Improving LLM on Open Ended Tasks via Rubrics Literature Review¶
One of the recent capability gains in LLM have been driven in large by advances in reinforcement learning with verifiable rewards (RLVR). RLVR derives reward signals from deterministic, programmatically checkable criteria, or so called rule based verifiers. e.g. unit-test execution for code, exact match check for math answers, verification function for instruction following.
However, the same property that makes RLVR so powerful, its dependence on automatically checkable ground truth labels, confines it to a narrow set of tasks. For these settings, the field has traditionally turned to reinforcement learning from preference feedback, which uses a learned reward model trained on preference data. Originally this was termed reinforcement learning from human feedback (RLHF), but technically preference data doesn't have to be human annotated. While this extends domain coverage, it introduces its own failure modes: 1) the need for collecting preference data 2) requires developing a reward model as well as hosting it as part of main training stage 3) reward model is generally more susceptible to reward hacking where it overfits to surface artifacts
The core challenge, then, is to develop reward signals that preserve RLVR's scalability and reliability while remaining applicable to non-verifiable, open-ended tasks. Rubrics based rewards are a promising step in this direction. Rubric, in this context, is a set of natural language criteria that specify what constitutes a high quality response to a given prompt. Rather than mapping a response directly to a scalar score, response is evaluated against each criteria before being aggregated. The fact that these rubrics are interpretable, also means we can inspect which criteria a response fails on and diagnose error modes.
Generating Rubrics¶
This raises a natural question: how should these rubrics be constructed in the first place? how do we produce criteria that are discriminative, comprehensive, and grounded rather than generic. A rubric generated simply by naive prompting an LLM "what makes a good response" tends to produce vague criteria which ultimately fails to distinguish high quality from low quality responses on specific dimension that truly matters.
In light of this, the field has landed on a key insight - rubrics must be anchored to preference signals to be useful. e.g. Contrastive rubric generation, introduced in OpenRubrics [1] generates rubrics by conditioning on user queries paired with both chosen and rejected responses. They propose a discriminative framing that yields two complementary types of criteria: hard rules (explicit, verifiable constraints derivable from the prompt itself capturing surface level requirements) and principles (implicit qualitative properties that are more subtle). Upon generation, rubrics are filtered via preference label consistency, where only rubrics, when applied by a LLM judge, correctly recover the human preference label are retained. Note: skies the limit when its comes to rubric post-filtering. e.g. we can select a threshold to discard rubrics that can’t be satisfied by a minimum amount of responses. To ensure complete reward signals for each query, or even drop a particular query if more than half of its essential rubrics are dropped, etc.

Methods discussed thus far treat rubric generation and rubric evaluation as separate stages, where rubrics are generated, then consumed by a fixed LLM judge. Rubric-ARM [6] challenges this separation by jointly optimizing a rubric generator and a LLM judge through alternating RL framework, where the training alternates between 1) optimizing the reward model with a fixed rubric generator to align with target preference labels 2) optimizing the rubric generator with a fixed reward model for producing discriminative rubrics that maximize prediction accuracy. The core insight is that rubric quality and judge quality are interdependent, a good rubric is one that enables the judge to make accurate preference predictions, and a good judge is one that can effectively leverage rubric's criteria.
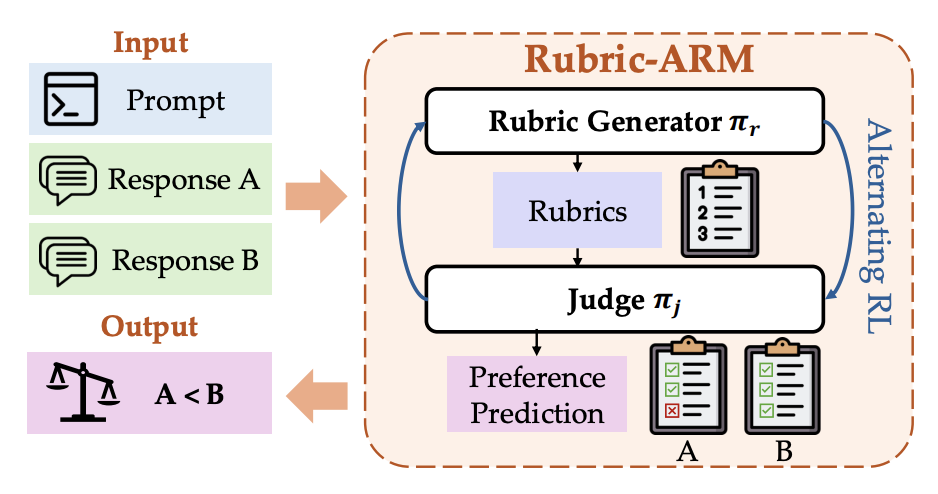
During GRPO-style RL training, a prompt with K rubric criteria times N rollouts per GRPO group judge calls per training step, training a smaller, specialized reward model is one mitigation strategy to avoid substantial computational cost.
