Table of Contents
# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style = 'custom2.css', plot_style = False)
os.chdir(path)
import os
import warnings
import numpy as np
import tensorflow as tf
from time import time
from keras.datasets import mnist
from keras.utils import to_categorical
# 1. magic so that the notebook will reload external python modules
# 2. magic to print version
%load_ext autoreload
%autoreload 2
%load_ext watermark
%watermark -a 'Ethen' -d -t -v -p keras,numpy,tensorflow
RNN (Recurrent Neural Network)¶
The idea behind RNN is to make use of sequential information that exists in our dataset. In feed forward neural network, we assume that all inputs and outputs are independent of each other. But for some tasks, this might not be the best way to tackle the problem. For example, in Natural Language Processing (NLP) applications, if we wish to predict the next word in a sentence (one business application of this is Swiftkey), we could imagine that knowing the word that comes before it can come in handy. RNNs are called recurrent because they perform the same task for every element of a sequence (sharing the weights), with the output being depended on the previous computations. Another way to think about RNNs is that they have a "memory" which captures information about what has been calculated so far.
The following diagram shows what a typical RNN-type network looks like:
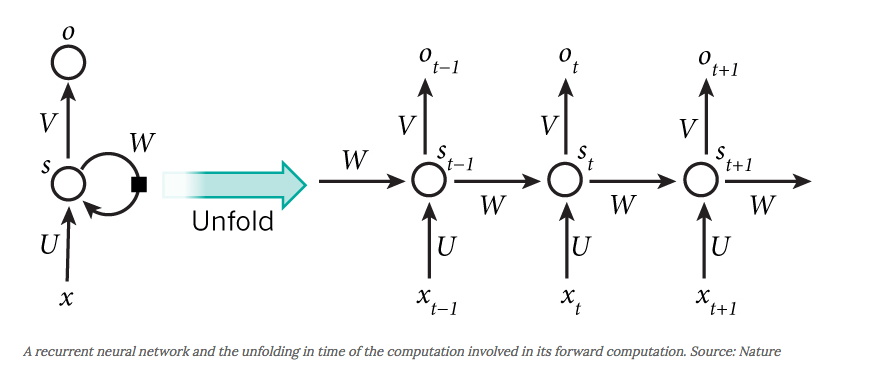
We can think of RNN-type networks as networks with loops. During the forward stage, RNN is being unrolled/unfolded into a full network. By unrolling, we are referring to the fact that we will be performing the computation for the complete sequence. e.g.
- If the input sequence is a sentence of 5 words, the network (RNN cell) would be unrolled into a 5-copies, one copy for each word.
- If we were to consider every image's row as a sequence of pixels. For example MNIST image shape is 28*28 pixels, we would then be handling 28 time steps each having a feature size of 28 for every sample.
The formula for the computation happening in a RNN cell are as follow:
- $x_t$: The input at time step $t$, taking the size of the feature space, e.g. one-hot vector or embedding of the input word.
- $s_t$: The hidden state at time step $t$. This is essentially the "memory" of the network $s_t$ is calculated based on the previous hidden state and the input at the current step. $s_t = f(U x_t + W s_{t - 1})$. The function $f$ is usually a nonlinearity function such as tanh or relu. At the first step, $s_t$ is usually initialized to all zeros in order to calculate the first hidden state.
- $o_t$: is the output at step $t$. For example, if we wish to predict the most probable word in a sentence, i.e. a classification problem then the computation can be a linear layer followed by a softmax $o_t = softmax(V s_t)$.
A few things to note:
- Unlike a traditional deep neural network, which uses different parameters at each layer, a RNN shares the same parameters ($U$, $V$, $W$ above) across all steps. This reflects the fact that we are performing the same task at each step, just with different inputs, such design greatly reduces the total number of parameters we need to learn.
- The above diagram has outputs at each time step, but depending on the task this may not be necessary. For example, when in basic sequence classification, we can assume the last hidden state has accumulated the information representing the entire sequence. A concrete example might be when predicting the sentiment of a sentence we may only care about the final output, not the sentiment after each word.
Implementation¶
We'll use the MNIST dataset as our example dataset as it requires little preprocessing and let us focus on the algorithm at hand. Using the MNIST data from tensorflow.examples.tutorials.mnist import input_data will raise a lot of deprecation warnings, thus we leverage keras' mnist data and implement a class to generate batches of data from it.
class DataLoader:
"""Container for a dataset."""
def __init__(self, images, labels, num_classes):
if images.shape[0] != labels.shape[0]:
raise ValueError('images.shape: %s labels.shape: %s' % (images.shape, labels.shape))
self.num_classes = num_classes
self._images = images
self._labels = labels
self._num_examples = images.shape[0]
self._epochs_completed = 0
self._index_in_epoch = 0
def next_batch(self, batch_size, shuffle = True):
"""Return the next `batch_size` examples from this data set."""
