# code for loading notebook's format
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
%load_ext watermark
%load_ext autoreload
%autoreload 2
import os
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import sklearn.metrics as metrics
from datasets import (
Dataset,
load_dataset,
disable_progress_bar
)
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
from transformers import (
AutoConfig,
AutoTokenizer,
AutoModel,
AutoModelForSequenceClassification,
PretrainedConfig,
PreTrainedModel,
TrainingArguments,
Trainer
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
%watermark -a 'Ethen' -d -v -u -p transformers,datasets,torch,numpy,pandas,sklearn
BERT CTR¶
In many real world applications, our dataset is often times multi-modal [3]. Where there are textual information, structured/tabular data, or even data represented in image, video, audio format. In this article, we'll look at the problem of multimodal fusion, where our goal is to jointly model information from two or more modalities to make a prediction, specifically text and structured/tabular data.
Data¶
KDD 2012 Track 2 [1] is focused on predicting click through rate (CTR). This task involves not only textual data related to search query and ad, but also includes additional structured/tabular data such as user's demographic information gender/age, etc.
Note, while this dataset we're using is slightly more representative of real world application, it unfortunately still has some limitations. The most notable one being, for anonymity reasons, this dataset provides tokens represented as hash values instead of actual raw text. This entails we can't directly leverage pre-trained tokenizer/model.
Another dataset with similar characteristics is Baidu-ULTR [2]. This dataset is advantageous in terms of its larger scale: featuring 1.2B search sessions, and its richness: offering diverse display information such as position, display height, and so on for studying un-biased learning to rank. As well as diversified user behavior, including click, skip, dwell time for exploring multi-task learning. Though, again, it also has similar limitation where raw text is provided in a hashed id manner.
We'll be working with a sampled version of the original raw dataset. Readers can refer to kdd2012_track2_preprocess_data.py for a sample pre-processing script.
df_train = pd.read_parquet("track2_processed_train.parquet")
df_test = pd.read_parquet("track2_processed_test.parquet")
print("train shape: ", df_train.shape)
print("test shape: ", df_test.shape)
print("label distribution: ", df_train["label"].value_counts())
df_train.head()
dataset_train = Dataset.from_pandas(df_train)
dataset_test = Dataset.from_pandas(df_test)
print(dataset_train)
dataset_train[0]
These subsequent function/class for using deep learning on tabular data closely follows the ones introduced in Deep Learning for Tabular Data - PyTorch. [nbviewer][html]
We'll specify a config mapping for our input features, which will be utilized in both our batch collate function as well as the model itself. This config mapping stores the features we want to use as keys, and different value/enum specifying whether the field is of text/token, numerical or categorical type. Which inform our pipeline about the embedding size required for a categorical type, how many numerical fields are there to initiate the dense/feed forward layers, whether to apply tokenization/padding for text/token type fields.
# we use a distil bert style architecture, with 2 layers, these
# will be trained from scratch along with the CTR application
model_name = "distilbert-base-uncased"
n_layers = 2
# vocabulary size can be obtained from the data preprocessing script
pad_token_id = 148597
vocab_size = 148598
tokenizer = AutoTokenizer.from_pretrained(model_name)
# for category in ordinal_encoder.categories_:
# print(len(category))
features_config = {
"tokenized_title": {
"dtype": "token_id"
},
"tokenized_query": {
"dtype": "token_id"
},
"depth": {
"dtype": "numerical",
},
"gender": {
"dtype": "categorical",
"vocab_size": 4,
"embedding_size": 4
},
"age": {
"dtype": "categorical",
"vocab_size": 7,
"embedding_size": 4
},
"advertiser_id": {
"dtype": "categorical",
"vocab_size": 12193,
"embedding_size": 32
},
"user_id": {
"dtype": "categorical",
"vocab_size": 202547,
"embedding_size": 64
}
}
def text_tabular_collate_fn(batch):
"""
Use in conjunction with Dataloader's collate_fn for text and tabular data.
Returns
-------
batch : dict
Dictionary with 4 primary keys: input_ids, attention_mask, tabular_inputs, and labels.
Tabular inputs is a nested field, where each element is a feature_name -> float tensor
mapping. e.g.