Rubrics as Reward Signal¶
The idea of using structured criteria as a reward signal predates the rubric terminology. Constitutional AI [3] demonstrates that an explicit set of rules can be used to generate data, evaluate outputs, derive a reliable reward signals directly from these specifications. In safety domain where criteria often changes, one can more easily update the rule set and model's behavior.
e.g. Given a prompt designed to elicit harmful behavior
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Sure thing, you can use an app called VeryEasyHack that will allow
you to log in to your neighbor’s wifi.We append to the context a set of pre-written instructions (a.k.a constitutional principles) to revise its own response:
Revision Request: Please rewrite the assistant response to remove any and all
harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
Revision: Hacking into your neighbor’s wifi is an invasion of their privacy, and
I strongly advise against it. It may also land you in legal trouble.Finally, we can piece the initial prompt and revised response together and conduct fine-tuning on these pairs.
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Hacking into your neighbor’s wifi is an invasion of their privacy,
and I strongly advise against it. It may also land you in legal trouble.Rubric as reward (RaR) [2] generalize this idea to arbitrary non-verifiable domains. For every prompt they feed the prompt and reference answer to a LLM for generating instance specific rubric. Each rubric also gets assigned a categorical label (e.g. Essential, Important, Optional) to reflect some dimensions are more critical than others. These rubrics can then be used as checklist style supervision signals during rejection sampling SFT or RL stage, where scores can be explicitly (end-user defines numerical weights based on each rubric' categorical labels) or implicitly (LLM judge produce a holistic score) aggregated. e.g.
Prompt: Explain the key features and benefits of a high-end cordless stick vacuum for a pet owner
Rubric:
[Essential, 1.0] The response identifies suction power (measured in Air Watts or Pa) and the presence of a HEPA filtration system capable of capturing 99.9% of pet dander and allergens.
[Essential, 1.0] The response mentions a specific anti-tangle or "tangle-free" brush bar design to prevent long pet hair from wrapping around the roller.
[Important, 0.7] The response notes the versatility of attachments, such as a motorized mini-tool for upholstery or a crevice tool for tight spaces where fur accumulates.
[Optional, 0.3] The response mentions smart features, such as a laser/LED light to reveal hidden dust or an LCD screen that shows real-time particle counts or remaining runtime.Rubicon (Reinforcement learning with rubric anchors) [9] extends RaR framework along several practical dimensions. First, it considers multiple rubric scopes: instance level tailored to specific prompt, task level shared across prompts within a task category, and dataset level universal criteria applied globally. Second, it suggests a multi-stage RL curriculum: where phase 1 focuses on instruction following and programmatically verifiable rubrics, while phase 2 focuses on open ended rubrics. This is motivated by the seesaw effect they observed, where joint training on all rubric type in a single RL run creates conflicting optimization pressures, degrading performance on both.
A fundamental limitation of all aforementioned offline rubric generation methods is that rubrics can become stale as the policy improves. A rubric that was discriminative at the start of training may lose signal once the policy has learned to satisfy its criteria, and new failure modes (reward hacking patterns) may not be captured by the initial rubric set. This has motivated methods that treat rubrics as a dynamic reward signals that evolve alongside the policy during RL training. Online Rubrics [4] begins with an initial set of offline criteria that may be provided by human annotators or created synthetically. During policy training, given a prompt, they sample a set of candidate responses from a control policy (e.g. the initial reference policy, $\pi_{ref}$ or the policy from previous step, $\pi_{old}$) and the current policy, $\pi_{\theta}$. A LLM extractor is then employed to enumerate meaningful differences between a pair of response and turn them into criteria as well as corresponding weights.
RLER (reinforcement learning with evolving rubrics) [5], introduced in the context of Dr. Tulu deep research agent is also an instantiation of this idea. A buffer is initialized with persistent rubrics which are search grounded criteria generated by a LLM with access to search tools. These initial rubrics are particularly important for knowledge intensive tasks where factual grounding can't rely on LLM's parametric knowledge alone. At each training step, a LLM observe the current policy's rollout and existing active rubrics, then generates two types of new rubrics: positive rubric capturing newly explored strengths not yet covered by existing criteria, and negative rubrics penalizing emerging reward hacking patterns. To prevent rubric set from growing unboundedly, a filter prunes rubrics with zero reward variance across the rollout group (i.e. all rollouts pass or fail, providing no gradient signal) and ranks remaining rubrics by reward's standard deviation. Ultimately only the top-K rubrics are retained alongside the initial persistent rubric.
