time() - start
print('converting words to phrases, elapse', elapse)
The next two code chunks is a slight digression from the overall process, this is simply used assess the amount of memory that is potentially saved by doing these preprocessing, i.e. loading all the raw text and preprocessed text into memory and comparing the two.
import sys
def get_size(obj, seen=None):
"""
Recursively finds size of objects, shamelessly "borrowed"
from link listed in reference
References
----------
https://goshippo.com/blog/measure-real-size-any-python-object/
"""
size = sys.getsizeof(obj)
if seen is None:
seen = set()
obj_id = id(obj)
if obj_id in seen:
return 0
# Important mark as seen *before* entering recursion to gracefully handle
# self-referential objects
seen.add(obj_id)
if isinstance(obj, dict):
size += sum([get_size(v, seen) for v in obj.values()])
size += sum([get_size(k, seen) for k in obj.keys()])
elif hasattr(obj, '__dict__'):
size += get_size(obj.__dict__, seen)
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
size += sum([get_size(i, seen) for i in obj])
return size
X = []
with open(BIGRAM_PATH) as f:
for line in f:
X.append(line)
original_size = get_size(newsgroups_train.data)
preprocessed_size = get_size(X)
ratio = original_size / preprocessed_size
print('original size uses {} times the amount of memory'.format(ratio))
del X
The Word2vec also accepts several key parameters that affect both training speed and quality. Hopefully these will now make more sense after we covered some theory of the algorithm.
iter: Number of iterations to train the model.min_count: For pruning the internal dictionary. Words that appear only once or twice in a billion-word corpus are probably uninteresting typos and garbage. In addition, there's not enough data to make any meaningful training on those words, so it's best to ignore them. A reasonable value for min_count is between 0-100, depending on the size of the dataset.size: Refers to the hidden layers size, i.e. dimension of our word vectors. Bigger size values require more training data, but can lead to better (more accurate) models. Reasonable values are in the tens to hundredsworkers: Number of cores/threads used for training.window: Only terms that occur within a window-neighbourhood of a term in a sentence are associated with it during training. The default value is 4. Unless your text contains big sentences, it might be safe to leave it at that.sg: This defines the algorithm. If equal to 1, the skip-gram technique is used. Else, the CBoW method is employed. The word2vec framework we introduced here is skip-gram, where we're using the target word to predict the context word, where CBow is simply flipping it the other way around, i.e. using the context word to predict the target word. Based on the original author's paper, Skip-gram is reported to be a better framework.
You can refer to the full list of parameters here.
WORD2VEC_CHECKPOINT = os.path.join(MODEL_DIR, 'word2vec')
if os.path.exists(WORD2VEC_CHECKPOINT):
word2vec = Word2Vec.load(WORD2VEC_CHECKPOINT)
else:
# the old way of streaming data into gensim's Word2Vec was to
# leverage the LineSentence generator, i.e.
# sentences = LineSentence(BIGRAM_PATH)
# word2vec = Word2Vec(sentences, workers=cpu_count())
# the latest and faster way is to directly pass the path to
# the corpus_file argument or what they call file based training mode
start = time()
word2vec = Word2Vec(corpus_file=BIGRAM_PATH, workers=cpu_count())
elapse = time() - start
print('training word2vec, elapse', elapse)
word2vec.save(WORD2VEC_CHECKPOINT)
After that we can print out similar words to a targeted word that we've specified and use our human judgement of whether the embedding that was learned makes sense. The next code chunk is simply satisfying a personal interest in how the most_similar function is implemented in gensim.
# once we’re finished training the model (i.e. no more updates, only querying)
# we can store the word vectors and delete the model to trim unneeded model memory
vocab = word2vec.wv.vocab
word_vectors = word2vec.wv.vectors
index2word = word2vec.wv.index2word
del word2vec
from sklearn.preprocessing import normalize
def most_similar(word_vectors, vocab, index2word,
positive=None, negative=None, topn=5):
"""
No frill version of the function `word2vec.wv.most_similar`;
Find the top-N most similar words. Positive words contribute
positively towards the similarity, negative words negatively.
