# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', 'notebook_format'))
from formats import load_style
load_style(plot_style = False)
os.chdir(path)
import numpy as np
import matplotlib.pyplot as plt
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
import tensorflow as tf
from keras.datasets import mnist
from keras.utils import np_utils
%watermark -a 'Ethen' -d -t -v -p numpy,matplotlib,keras,tensorflow
Tensorflow¶
TensorFlow provides multiple APIs. The lowest level API--TensorFlow Core-- provides you with complete programming control. We recommend TensorFlow Core for machine learning researchers and others who require fine levels of control over their models
Hello World¶
We can think of TensorFlow Core programs as consisting of two discrete sections:
- Building the computational graph.
- Running the computational graph.
# note that this is simply telling tensorflow to
# create a constant operation, nothing gets
# executed until we start a session and run it
hello = tf.constant('Hello, TensorFlow!')
hello
# start the session and run the graph
with tf.Session() as sess:
print(sess.run(hello))
We can think of tensorflow as a system to define our computation, and using the operation that we've defined it will construct a computation graph (where each operation becomes a node in the graph). The computation graph that we've defined will not be run unless we give it some context and explicitly tell it to do so. In this case, we create the Session that encapsulates the environment in which the objects are evaluated (execute the operations that are defined in the graph).
Consider another example that simply add and multiply two constant numbers.
a = tf.constant(2.0, tf.float32)
b = tf.constant(3.0) # also tf.float32 implicitly
c = a + b
with tf.Session() as sess:
print('mutiply: ', sess.run(a * b))
print('add: ', sess.run(c)) # note that we can define the add operation outside
print('add: ', sess.run(a + b)) # or inside the .run()
The example above is not especially interesting because it always produces a constant result. A graph can be parameterized to accept external inputs, known as placeholders. Think of it as the input data we would give to machine learning algorithm at some point.
We can do the same operation as above by first defining a placeholder (note that we must specify the data type). Then feed in values using feed_dict when we run it.
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
# define some operations
add = a + b
mul = a * b
with tf.Session() as sess:
print('mutiply: ', sess.run(mul, feed_dict = {a: 2, b: 3}))
print('add: ', sess.run(add, feed_dict = {a: 2, b: 3}))
Some matrix operations are the same compared to numpy. e.g.
c = np.array([[3.,4], [5.,6], [6.,7]])
print(c)
print(np.mean(c, axis = 1))
print(np.argmax(c, axis = 1))
with tf.Session() as sess:
result = sess.run(tf.reduce_mean(c, axis = 1))
print(result)
print(sess.run(tf.argmax(c, axis = 1)))
The functionality of numpy.mean and tensorflow.reduce_mean are the same. When axis argument parameter is 1, it computes mean across (3,4) and (5,6) and (6,7), so 1 defines across which axis the mean is computed (axis = 1, means the operation is along the column, so it will compute the mean for each row). When it is 0, the mean is computed across(3,5,6) and (4,6,7), and so on. The same can be applied to argmax which returns the index that contains the maximum value along an axis.
Linear Regression¶
We'll start off by writing a simple linear regression model. To do so, we first need to understand the difference between tf.Variable and tf.placeholder.
Stackoverflow. The difference is that with
tf.Variableyou have to provide an initial value when you declare it. Withtf.placeholderyou don't have to provide an initial value and you can specify it at run time with thefeed_dictargument insideSession.run. In short, we will usetf.Variablefor trainable variables such as weights (W) and biases (B) for our model. On the other hand,tf.placeholderis used to feed actual training examples.
Also note that, constants are automatically initialized when we call tf.constant, and their value can never change. By contrast, variables are not initialized when we call tf.Variable. To initialize all the variables in a TensorFlow program, we must explicitly call a special operation called tf.global_variables_initializer(). Things will become clearer with the example below.