{
'input_ids': tensor([[116438, 65110]]),
'attention_mask': tensor([[1, 1]]),
'tabular_inputs': {'I1': tensor([0., 0.]), 'C1': tensor([ 888., 1313.])},
'labels': tensor([0, 0])
}
"""
output = {}
labels = []
texts = []
token_ids = []
tabular_inputs = {}
for example in batch:
label = example["label"]
labels.append(label)
text = ""
token_id = []
for name, config in features_config.items():
dtype = config["dtype"]
feature = example[name]
if dtype == "text":
text += feature
elif dtype == "token_id":
token_id += feature
else:
if name not in tabular_inputs:
tabular_inputs[name] = [feature]
else:
tabular_inputs[name].append(feature)
if text:
texts.append(text)
if token_id:
token_id = torch.LongTensor(token_id)
token_ids.append(token_id)
for name in tabular_inputs:
tabular_inputs[name] = torch.FloatTensor(tabular_inputs[name])
if texts:
tokenized = tokenizer(texts, return_tensors="pt", padding=True)
output["input_ids"] = tokenized["input_ids"]
output["attention_mask"] = tokenized["attention_mask"]
if token_ids:
input_ids = pad_sequence(token_ids, batch_first=True, padding_value=pad_token_id)
attention_mask = (input_ids != pad_token_id).type(torch.int)
output["input_ids"] = input_ids
output["attention_mask"] = attention_mask
output["tabular_inputs"] = tabular_inputs
output["labels"] = torch.LongTensor(labels)
return output
data_loader = DataLoader(dataset_train, batch_size=2, collate_fn=text_tabular_collate_fn)
batch = next(iter(data_loader))
batch
Model¶
The model architecture we'll be implementing looks something along the lines of:
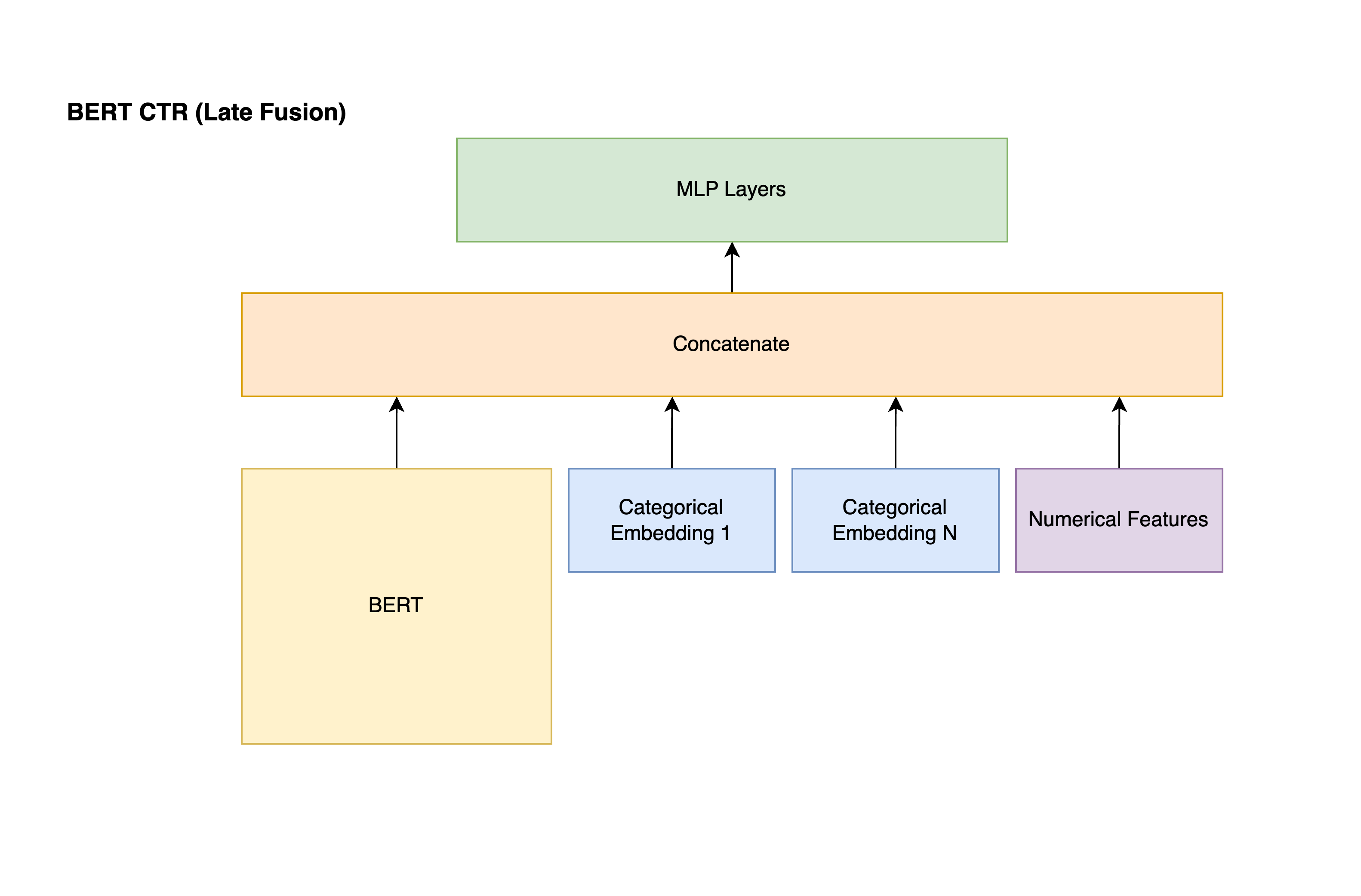
- Feeding textual input through BERT style transformer block, converting categorical features into a low dimensonal embedding, packing all of our numerical features together.
- The output from 3 different field groups are concatenated together before feeding them into subsequent feed forward layers.
def get_mlp_layers(input_dim: int, mlp_config):
"""
Construct MLP, a.k.a. Feed forward layers based on input config.
Parameters
----------
input_dim :
Input dimension for the first layer.
mlp_config : list of dictionary with mlp spec.
An example is shown below, the only mandatory parameter is hidden size.
```
[
{
"hidden_size": 1024,
