# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format='retina'
import time
import fasttext
import tokenizers
%watermark -a 'Ethen' -d -t -v -p numpy,tokenizers
MultiLabel Text Classification with FastText¶
Multi label classification is different from regular classification task where there is single ground truth that we are predicting. Here, each record can have multiple labels attached to it. e.g. in the data that we'll be working with later, our goal is to build a classifier that assigns tags to stackexchange questions about cooking. As we can imagine, each question can belong into multiple tags/topics at the same time, i.e. each record have multiple "correct" labels/targets. Let's look at some examples to materialize this.
__label__sauce __label__cheese How much does potato starch affect a cheese sauce recipe?
__label__food-safety __label__acidity Dangerous pathogens capable of growing in acidic environments
__label__cast-iron __label__stove How do I cover up the white spots on my cast iron stove?
Looking at the first few lines, we can see that for each question, its corresponding tags are prepended with the __label__ prefix. Our task is to train a model that predicts the tags/labels given the question.
This file format is expected by Fasttext, the library we'll be using to train our tag classifier.
Quick Introduction to Fasttext¶
We'll be using Fasttext to train our text classifier. Fasttext at its core is composed of two main idea.
First, unlike deep learning methods where there are multiple hidden layers, the architecture is similar to Word2vec. After feeding the words into 1 hidden layer, the words representation are averaged into the sentence representation and directly followed by the output layer.
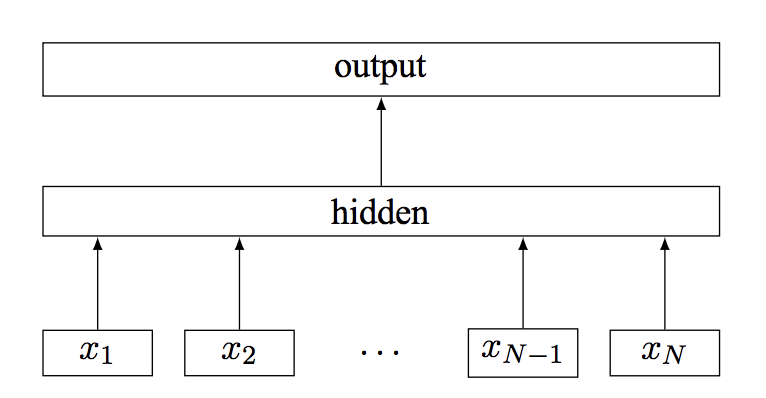
This seemingly simple method works extremely well on classification task, and from the original paper it can achieve performance that are on par with more complex deep learning methods, while being significantly quicker to train.
The second idea is instead of treating words as the basic entity, it uses character n-grams or word n-grams as additional features. For example, in the sentence, "I like apple", the 1-grams are 'I', 'like', 'apple'. The word 2-gram are consecutive word such as: 'I like', 'like apple', whereas the character 2-grams are for the word apple are 'ap', 'pp', 'pl', 'le'. By using word n-grams, the model now has the potential to capture some information from the ordering of the word. Whereas, with character n-grams, the model can now generate better embeddings for rare words or even out of vocabulary words as we can compose the embedding for a word using the sum or average of its character n-grams.
For readers accustomed to Word2vec, one should note that the word embedding/representation for the classification task is neither the skipgram or cbow method. Instead it is tailored for the classification task at hand. To elaborate:
- Given a word, predict me which other words should go around (skipgram).
- Given a sentence with a missing word, find me the missing word (cbow).
- Given a sentence, tell me which label corresponds to this sentence (classification).
Hence, for skipgram and cbow, words in the same context will tend to have their word embedding/representation close to each other. As for classification task, words that are most discriminative for a given label will be close to each other.
Data Preparation¶
We'll download the data and take a peek at it. Then it's the standard train and test split on our text file. As Fasttext accepts the input data as files, the following code chunk provides a function to perform the split without reading all the data into memory.