# Parameters
learning_rate = 0.01 # learning rate for the optimizer (gradient descent)
n_epochs = 1000 # number of iterations to train the model
display_epoch = 100 # display the cost for every display_step iteration
# make up some trainig data
X_train = np.asarray([3.3, 4.4, 5.5, 6.71, 6.93, 4.168, 9.779, 6.182, 7.59,
2.167, 7.042, 10.791, 5.313, 7.997, 5.654, 9.27, 3.1], dtype = np.float32)
y_train = np.asarray([1.7, 2.76, 2.09, 3.19, 1.694, 1.573, 3.366, 2.596, 2.53,
1.221, 2.827, 3.465, 1.65, 2.904, 2.42, 2.94, 1.3], dtype = np.float32)
# placeholder for the input data
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# give the model's parameter a randomized initial value
W = tf.Variable(np.random.randn(), tf.float32, name = 'weight')
b = tf.Variable(np.random.randn(), tf.float32, name = 'bias')
# Construct the formula for the linear model
# we can also do
# pred = tf.add(tf.multiply(X, W), b)
pred = W * X + b
# we then define the loss function that the model is going to optimize on,
# here we use the standard mean squared error, which is sums the squares of the
# prediction and the true y divided by the number of observations, note
# that we're computing the difference between the prediction and the y label
# from the placeholder
cost = tf.reduce_mean(tf.pow(pred - Y, 2))
# after defining the model structure and the function to optimize on,
# tensorflow provides several optimizers that can do optimization task
# for us, the simplest one being gradient descent
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(cost)
# initializing the variables
init = tf.global_variables_initializer()
# change default figure and font size
plt.rcParams['figure.figsize'] = 8, 6
plt.rcParams['font.size'] = 12
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Fit on all the training data
feed_dict = {X: X_train, Y: y_train}
for epoch in range(n_epochs):
sess.run(train, feed_dict = feed_dict)
# Display logs per epoch step
if (epoch + 1) % display_epoch == 0:
# run the cost to obtain the value for the cost function at each step
c = sess.run(cost, feed_dict = feed_dict)
print("Epoch: {}, cost: {}".format(epoch + 1, c))
print("Optimization Finished!")
c = sess.run(cost, feed_dict = feed_dict)
weight = sess.run(W)
bias = sess.run(b)
print("Training cost: {}, W: {}, b: {}".format(c, weight, bias))
# graphic display
plt.plot(X_train, y_train, 'ro', label = 'Original data')
plt.plot(X_train, weight * X_train + bias, label = 'Fitted line')
plt.legend()
plt.show()

MNIST Using Softmax¶
MNIST is a simple computer vision dataset. It consists of images of handwritten digits like these:
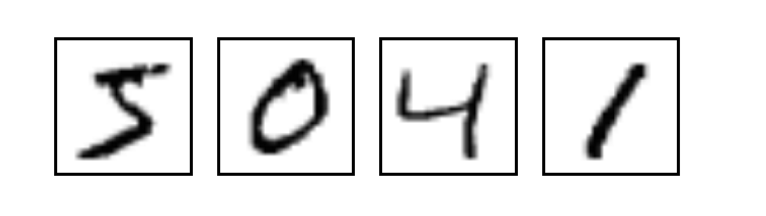
Each image is 28 pixels by 28 pixels, which is essentially a $28 \times 28$ array of numbers. To use it in a context of a machine learning problem, we can flatten this array into a vector of $28 \times 28 = 784$, this will be the number of features for each image. It doesn't matter how we flatten the array, as long as we're consistent between images. Note that, flattening the data throws away information about the 2D structure of the image. Isn't that bad? Well, the best computer vision methods do exploit this structure. But the simple method we will be using here, a softmax regression (defined below), won't.
The dataset also includes labels for each image, telling us the each image's label. For example, the labels for the above images are 5, 0, 4, and 1. Here we're going to train a softmax model to look at images and predict what digits they are. The possible label values in the MNIST dataset are numbers between 0 and 9, hence this will be a 10-class classification problem.
n_class = 10
n_features = 784 # mnist is a 28 * 28 image
# load the dataset and some preprocessing step that can be skipped
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, n_features)
X_test = X_test.reshape(10000, n_features)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# images takes values between 0 - 255, we can normalize it
# by dividing every number by 255
X_train /= 255
X_test /= 255
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices (one-hot encoding)
# note: you HAVE to to this step
Y_train = np_utils.to_categorical(y_train, n_class)
Y_test = np_utils.to_categorical(y_test , n_class)
In the following code chunk, we define the overall computational graph/structure for the softmax classifier using the cross entropy cost function as the objective. Recall that the formula for this function can be denoted as:
$$L = -\sum_i y'_i \log(y_i)$$Where y is our predicted probability distribution, and y′ is the true distribution.