"dropout_p": 0.1,
"activation_function": "ReLU",
"activation_function_kwargs": {},
"normalization_function": "LayerNorm"
"normalization_function_kwargs": {"eps": 1e-05}
}
]
```
Returns
-------
nn.Sequential :
Sequential layer converted from input mlp_config. If mlp_config
is None, then this returned value will also be None.
current_dim :
Dimension for the last layer.
"""
if mlp_config is None:
return None, input_dim
layers = []
current_dim = input_dim
for config in mlp_config:
hidden_size = config["hidden_size"]
dropout_p = config.get("dropout_p", 0.0)
activation_function = config.get("activation_function")
activation_function_kwargs = config.get("activation_function_kwargs", {})
normalization_function = config.get("normalization_function")
normalization_function_kwargs = config.get("normalization_function_kwargs", {})
linear = nn.Linear(current_dim, hidden_size)
layers.append(linear)
if normalization_function:
normalization = getattr(nn, normalization_function)(hidden_size, **normalization_function_kwargs)
layers.append(normalization)
if activation_function:
activation = getattr(nn, activation_function)(**activation_function_kwargs)
layers.append(activation)
if dropout_p > 0.0:
dropout = nn.Dropout(p=dropout_p)
layers.append(dropout)
current_dim = hidden_size
return nn.Sequential(*layers), current_dim
The next code block involves defining a config and model class following huggingface transformer's class structure [3]. This allows us to leverage its Trainer class for training and evaluating our models instead of writing custom training loops.
class TextTabularModelConfig(PretrainedConfig):
model_type = "text_tabular"
def __init__(
self,
features_config=None,
mlp_config=None,
num_labels=2,
model_name="distilbert-base-uncased",
pretrained_model_config=None,
use_pretrained=True,
**kwargs
):
super().__init__(**kwargs)
self.features_config = features_config
self.mlp_config = mlp_config
self.num_labels = num_labels
self.model_name = model_name
self.use_pretrained = use_pretrained
self.pretrained_model_config = pretrained_model_config
def mean_pool(last_hidden_state, attention_mask):
"""
Perform mean pooling over sequence len dimension, exclude ones that are attention masked.