# shuffle for the first epoch
start = self._index_in_epoch
if self._epochs_completed == 0 and start == 0 and shuffle:
self._shuffle_images_and_labels()
if start + batch_size > self._num_examples:
# retrieve the rest of the examples that does not add up to a full batch size
self._epochs_completed += 1
rest_num_examples = self._num_examples - start
rest_images = self._images[start:self._num_examples]
rest_labels = self._labels[start:self._num_examples]
if shuffle:
self._shuffle_images_and_labels()
# complete the batch size from the next epoch
start = 0
self._index_in_epoch = batch_size - rest_num_examples
end = self._index_in_epoch
new_images = self._images[start:end]
new_labels = self._labels[start:end]
images = np.concatenate((rest_images, new_images), axis = 0)
labels = np.concatenate((rest_labels, new_labels), axis = 0)
return images, to_categorical(labels, self.num_classes)
else:
self._index_in_epoch += batch_size
end = self._index_in_epoch
return (self._images[start:end],
to_categorical(self._labels[start:end], self.num_classes))
def _shuffle_images_and_labels(self):
permutated = np.arange(self._num_examples)
np.random.shuffle(permutated)
self._images[permutated]
self._labels[permutated]
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# images takes values between 0 - 255, we can normalize it
# by dividing every number by 255
X_train /= 255
X_test /= 255
print('mnist data shape: ', X_train.shape)
It can be helpful to write down the dimensions of our input and weights. Here our MNIST image's feature size is 28, the number of possible output/target is 10 and assume we've set our hidden layer size is 128 (this is a hyperparameter that we can tune, increasing it makes the "memory" capable of memorizing more complex patterns, but also results in additional computation and raise the risk of overfitting). Then we have:
- $x_t \in \mathbb{R}^{28}$
- $o_t \in \mathbb{R}^{10}$
- $s_t \in \mathbb{R}^{128}$
- $U \in \mathbb{R}^{28 \times 128}$
- $W \in \mathbb{R}^{128 \times 128}$
- $V \in \mathbb{R}^{128 \times 10}$
# Define some parameters
element_size = 28
time_steps = 28
num_classes = 10
batch_size = 128
hidden_layer_size = 128
# example of generating a batch of data using the
# DataLoader class
data_loader = DataLoader(X_train, Y_train, num_classes)
X_batch, y_batch = data_loader.next_batch(batch_size)
print('label shape: ', y_batch.shape)
print('data shape: ', X_batch.shape)
# the first dimension holds the batch size
inputs = tf.placeholder(tf.float32, shape = [None, time_steps, element_size], name = 'inputs')
labels = tf.placeholder(tf.float32, shape = [None, num_classes], name = 'labels')
# Wx = U from the diagram, input weight
# Wh = W from the diagram, weight hidden
# bx = bias term for the input weight
Wx = tf.Variable(tf.zeros([element_size, hidden_layer_size]))
Wh = tf.Variable(tf.zeros([hidden_layer_size, hidden_layer_size]))
bx = tf.Variable(tf.zeros([hidden_layer_size]))
def rnn_step(previous_hidden_state, x):
current_hidden_state = tf.tanh(
tf.matmul(previous_hidden_state, Wh) +
tf.matmul(x, Wx) + bx)
return current_hidden_state
# the original input batch's shape is of [batch_size, time_steps and element_size]
# we permutate the order to [time_steps, batch_size, element_size]. The time_steps
# is put up front in order to leverage tf.scan's functionality
input_reshaped = tf.transpose(inputs, perm = [1, 0, 2])
# we initialize a hidden state to begin with and apply the rnn steps using tf.scan,
# which repeatedly applies a callable to our inputs
initial_hidden = tf.zeros([batch_size, hidden_layer_size])
all_hidden_states = tf.scan(
rnn_step, input_reshaped, initializer = initial_hidden, name = 'hidden_states')
# if we do a fake run, we can see that the output at this point is the hidden state
# for every time step [time_steps, batch_size, hidden_layer_size]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
data_loader = DataLoader(X_train, Y_train, num_classes)
X_batch, y_batch = data_loader.next_batch(batch_size)
temp = sess.run(all_hidden_states, feed_dict = {inputs: X_batch, labels: y_batch})
print(temp.shape)
# output linear layer's weight and bias, V from the diagram
Wl = tf.Variable(tf.truncated_normal(
[hidden_layer_size, num_classes],
mean = 0, stddev = .01))
bl = tf.Variable(tf.truncated_normal(
[num_classes], mean = 0,stddev = .01))
# apply linear layer to state vector;
# instead of calculating the output vector for every hidden state,
# in basic classification, we can assume the last hidden state
# has accumulated the information representing the entire sequence
output = tf.matmul(all_hidden_states[-1], Wl) + bl
learning_rate = 0.001
# specify the cross entropy loss, the optimizer to train the loss,
# the accuracy measurement
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits = output, labels = labels))
train_step = tf.train.RMSPropOptimizer(learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(labels, axis = 1), tf.argmax(output, axis = 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) * 100
X_test_batch = X_test[:batch_size]
y_test_batch = to_categorical(Y_test[:batch_size], num_classes)
data_loader = DataLoader(X_train, Y_train, num_classes)
epochs = 5000
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
start = time()
for i in range(epochs):
X_batch, y_batch = data_loader.next_batch(batch_size)
sess.run(train_step, feed_dict = {inputs: X_batch, labels: y_batch})
if i % 1000 == 0:
acc, loss = sess.run([accuracy, cross_entropy],
feed_dict = {inputs: X_batch, labels: y_batch})
print('Iter ' + str(i) + ', Minibatch Loss =',
'{:.6f}'.format(loss) + ', Training Accuracy =',
'{:.5f}'.format(acc))
print('Optimization finished!')
acc_test = sess.run(accuracy, feed_dict = {inputs: X_test_batch, labels: y_test_batch})
print('Test Accuracy: ', acc_test)
print('elapse time: ', time() - start)