# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
import os
import torch
import evaluate
import datasets
import collections
import transformers
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
from tqdm.auto import tqdm
from time import perf_counter
from torch.utils.data import DataLoader
from datasets import (
load_dataset,
disable_progress_bar
)
from transformers import (
pipeline,
Trainer,
TrainingArguments,
AutoTokenizer,
AutoModelForQuestionAnswering,
DataCollatorWithPadding,
EarlyStoppingCallback,
IntervalStrategy
)
device = "cuda" if torch.cuda.is_available() else "cpu"
cache_dir = None
%watermark -a 'Ethen' -d -u -iv
Fine Tuning Pre-trained Encoder on Question Answer Task¶
In this document, we'll be going over how to train an extractive question and answer model using a pre-trained language encoder model via huggingface's transformers library. Throughout this process, we'll also:
- Introduce some advanced tokenizer functionalities that are needed for token level based tasks such as question answering.
- Explain some of the pre-processing and post-processing that are needed for question and answering task.
There are many different forms of question answering, but the one we will be discussing today is termed open book extractive question answering. Open book allows our model to retrieve relevant information from some context, similar to open book exams where students can refer to their books for relevant information during an exam, in this setup, our model can look up information from external sources. Extractive means our model will extract the most relevant span of texts or snippets from these contexts to answer incoming question. Although span based answers are more constrained compared to free form answers, they come with the benefit of being easier to evaluate.
Similar to a lot modern recommendation systems out there, there are three main components to these type of systems: a vector database for storing our data encoded in vector representation, a retrieval model for efficiently retrieving top-N context, lastly a reader model that identifies the span of text from a range of context. In this document, we'll be focusing on the reader model part.
To piggyback on modern today's pre-trained language model for reader model fine-tuning. We need two inputs: question and context, as well as two labels identifying answer's start and end positions within that context. The following diagram depicts this notion very nicely [4].

Slightly more formally, after feeding our input sentence through an encoder layer and obtaining the embedding vector $\mathbf{h}^{(i)}$ for every $i_{th}$ token, we learn two additional weights, one for start position, $\mathbf{W}_s$ and the other for end position, $\mathbf{W}_e$. These two weights will be used to define: for each token, the probability distribution of belonging to start and end position: $\text{softmax}(\mathbf{h}^{(i)}\mathbf{W}_s)$, $\text{softmax}(\mathbf{h}^{(i)}\mathbf{W}_e)$
The dataset we'll be using is SQuAD (Standford Question Answering Dataset). This data contains a question, a context, and potentially answer. Where the answer to every question is a segment of text, a.k.a span, from a corresponding context. We can decide whether to experiment with SQuAD or SQuAD 2.0. SQuAD version 2.0 is a superset of the existing dataset containing unanswerable questions. This nature makes it more challenging to do well on version 2.0, as not only does the model need to identify correct answers, but also need to determine when no answer is supported by a given context and abstain from spitting out unreliable guesses.
# experiment with different public model checkpoints
model_checkpoint = "distilbert-base-uncased"
task_name = "squad" # "squad_v2"
datasets = load_dataset(task_name, cache_dir=cache_dir)
datasets
Printing out a sample format, hopefully field names are all quite self explanatory. The one thing that's worth clarifying is answer_start field contains starting character index of each answer inside the corresponding context.
datasets["train"][0]
Tokenizer¶
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, cache_dir=cache_dir)
After passing raw text through a tokenizer, a single word can be split into multiple tokens. e.g. in the example below, @huggingface is split into multiple tokens, @ hugging, and ##face. This can cause some issues for our token level labels, as our original label was mapped to a single word @huggingface. To resolve this, we'll need to use offsets mapping returned by the tokenizer, which gives us a tuple indicating each sub token's start and end position relative to the original token it was split from. For special tokens, offset mapping's start and end position will both be set to 0.
word = "@huggingface"
tokenized = tokenizer(word, return_offsets_mapping=True)
tokenized
def convert_id_to_string(tokenizer, input_ids):
strings = []
for input_id in input_ids:
string = tokenizer.convert_ids_to_tokens(input_id)
strings.append(string)
return strings
def convert_offset_mapping_to_string(tokenized, offset_mapping, word):
strings = []
for offset in offset_mapping:
start = offset[0]
end = offset[1]
if end != 0:
strings.append(word[start:end])
return strings
# excluding for special tokens, the two should be identical
strings = convert_id_to_string(tokenizer, tokenized["input_ids"])
print("input ids' string: ", strings)
strings = convert_offset_mapping_to_string(tokenizer, tokenized["offset_mapping"], word)
print("offset mapping string: ", strings)
Another specific preprocessing detail for question answering task is appropriate ways to deal with long documents. In many other tasks, we typically truncate documents that are longer than our model's maximum sequence/sentence length, but here, removing some parts of the context might result in losing a section of the document that contains our answer. To deal with this, we will allow one (long) example in our dataset to give several input features by turning on return_overflowing_tokens. Commonly referred to as chunks, each chunk's length will be shorter than the model's maximum length (configurable hyper-parameter). Also, just in case a particular answer lies at the point where we splitted a long context, we will allow some overlap between chunks/features controlled by a hyper-parameter doc_stride, sometimes commonly known as sliding window.