# download the data and un-tar it under the 'data' folder
# -P or --directory-prefix specifies which directory to download the data to
!wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz -P data
# -C specifies the target directory to extract an archive to
!tar xvzf data/cooking.stackexchange.tar.gz -C data
!head -n 3 data/cooking.stackexchange.txt
import random
def train_test_split_file(input_path: str,
output_path_train: str,
output_path_test: str,
test_size: float,
random_state: int=1234,
encoding: str='utf-8',
verbose: bool=True):
random.seed(random_state)
# we record the number of data in the training and test
count_train = 0
count_test = 0
train_range = 1 - test_size
with open(input_path, encoding=encoding) as f_in, \
open(output_path_train, 'w', encoding=encoding) as f_train, \
open(output_path_test, 'w', encoding=encoding) as f_test:
for line in f_in:
random_num = random.random()
if random_num < train_range:
f_train.write(line)
count_train += 1
else:
f_test.write(line)
count_test += 1
if verbose:
print('train size: ', count_train)
print('test size: ', count_test)
def prepend_file_name(path: str, name: str) -> str:
"""
e.g. data/cooking.stackexchange.txt
prepend 'train' to the base file name
data/train_cooking.stackexchange.txt
"""
directory = os.path.dirname(path)
file_name = os.path.basename(path)
return os.path.join(directory, name + '_' + file_name)
data_dir = 'data'
test_size = 0.2
input_path = os.path.join(data_dir, 'cooking.stackexchange.txt')
input_path_train = prepend_file_name(input_path, 'train')
input_path_test = prepend_file_name(input_path, 'test')
random_state = 1234
encoding = 'utf-8'
train_test_split_file(input_path, input_path_train, input_path_test,
test_size, random_state, encoding)
print('train path: ', input_path_train)
print('test path: ', input_path_test)
Model Training¶
We can refer to the full list of parameters from Fasttext's documentation page. Like with all machine learning models, feel free to experiment with various hyperparameters, and see which one leads to better performance.
# lr = learning rate
# lrUpdateRate similar to batch size
fasttext_params = {
'input': input_path_train,
'lr': 0.1,
'lrUpdateRate': 1000,
'thread': 8,
'epoch': 10,
'wordNgrams': 1,
'dim': 100,
'loss': 'ova'
}
model = fasttext.train_supervised(**fasttext_params)
print('vocab size: ', len(model.words))
print('label size: ', len(model.labels))
print('example vocab: ', model.words[:5])
print('example label: ', model.labels[:5])
Although not used here, fasttext has a parameter called bucket. It can be a bit unintuitive what the parameter controls. We note down the explanation provided by the package maintainer.
The size of the model will increase linearly with the number of buckets. The size of the input matrix is DIM x (VS + BS), where VS is the number of words in the vocabulary and BS is the number of buckets. The number of buckets does not have other influence on the model size. The buckets are used for hashed features (such as character ngrams or word ngrams), which are used in addition to word features. In the input matrix, each word is represented by a vector, and the additional ngram features are represented by a fixed number of vectors (which corresponds to the number of buckets).
The loss function that we've specified is one versus all, ova for short. This type of loss function handles the multiple labels by building independent binary classifiers for each label.
Upon training the model, we can take a look at the prediction generated by the model via passing a question to the .predict method.
text = 'How much does potato starch affect a cheese sauce recipe?'
model.predict(text, k=2)
The annotated tags for this question were __label__sauce and __label__cheese. Meaning we got both the prediction correct when asking for the top 2 tags. i.e. the precision@2 (precision at 2) for this example is 100%.
text = 'Dangerous pathogens capable of growing in acidic environments'
model.predict(text, k=2)
In this example, the annotated tags were __label__food-safety and __label__acidity. In other words, 1 of our predicted tag was wrong, hence the precision@2 is 50%.
Notice the second prediction's score is pretty low, when calling the .predict method, we can also provide a threshold to cutoff predictions lower than that value.
text = 'Dangerous pathogens capable of growing in acidic environments'
model.predict(text, k=2, threshold=0.1)
The .predict method also supports batch prediction, where we pass in a list of text.
texts = [
'How much does potato starch affect a cheese sauce recipe?',
'Dangerous pathogens capable of growing in acidic environments'
]
batch_results = model.predict(texts, k=2)
batch_results
To perform this type of evaluation all together on our train and test file, we can leverage the .test method from the model to evaluate the overall precision and recall metrics.
def print_results(model, input_path, k):
num_records, precision_at_k, recall_at_k = model.test(input_path, k)
f1_at_k = 2 * (precision_at_k * recall_at_k) / (precision_at_k + recall_at_k)
print("records\t{}".format(num_records))
print("Precision@{}\t{:.3f}".format(k, precision_at_k))
print("Recall@{}\t{:.3f}".format(k, recall_at_k))
print("F1@{}\t{:.3f}".format(k, f1_at_k))
print()
for k in range(1, 3):
print('train metrics:')
print_results(model, input_path_train, k)
print('test metrics:')
print_results(model, input_path_test, k)
Tokenizer¶
Apart from tweaking various parameters for the core fasttext model, we can also spend some effort on preprocessing the text to see if it improves performance. We'll be using Byte Pair Encoding to tokenize the raw text into subwords.