Parameters
----------
last_hidden_state : tensor
Size of [batch_size, sequence_len, hidden dimension]
attention_mask : tensor
Size of [batch size, sequence_len]
Returns
-------
embedding : tensor
Size of [batch size, hidden dimension]
"""
# [..., None] is the same as unsqueeze last dimension
last_hidden_masked = last_hidden_state.masked_fill(~attention_mask.unsqueeze(dim=-1).bool(), 0.0)
embedding = last_hidden_masked.sum(dim=1) / attention_mask.sum(dim=1).unsqueeze(dim=-1)
return embedding
class TextTabularModel(PreTrainedModel):
config_class = TextTabularModelConfig
def __init__(self, config):
super().__init__(config)
self.config = config
if config.use_pretrained:
self.bert = AutoModel.from_pretrained(config.model_name)
else:
bert_config = AutoConfig.from_pretrained(config.model_name, **config.pretrained_model_config)
self.bert = AutoModel.from_config(bert_config)
self.categorical_embeddings, categorical_dim, numerical_dim = self.init_tabular_parameters(
config.features_config
)
# note, different pre-trained models might have different attribute name for hidden dimension
text_hidden_dim = self.bert.config.dim
mlp_hidden_dim = text_hidden_dim + categorical_dim + numerical_dim
self.mlp, output_dim = get_mlp_layers(mlp_hidden_dim, config.mlp_config)
self.head = nn.Linear(output_dim, config.num_labels)
def forward(self, input_ids, attention_mask, tabular_inputs, labels=None):
last_hidden_state = self.bert(input_ids, attention_mask).last_hidden_state
text_embedding = mean_pool(last_hidden_state, attention_mask)
categorical_inputs, numerical_inputs = self.create_tabular_inputs(
tabular_inputs,
self.config.features_config
)
if len(categorical_inputs) > 0 and len(numerical_inputs) > 0:
text_tabular_inputs = torch.cat([text_embedding, categorical_inputs, numerical_inputs], dim=-1)
elif len(categorical_inputs) > 0:
text_tabular_inputs = torch.cat([text_embedding, categorical_inputs], dim=-1)
elif len(numerical_inputs) > 0:
text_tabular_inputs = torch.cat([text_embedding, numerical_inputs], dim=-1)
mlp_outputs = self.mlp(text_tabular_inputs)
logits = self.head(mlp_outputs)
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits, labels)
# at the bare minimum, we need to return loss as well as logits
# for both training and evaluation
return loss, F.softmax(logits, dim=-1)
def create_tabular_inputs(self, tabular_inputs, features_config):
numerical_inputs = []
categorical_inputs = []
for name, config in features_config.items():
if config["dtype"] == "categorical":
feature_name = f"{name}_embedding"
share_embedding = config.get("share_embedding")
if share_embedding:
feature_name = f"{share_embedding}_embedding"
embedding = self.categorical_embeddings[feature_name]
features = tabular_inputs[name].type(torch.long)
embed = embedding(features)
categorical_inputs.append(embed)
elif config["dtype"] == "numerical":
features = tabular_inputs[name].type(torch.float32)
if len(features.shape) == 1:
features = features.unsqueeze(dim=1)
numerical_inputs.append(features)
if numerical_inputs:
numerical_inputs = torch.cat(numerical_inputs, dim=-1)
if categorical_inputs:
categorical_inputs = torch.cat(categorical_inputs, dim=-1)
return categorical_inputs, numerical_inputs
def init_tabular_parameters(self, features_config):
embeddings = {}
categorical_dim = 0
numerical_dim = 0
for name, config in features_config.items():
if config["dtype"] == "categorical":
# create new embedding layer for categorical features if share_embedding is None
share_embedding = config.get("share_embedding")
if share_embedding:
share_embedding_config = tabular_features_config[share_embedding]
embedding_size = share_embedding_config["embedding_size"]
else:
embedding_size = config["embedding_size"]
embedding = nn.Embedding(config["vocab_size"], embedding_size)
embedding_name = f"{name}_embedding"
embeddings[embedding_name] = embedding
categorical_dim += embedding_size
elif config["dtype"] == "numerical":