examples = [
"We are going to split this sentence",
"This sentence is longer, we are also going to split it"
]
tokenized = tokenizer(
examples,
truncation=True,
return_overflowing_tokens=True,
max_length=6,
stride=2
)
print("number of examples: ", len(examples))
print("number of tokenized features: ", len(tokenized["input_ids"]))
tokenized
Our two input sentences/examples has been split into 8 tokenized features. From the overflow_to_sample_mapping field, we can see which original example these 8 features map to.
# if we print out the batched input ids, we'll see each one
# of our sentences has been split to multiple chunks/features
for input_id, sample_mapping in zip(tokenized["input_ids"], tokenized["overflow_to_sample_mapping"]):
chunk = tokenizer.decode(input_id)
print("Chunk: ", chunk)
print("Orignal input: ", examples[sample_mapping])
Last thing we'll mention is the sequence_ids attribute. When feeding pairs of input to a tokenizer, we can use it to distinguish first and second portion of a given sentence. In question and answering this will be helpful for identifying whether the predicted answer's start and end position falls inside context portion of a given document, instead of question portion. If we look at a sample output, we'll notice that special tokens will be mapped to None, whereas our context, which is passed as the second part of our paired input will receive a value of 1.
tokenized = tokenizer(
["question section"],
["context section"]
)
tokenized.sequence_ids(0)
Upon introducing these advanced tokenizer usages, the next few code cell showcase how to put them in use and creates a function for preprocessing our question answer dataset into a format that's suited for downstream modeling. Note:
- When performing truncation, we should only truncate the context, never the question. Configured via
truncation="only_second" - Given that we split a single document into several chunks, it can happen that a given chunk doesn't contain a valid answer, in this case, we will set question answer task's label,
start_positionandend_position, to index 0 (special token[CLS]'s index). - We'll be padding every feature to maximum length, as most of the context will be reaching that threshold, there's no real benefit of performing dynamic padding.
# maximum length of a feature (question and context)
max_length = 384
# overlap between two part of the context
doc_stride = 128
def prepare_qa_train(examples):
"""Prepare training data, input features plus label for question answering dataset."""
answers = examples["answers"]
examples["question"] = [question.strip() for question in examples["question"]]
# Tokenize our examples with truncation and padding, but keep overflows using a stride.
# This results in one example potentially generating several features when a context is
# long, each of those features having a context that overlaps a bit the previous
# feature's context to prevent chopping off answer span.
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True,
return_offsets_mapping=True,
stride=doc_stride,
padding="max_length"
)
sample_mapping = tokenized_examples["overflow_to_sample_mapping"]
offset_mapping = tokenized_examples["offset_mapping"]
# We will label impossible answers with CLS token's index.
cls_index = 0
# start_positions and end_positions will be the labels for extractive question answering
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offset in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
sample_index = sample_mapping[i]
answer = answers[sample_index]
# if no answers are given, set CLS index as answer
if len(answer["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
start_char = answer["answer_start"][0]
end_char = start_char + len(answer["text"][0])
sequence_ids = tokenized_examples.sequence_ids(i)
# find the context's corresponding start and end token index
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# if answer is within the context offset, move the token_start_index and token_end_index
# to two ends of the answer else label it with cls index
offset_start_char = offset[token_start_index][0]
offset_end_char = offset[token_end_index][1]
if offset_start_char <= start_char and offset_end_char >= end_char:
while token_start_index < len(offset) and offset[token_start_index][0] <= start_char:
token_start_index += 1
start_position = token_start_index - 1
while offset[token_end_index][1] >= end_char:
token_end_index -= 1
end_position = token_end_index + 1
tokenized_examples["start_positions"].append(start_position)
tokenized_examples["end_positions"].append(end_position)
else:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
return tokenized_examples
We test our preprocessing function on a sample text to ensure our somewhat complicated preprocessing function works as expected, i.e. the start and end position of a tokenized answer matches the original un-tokenized version.