Overall work flow would be to:
- Train the tokenizer on the file that contains the training data. To do so, we need to read the training data and create a file that only contains the text data, i.e. we need to strip the label out from the file to train our tokenizer only on the input text file.
- Once the tokenizer is trained, we need to read in the training data again, and tokenize the text in the file with our trained-tokenizer and also make sure the data is in the format that fasttext can consume.
- Proceed as usual to train the model on the preprocessed data.
- When generating prediction for new data, remember to pass it through the tokenizer before.
FASTTEXT_LABEL = '__label__'
def create_text_file(input_path: str, output_path: str, encoding: str='utf-8'):
with open(input_path, encoding=encoding) as f_in, \
open(output_path, 'w', encoding=encoding) as f_out:
for line in f_in:
try:
tokens = []
for token in line.split(' '):
if FASTTEXT_LABEL not in token:
tokens.append(token)
text = ' '.join(tokens)
except ValueError as e:
continue
f_out.write(text)
text_input_path = prepend_file_name(input_path_train, 'text')
print('text only train file: ', text_input_path)
create_text_file(input_path_train, text_input_path)
!head -n 3 data/text_train_cooking.stackexchange.txt
For our tokenizer, we'll be using HuggingFace's Tokenizers. Similar to Fasttext, the input expects the path to our text.
from tokenizers import ByteLevelBPETokenizer
tokenizer = ByteLevelBPETokenizer(lowercase=True)
tokenizer.train(
text_input_path,
vocab_size=10000,
min_frequency=2,
show_progress=True
)
After training the tokenizer, we can use it to tokenize any new incoming text.
text = 'How much does potato starch affect a cheese sauce recipe?'
encoded_text = tokenizer.encode(text)
encoded_text
encoded_text.tokens
We now read in the original training/test file and tokenized the text part with our tokenizer, and write it back to a new file. We'll train the fasttext model on this new tokenized file.
from tokenizers.implementations import BaseTokenizer
def tokenize_text(tokenizer: BaseTokenizer, text: str) -> str:
"""
Given the raw text, tokenize it using the trained tokenizer and
outputs the tokenized tetx.
"""
return ' '.join(tokenizer.encode(text).tokens)
def create_tokenized_file(input_path: str, output_path: str,
tokenizer: BaseTokenizer, encoding: str='utf-8'):
with open(input_path, encoding=encoding) as f_in, \
open(output_path, 'w', encoding=encoding) as f_out:
for line in f_in:
try:
# the labels remains untouched during the preprocessing step as its
# already in a format that fasttext can consume
tokens = []
labels = []
for token in line.split(' '):
if FASTTEXT_LABEL in token:
labels.append(token)
else:
tokens.append(token)
text = ' '.join(tokens)
label = ' '.join(labels)
except ValueError as e:
continue
tokenized_text = tokenize_text(tokenizer, text)
new_line = label + ' ' + tokenized_text
f_out.write(new_line)
f_out.write('\n')
input_path_train_tokenized = prepend_file_name(input_path_train, 'tokenized')
print('tokenized train file: ', input_path_train_tokenized)
create_tokenized_file(input_path_train, input_path_train_tokenized, tokenizer)
input_path_test_tokenized = prepend_file_name(input_path_test, 'tokenized')
print('tokenized test file: ', input_path_test_tokenized)
create_tokenized_file(input_path_test, input_path_test_tokenized, tokenizer)
!head -n 3 data/tokenized_train_cooking.stackexchange.txt
fasttext_params['input'] = input_path_train_tokenized
tokenized_model = fasttext.train_supervised(**fasttext_params)
print('vocab size: ', len(tokenized_model.words))
print('label size: ', len(tokenized_model.labels))
print('example vocab: ', tokenized_model.words[:5])
print('example label: ', tokenized_model.labels[:5])
We print out the evaluation metric for the new model based on tokenized text and compare it with the original model that was trained on the raw text.