numerical_dim += 1
return nn.ModuleDict(embeddings), categorical_dim, numerical_dim
mlp_config = [
{
"hidden_size": 1024,
"dropout_p": 0.1,
"activation_function": "ReLU",
"normalization_function": "LayerNorm"
},
{
"hidden_size": 512,
"dropout_p": 0.1,
"activation_function": "ReLU",
"normalization_function": "LayerNorm"
},
{
"hidden_size": 256,
"dropout_p": 0.1,
"activation_function": "ReLU",
"normalization_function": "LayerNorm"
}
]
pretrained_model_config = {
"vocab_size": vocab_size,
"n_layers": n_layers,
"pad_token_id": pad_token_id
}
text_tabular_config = TextTabularModelConfig(
features_config=features_config,
mlp_config=mlp_config,
pretrained_model_config=pretrained_model_config,
use_pretrained=False
)
text_tabular_model = TextTabularModel(text_tabular_config)
print("number of parameters: ", text_tabular_model.num_parameters())
text_tabular_model
# a quick test on a sample batch to ensure model forward pass runs
output = text_tabular_model(**batch)
output
Rest of the code block defines boilerplate code for leveraging huggingface transformer's Trainer, as well as defining a compute_metrics function for calculating standard binary classification related metrics.
We'll also train a AutoModelForSequenceClassification model as our baseline. This allows us to compare whether incorporating tabular features on top of text features will result in performance gains.
There're many ways tips and tricks for training our model in a transfer learning setting [7] [8] [9]. e.g.
- Two stage training. The model is first trained to convergence with a frozen encoder, then unfrozen and fine-tuned along with the entire model.
- Differential (a.k.a layer-wise) learning rate. The idea is to have different learning rates for different parts/layers of our model. Intuition behind this is initial layers in a pre-trained model likely have learned general features which we don't want to modify as much, hence we should be setting a smaller learning rate for those parts of the model.
def compute_metrics(eval_preds, round_digits: int = 3):
y_pred, y_true = eval_preds
y_score = y_pred[:, 1]
log_loss = round(metrics.log_loss(y_true, y_score), round_digits)
roc_auc = round(metrics.roc_auc_score(y_true, y_score), round_digits)
pr_auc = round(metrics.average_precision_score(y_true, y_score), round_digits)
return {
"roc_auc": roc_auc,
"pr_auc": pr_auc,
"log_loss": log_loss
}
# differential learning rate, lower learning rate for bert part
# of the network, given our bert is not a pre-trained model, we
# won't use layer-wise decreasing learning rate
bert_params = []
other_params = []
for name, param in text_tabular_model.named_parameters():
if "bert." in name:
bert_params.append(param)
else:
other_params.append(param)
optimizer = optim.AdamW([
{'params': bert_params, "lr": 0.0001},
{'params': other_params, "lr": 0.001}
])
os.environ["DISABLE_MLFLOW_INTEGRATION"] = "TRUE"
training_args = TrainingArguments(
output_dir="text_tabular",
num_train_epochs=2,
learning_rate=0.0001,
per_device_train_batch_size=64,
gradient_accumulation_steps=2,
fp16=True,
lr_scheduler_type="constant",
evaluation_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=2,
do_train=True,
load_best_model_at_end=True,
# we are collecting all tabular features into a single entry
# tabular_inputs during collate function, this is to prevent
# huggingface trainer from removing these features while processing
# our dataset
remove_unused_columns=False
)
trainer = Trainer(
text_tabular_model,
args=training_args,
data_collator=text_tabular_collate_fn,
train_dataset=dataset_train,
eval_dataset=dataset_test,
compute_metrics=compute_metrics,
optimizers=(optimizer, None)
)
# 0.709
train_output = trainer.train()
def text_collate_fn(batch):
"""
Use in conjunction with Dataloader's collate_fn for text data.
Returns
-------
batch : dict
Dictionary with 3 primary keys: input_ids, attention_mask, and labels. e.g.