examples = datasets["train"][0:2]
answers = examples["answers"]
tokenized_examples = prepare_qa_train(examples)
start_positions = tokenized_examples["start_positions"]
end_positions = tokenized_examples["end_positions"]
for i, input_ids in enumerate(tokenized_examples["input_ids"]):
start = start_positions[i]
end = end_positions[i] + 1
string = tokenizer.decode(input_ids[start:end])
print("expected answer:", answers[i]["text"][0])
print("preprocessing answer:", string)
# prevents progress bar from flooding our document
disable_progress_bar()
tokenized_datasets = datasets.map(
prepare_qa_train,
batched=True,
remove_columns=datasets["train"].column_names,
num_proc=8
)
tokenized_datasets
Model¶
Upon preparing our dataset, fine-tuning a question answer model on top of pre-trained language model will be similar to other tasks, where we initialize a AutoModelForQuestionAnswering model, and follow the standard fine-tuning process.
model_name = model_checkpoint.split("/")[-1]
fine_tuned_model_checkpoint = f"{model_name}-fine_tuned-{task_name}"
if os.path.isdir(fine_tuned_model_checkpoint):
do_train = False
model = AutoModelForQuestionAnswering.from_pretrained(fine_tuned_model_checkpoint, cache_dir=cache_dir)
else:
do_train = True
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint, cache_dir=cache_dir)
os.environ['DISABLE_MLFLOW_INTEGRATION'] = 'TRUE'
args = TrainingArguments(
output_dir=fine_tuned_model_checkpoint,
learning_rate=0.0001,
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=2,
weight_decay=0.01,
fp16=True,
# we set it to evaluate/save per epoch to avoid flowing console
evaluation_strategy=IntervalStrategy.EPOCH,
save_strategy=IntervalStrategy.EPOCH,
save_total_limit=2,
do_train=do_train
)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
)
if trainer.args.do_train:
train_output = trainer.train()
# saving the model which allows us to leverage
# .from_pretrained(model_path)
trainer.save_model(fine_tuned_model_checkpoint)
Evaluation¶
Evaluating our model also requires a bit more work on postprocessing front, hence we'll first use transformer's pipeline object for confirming the model we just trained is indeed learning by seeing if its predicted answer resembles ground truth answer.
example = datasets["validation"][0]
qa_pipeline = pipeline(
"question-answering",
model=fine_tuned_model_checkpoint,
tokenizer=fine_tuned_model_checkpoint
)
output = qa_pipeline({
"question": example["question"],
"context": example["context"]
})
answer_text = example["answers"]["text"][0]
print("output answer matches expected answer: ", output["answer"] == answer_text)
output
For evaluation, we'll preprocess our dataset in a slightly different manner:
- First, we technically don't need to generate labels.
- Second, the "fun" part is to map our model's prediction back to original context's span. As a reminder, some of our features are overflowed inputs for the same given example. We'll be using example id for creating this mapping.
- Last, but not least, we'll set the question part of our input sequence to
None, this is for efficiently detecting if our predicted answer span is within the context portion of input sentence as opposed to the question portion.
def prepare_qa_test(examples):
examples["question"] = [question.strip() for question in examples["question"]]
# Tokenize our examples with truncation and padding, but keep overflows using a stride.
# This results in one example potentially generating several features when a context is
# long, each of those features having a context that overlaps a bit the previous
# feature's context to prevent chopping off answer span.
tokenized_examples = tokenizer(
examples["question"],
examples["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True,
return_offsets_mapping=True,
stride=doc_stride
)
sample_mapping = tokenized_examples["overflow_to_sample_mapping"]
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
sequence_ids = tokenized_examples.sequence_ids(i)
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# for offset mapping that are not part of context, set it to None so it's easy to determine
# if a token positiion is part of the context or not
offset_mapping = []
for k, offset in enumerate(tokenized_examples["offset_mapping"][i]):
if sequence_ids[k] != 1:
offset = None
offset_mapping.append(offset)
tokenized_examples["offset_mapping"][i] = offset_mapping
return tokenized_examples
validation_features = datasets["validation"].map(
prepare_qa_test,
batched=True,
remove_columns=datasets["validation"].column_names,
num_proc=8
)
validation_features
With our features, we can generate prediction which is a pair of start and end logits.
raw_predictions = trainer.predict(validation_features)
raw_predictions.predictions
Having our original example, preprocessed features, generated predictions, we'll perform a final post-processing to generate predicted answer for each example. This process mainly involves:
- Creating a map between examples and features.
- Looping through all the examples, and for each example, loop through all its features to pick the best start and end logit combination from the n_best start and end logits.
- During this picking out best answer span process, we'll automatically eliminate answers that are not inside the context, gives negative length (start position greater than end position), as well as answers that are too long (configurable with a max_answer_length parameter).