Parameters
----------
word_vectors : 2d ndarray
the learned word vectors.
vocab : word2vec.wv.vocab
dictionary like object where the key is the word
and the value has a .index attribute that allows
us to look up the index for a given word.
index2word : word2vec.wv.index2word
list like object that serves as the looking up the word
of a given index.
positive/negative : list, default None
list of positive or negative words to look for similar words,
positive words will get assign a +1 weight and negative words
will get assign a -1 weight when doing the vector addition.
topn : int
top-n similar words to find.
"""
# normalize word vectors up front makes the cosine distance
# calculation later easier
normed_vectors = normalize(word_vectors)
# assign weight to positive and negative words
if positive is None:
positive = []
else:
positive = [(word, 1.0) if isinstance(word, str) else word
for word in positive]
if negative is None:
negative = []
else:
negative = [(word, -1.0) if isinstance(word, str) else word
for word in negative]
# compute the weighted average of all the query words
queries = []
all_word_index = set()
for word, weight in positive + negative:
# gensim's Word2vec word2vec.wv.vocab.index
# stores the index of a given word
word_index = vocab[word].index
word_vector = normed_vectors[word_index]
queries.append(weight * word_vector)
all_word_index.add(word_index)
if not queries:
raise ValueError('cannot compute similarity with no input')
# find topn most similar words measured by cosine distance
query_vector = np.mean(queries, axis=0)
query_vector /= np.sqrt(np.sum(query_vector ** 2))
# cosine similarity between the query vector and all the existing word vectors
scores = np.dot(normed_vectors, query_vector)
actual_len = topn + len(all_word_index)
sorted_index = np.argpartition(scores, -actual_len)[-actual_len:]
best = sorted_index[np.argsort(scores[sorted_index])[::-1]]
result = [(index2word[index], scores[index])
for index in best if index not in all_word_index]
return result[:topn]
word = 'computer'
most_similar(word_vectors, vocab, index2word, positive = [word])
Final Thoughts¶
Hyperparameters¶
The most crucial decisions that affect the performance are the choice of the model architecture, the size of the vectors, the subsampling rate, and the size of the training window. Because Word2vec training is an unsupervised task, there's no good way to objectively evaluate the result, it all depends on the end application.
Applications¶
Word2Vec and the concept of word embeddings originated in the domain of NLP, however the idea of words in the context of a sentence or a surrounding word window can be generalized to other problem domain dealing with sequences or sets of related data points. For example:
- A direct application of Word2Vec to a classical engineering task was recently presented by Spotify. They abstracted the ideas behind Word2Vec to apply them not simply to words in sentences but to any object in any sequence, in this case to songs in a playlist. Songs are treated as words and other songs in a playlist as their surrounding context, depending on whether the playlists in question were genre specific the vocabulary encompassed a number of songs from that collection. Now in order to recommend songs to a user one merely has to examine a neighborhood of the 'song embeddings' of songs the user already likes
- Similarly, we could recommend a user who to connect to in a social network setting by examining the graph of relationships, where the nodes represent words and a path through the graph represents a sentence, then nodes that occur in the context of similar other nodes, would be close together in the vector space.
These examples show that the general applicability of Word2Vec based algorithms is very rich and that it behooves practitioners to examine their problem domain with respect to sequences of objects that occur in some meaningful context.
Resources¶
A lot of the non-mathematical notes were taken from Chris McCormick's blog post. If you wish to learn more about the topic, the following link also contains different resources that Chris has curated (including a commented version of word2vec's original C code, derivation of word2vec's gradient update, etc.). Blog: Word2Vec Resources
If you would like to practice using a deep learning framework such as Tensorflow to implement the word2vec model. The following resources are good places to start, the reason that its not included in this documentation is because it was an order of magnitude slower than Gensim's Word2vec and the result weren't as good as well.
Reference¶
- Blog: Word2vec Tutorial
- Blog: Word2Vec Tutorial - The Skip-Gram Model
- Blog: Word2Vec Tutorial Part 2 - Negative Sampling
- Blog: Natural Language Processing Made Easy – using SpaCy (in Python)
- Paper: Yoav Goldberg, Omer Levy (2014) word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method
- Paper: Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean (2013) Distributed Representations of Words and Phrases and their Compositionality
- Youtube: PyData DC 2016: Modern NLP in Python
- Jupyter Notebook: PyData DC 2016: Modern NLP in Python
- Jupyter Notebook: Gensim Docs - 2Vec File-based Training: API Tutorial