{
'input_ids': tensor([[116438, 65110]]),
'attention_mask': tensor([[1, 1]]),
'labels': tensor([0, 0])
}
"""
output = {}
labels = []
texts = []
token_ids = []
for example in batch:
label = example["label"]
labels.append(label)
text = ""
token_id = []
for name, config in features_config.items():
dtype = config["dtype"]
feature = example[name]
if dtype == "text":
text += feature
elif dtype == "token_id":
token_id += feature
else:
continue
if text:
texts.append(text)
if token_id:
token_id = torch.LongTensor(token_id)
token_ids.append(token_id)
if texts:
tokenized = tokenizer(texts, return_tensors="pt", padding=True)
output["input_ids"] = tokenized["input_ids"]
output["attention_mask"] = tokenized["attention_mask"]
if token_ids:
input_ids = pad_sequence(token_ids, batch_first=True, padding_value=pad_token_id)
attention_mask = (input_ids != pad_token_id).type(torch.int)
output["input_ids"] = input_ids
output["attention_mask"] = attention_mask
output["labels"] = torch.LongTensor(labels)
return output
bert_config = AutoConfig.from_pretrained(model_name, **pretrained_model_config)
text_model = AutoModelForSequenceClassification.from_config(bert_config)
print("number of parameters: ", text_model.num_parameters())
trainer = Trainer(
text_model,
args=training_args,
data_collator=text_collate_fn,
train_dataset=dataset_train,
eval_dataset=dataset_test,
compute_metrics=compute_metrics
)
train_output = trainer.train()
From the experiment above, including some tabular/structure data into the model out-performs the text only variant by 300 basis point (1 absolute percent) 0.709 versus 0.679 on this particular preprocessed dataset. The gap will most likely widen even more if we devote more effort into feature engineering additional features out of the raw data.
End Notes¶
Recent works such as DeText [4], CTR-BERT [5], TwinBERT [6] also explored leveraging BERT for click through rate (CTR) problems. Some common themes from these works includes:
- Cross architecture knowledge distillation process, where large cross attention teacher are distilled to smaller bi-encoder student. Both teacher and student incorporates tabular features via late fusion manner. One of the considerations in building industry scale CTR prediction model is achieving fast real time inference. Bi-encoder model address this by decoupling the encoding process for queries and documents. This enables one of the computationally expensive BERT-based document encoders to be pre-computed offline and cached (cache can be refreshed on a periodic basis, e.g. daily). During run time, the inference cost reduces to a query encoder, tabular features, as well as a late fusion cross layer such as MLP (multi-layer perceptron).
- N-pass ranker. To leverage cross encoder in production setting, we can have a N-pass ranker. i.e. A more lightweight ranker that can quickly weed out a large amounts of irrelevant document, while applying the more performant but computationally expensive ranker on a smaller subset of the documents.
- In domain pre-training. A common practice of using pre-trained BERT model is to directly leverage the public checkpoint that have been trained on general domain such as Wikipedia, and fine-tune it on our specific task. Continuing to pre-train on in-domain data using un/self-supervised learning loss like MLM (Masked Language Modeling) proves to be effective for vertical specific applications.
Reference¶
- [1] KDD Cup 2012, Track 2 - Predict the click-through rate of ads given the query and user information.
- [2] Haitao Mao, Dawei Yin, Xiaokai Chu, et al. - A Large Scale Search Dataset for Unbiased Learning to Rank (2022)
- [3] How to Incorporate Tabular Data with HuggingFace Transformers
- [4] Weiwei Guo, Xiaowei Liu, Sida Wang, Huiji Gao, Ananth Sankar, Zimeng Yang, Qi Guo, Liang Zhang, Bo Long, Bee-Chung Chen, Deepak Agarwal - DeText: A Deep Text Ranking Framework with BERT (2020)
- [5] Aashiq Muhamed, et al. - CTR-BERT: Cost-effective knowledge distillation for billion-parameter teacher models (2021)
- [6] Wenhao Lu, Jian Jiao, Ruofei Zhang - TwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval (2022)
- [7] Chi Sun, Xipeng Qiu, Yige Xu, Xuanjing Huang - How to Fine-Tune BERT for Text Classification? (2019)
- [8] Getting the most out of Transfer Learning
- [9] Going the extra mile, lessons learnt from Kaggle on how to train better NLP models (Part II)