- The "proper" way of computing score for each answer is to convert start and end logit into probability using a softmax operation, then taking a product of these two probabilities. Here, we'll skip the softmax and obtain the logit scores by summing start and end logits instead (log(ab)=log(a)+log(b))
def postprocess_qa_predictions(
examples,
features,
raw_predictions,
n_best_size = 20,
max_answer_length = 30,
no_answer = False
):
print(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
all_start_logits, all_end_logits = raw_predictions
# build a dictionary that stores examples to features/chunks mapping
# key : example, value : list of features
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
cls_index = 0
predictions = collections.OrderedDict()
# for each example, loop through all its features/chunks for finding the best one
for example_index, example in enumerate(tqdm(examples)):
feature_indices = features_per_example[example_index]
min_null_score = None
valid_answers = []
context = example["context"]
for feature_index in feature_indices:
# model prediction for this feature
start_logits = all_start_logits[feature_index]
end_logits = all_end_logits[feature_index]
offset_mapping = features[feature_index]["offset_mapping"]
# update minimum null prediction's score
feature_null_score = start_logits[cls_index] + end_logits[cls_index]
if min_null_score is None or min_null_score < feature_null_score:
min_null_score = feature_null_score
# loop through all possibilities for `n_best_size` start and end logits.
start_indexes = np.argsort(start_logits)[-1:-n_best_size - 1:-1].tolist()
end_indexes = np.argsort(end_logits)[-1:-n_best_size - 1:-1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Don't consider out-of-scope answers, either because indices
# are out of bounds or correspond to input_ids that
# are not part of the context section.
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or len(offset_mapping[start_index]) < 2
or offset_mapping[end_index] is None
or len(offset_mapping[end_index]) < 2
):
continue
# Don't consider answers with a length that is either < 0 or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"text": context[start_char:end_char],
"score": start_logits[start_index] + end_logits[end_index]
}
)
if len(valid_answers) > 0:
best_answer = max(valid_answers, key=lambda x: x["score"])
else:
# In the very rare edge case we have not a single non-null prediction,
# we create a fake prediction to avoid failure.
best_answer = {"text": "", "score": 0.0}
example_id = example["id"]
if no_answer:
answer = best_answer["text"] if best_answer["score"] > min_null_score else ""
predictions[example_id] = answer
else:
predictions[example_id] = best_answer["text"]
return predictions
final_predictions = postprocess_qa_predictions(
datasets["validation"],
validation_features,
raw_predictions.predictions
)
print("output answer matches expected answer: ", final_predictions[example["id"]] == answer_text)
Squad primarily uses two metrics for model evaluation.
- Exact Match: Measures percentage of predictions that perfectly matches any one of the ground truth answers.
- Macro F1: Measures average overlap between prediction and ground truth answer.
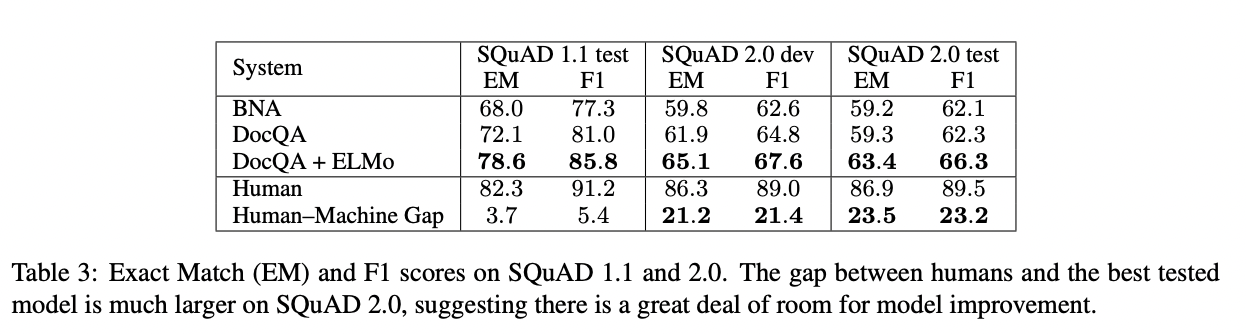
For context, screenshot below shows performance reported by the original Squad 2 paper [5].
squad_metric = evaluate.load(task_name, cache_dir=cache_dir)
formatted_predictions = [
{"id": example_id, "prediction_text": answer}
for example_id, answer in final_predictions.items()
]
references = [{"id": example["id"], "answers": example["answers"]} for example in datasets["validation"]]
squad_metric.compute(predictions=formatted_predictions, references=references)
That's a wrap for this document. We went through nitty gritty details on how to pre-process our inputs and post-process our outputs for fine-tuning a cross attention model on top of pre-trained language model.
Reference¶
- [1] Notebook: Fine-tuning a model on a question-answering task
- [2] Github: Huggingface Question Answering Examples
- [3] Huggingface Course: Chapter 7 Main NLP tasks - Question answering
- [4] Blog: Reader Models for Open Domain Question-Answering
- [5] Paper: Pranav Rajpurkar, Robin Jia, et al. - Know What You Don't Know: Unanswerable Questions for SQuAD - 2018