# define some global variables
learning_rate = 0.1
n_iterations = 400
# define the input and output
# here None means that a dimension can be of any length,
# which is what we want, since the number of observations
# we have can vary;
# note that the shape argument to placeholder is optional,
# but it allows TensorFlow to automatically catch bugs stemming
# from inconsistent tensor shapes
X = tf.placeholder(tf.float32, [None, n_features])
y = tf.placeholder(tf.float32, [None, n_class])
# initialize both W and b as tensors full of zeros.
# these are parameters that the model is later going to learn,
# Notice that W has a shape of [784, 10] because we want to multiply
# the 784-dimensional image vectors by it to produce 10-dimensional
# vectors of evidence for the difference classes. b has a shape of [10]
# so we can add it to the output.
W = tf.Variable(tf.zeros([n_features, n_class]))
b = tf.Variable(tf.zeros([n_class]))
# to define the softmax classifier and cross entropy cost
# we can do the following
# matrix multiplication using the .matmul command
# and add the softmax output
output = tf.nn.softmax(tf.matmul(X, W) + b)
# cost function: cross entropy, the reduce mean is simply the average of the
# cost function across all observations
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(output), axis = 1))
# but for numerical stability reason, the tensorflow documentation
# suggests using the following function
output = tf.matmul(X, W) + b
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y, logits = output))
Now that we defined the structure of our model, we'll:
- Define a optimization algorithm the train it. In this case, we ask TensorFlow to minimize our defined cross_entropy cost using the gradient descent algorithm with a learning rate of 0.5. There are also other off the shelf optimizers that we can use that are faster for more complex models.
- We'll also add an operation to initialize the variables we created
- Define helper "function" to evaluate the prediction accuracy
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
init = tf.global_variables_initializer()
# here we're return the predicted class of each observation using argmax
# and see if the ouput (prediction) is equal to the target variable (y)
# since equal is a boolean type tensor, we cast it to a float type to compute
# the actual accuracy
correct_prediction = tf.equal(tf.argmax(y, axis = 1), tf.argmax(output, axis = 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
Now it's time to run it. During each step of the loop, we get a "batch" of one hundred random data points (defined by batch_size) from our training set. We run train_step feeding in the batches data to replace the placeholders.
Using small batches of random data is called stochastic training -- in this case, stochastic gradient descent. Ideally, we'd like to use all our data for every step of training because that would give us a better sense of what we should be doing, but that's expensive. So, instead, we use a different subset every time. Doing this is cheap and has much of the same benefit.
with tf.Session() as sess:
# initialize the variable, train the "batch" gradient descent
# for a specified number of iterations and evaluate on accuracy score
# remember the key to the feed_dict dictionary must match the variable we use
# as the placeholder for the data in the beginning
sess.run(init)
for i in range(n_iterations):
# X_batch, y_batch = mnist.train.next_batch(batch_size)
_, acc = sess.run([train_step, accuracy], feed_dict = {X: X_train, y: Y_train})
# simply prints the training data's accuracy for every n iteration
if i % 50 == 0:
print(acc)
# after training evaluate the accuracy on the testing data
acc = sess.run(accuracy, feed_dict = {X: X_train, y: Y_train})
print('test:', acc)
Notice that we did not have to worry about computing the gradient to update the model, the nice thing about Tensorflow is that, once we've defined the structure of our model it has the capability to automatically differentiate mathematical expressions. This means we no longer need to compute the gradients ourselves! In this example, our softmax classifier obtained pretty nice result around 90%. But we can certainly do better with more advanced techniques such as convolutional deep learning.