for k in range(1, 3):
print('train metrics:')
print_results(tokenized_model, input_path_train_tokenized, k)
print('test metrics:')
print_results(tokenized_model, input_path_test_tokenized, k)
for k in range(1, 3):
print('train metrics:')
print_results(model, input_path_train, k)
print('test metrics:')
print_results(model, input_path_test, k)
Both the tokenizer and fasttext model has API to save and load the model.
directory = 'cooking_model'
if not os.path.isdir(directory):
os.makedirs(directory, exist_ok=True)
tokenizer_checkpoint = os.path.join(directory, 'tokenizer.json')
tokenizer.save(tokenizer_checkpoint)
tokenized_model_checkpoint = os.path.join(directory, 'tokenized_cooking_model.fasttext')
tokenized_model.save_model(tokenized_model_checkpoint)
from tokenizers import Tokenizer
loaded_tokenizer = Tokenizer.from_file(tokenizer_checkpoint)
loaded_model = fasttext.load_model(tokenized_model_checkpoint)
encoded_text = loaded_tokenizer.encode(text)
encoded_text.tokens
Now, to predict new labels for incoming text, we need to tokenize the raw text before feeding it to the model.
def predict(text, tokenizer, model, k, threshold=0.1):
tokenized_text = tokenize_text(tokenizer, text)
return model.predict(tokenized_text, k=k, threshold=threshold)
text = 'Which baking dish is best to bake a banana bread ?'
predict(text, loaded_tokenizer, loaded_model, k=3)
def batch_predict(texts, tokenizer, model, k, threshold=0.1):
tokenized_texts = [tokenize_text(tokenizer, text) for text in texts]
return model.predict(tokenized_texts, k=k, threshold=threshold)
texts = [
'Which baking dish is best to bake a banana bread ?',
'Why not put knives in the dishwasher?',
'How do I cover up the white spots on my cast iron stove?'
]
batch_results = batch_predict(texts, loaded_tokenizer, loaded_model, k=2, threshold=0.0)
batch_results
Fasttext Text Classification Pipeline¶
The following provides a sample code on how to wrap a FasttextPipeline class on top of the fasttext model to allow for hyperparameter tuning. The fasttext_module can be found here for those interested.
model_id = 'cooking'
fasttext_params = {
"lr": 0.1,
"lrUpdateRate": 1000,
"thread": 6,
"epoch": 10,
"wordNgrams": 1,
"dim": 100,
"loss": "ova"
}
fasttext_hyper_params = {
'dim': [80, 100],
'epoch': [15]
}
fasttext_search_parameters = {
"n_iter": 2,
"n_jobs": 1,
"verbose": 1,
"scoring": "f1@1",
"random_state": 1234
}
val_size = 0.1
split_random_state = 1234
from fasttext_module.model import FasttextPipeline
fasttext_pipeline = FasttextPipeline(model_id,
fasttext_params,
fasttext_hyper_params,
fasttext_search_parameters)
# fit the pipeline by giving it the training text file and specify the
# size of the validation split that will be used for hyperparameter tuning
# note that here the file in input_path_train should already be tokenized and
# in the format that fasttext expects
fasttext_pipeline.fit_file(input_path_train, val_size, split_random_state)
# check the hyperparameter tuning result stored in a pandas DataFrame
fasttext_pipeline.df_tune_results_
# save and load the model back
model_checkpoint_dir = fasttext_pipeline.save('cooking')
fasttext_pipeline_loaded = FasttextPipeline.load(model_checkpoint_dir)
# compute the evaluation metric on the train and test text dataset
k = 1
score_str_train = fasttext_pipeline.score_str(input_path_train, k)
score_str_test = fasttext_pipeline.score_str(input_path_test, k)
print('train' + score_str_train)
print('test' + score_str_test)
# use the trained model to predict on new incoming text
k = 2
threshold = 0.1
texts = [
'Which baking dish is best to bake a banana bread ?',
'Why not put knives in the dishwasher?',
'How do I cover up the white spots on my cast iron stove?'
]
batch_results = fasttext_pipeline.predict(texts, k, threshold)
batch_results