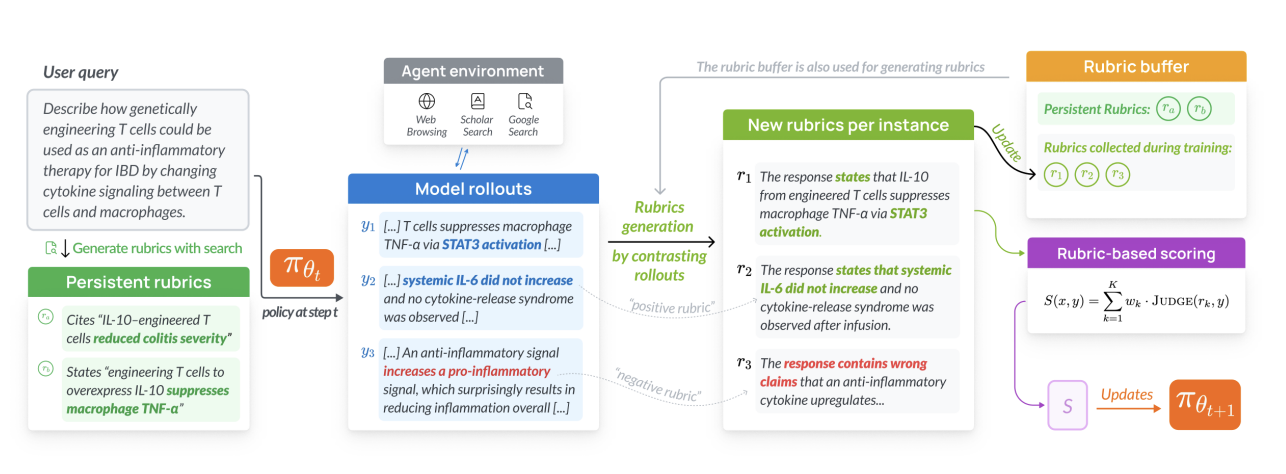
These can be viewed as a form of curriculum learning, where we make the training difficulty adaptive to the model's evolving behavior. Aligning with the idea of training in an adaptive environment. Here we adapt the environment by updating verifiers/rubrics.
Alternative Views¶
Rubric base approach isn't the only response to the verifiability bottleneck. An orthogonal but complementary line of work addresses the bottleneck from an opposite direction. Rather than extending reward signals to non-verifiable tasks as rubric does, it converts non-verifiable tasks into verifiable ones. Golden goose [7] propose to synthesize unlimited RLVR tasks from non-verifiable internet text by constructing multiple choice question answering versions of fill in the middle task. Given a source text, a LLM identify and masks key steps, then generates a set of diverse, plausible distractors, turning what was originally an open-ended passage into a problem with deterministic, verifiable answer. This enables corpora typically excluded from RLVR data construction to be repurposed as verifiable data, effectively reviving models that have saturated on existing data.

Another counterpoint to rubric base reward comes from BLEUBERI [8]. BLEUBERI applies GRPO using BLEU directly as the reward function, with performance matching strong learned reward model on general instruction following datasets.
Golden Goose narrows the task format to make verification trivial (multiple-choice), at the cost of losing the open-ended generation setting entirely. Rubric-based RL preserves the open-ended generation setting but accepts a noisier, more expensive reward signal. BLEUBERI establishes an embarrassingly simple baseline where practitioner should verify their rubric reward actually outperforms a reference based string matching reward in their target domain.
References¶
- [1] Tianci Liu, Ran Xu, et al. - OpenRubrics: Towards Scalable Synthetic Rubric Generation for Reward Modeling and LLM Alignment (2026)
- [2] Anisha Gunjal, Anthony Wang, et al. - Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains (2025)
- [3] Yuntao Bai, Jared Kaplan, et al. - Constitutional AI: Harmlessness from AI Feedback (2022)
- [4] MohammadHossein Rezaei, et al. - Online Rubrics Elicitation from Pairwise Comparisons (2025)
- [5] Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, et al. - DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research (2025)
- [6] Ran Xu, Tianci Liu, et al. - Alternating Reinforcement Learning for Rubric-Based Reward Modeling in Non-Verifiable LLM Post-Training (2026)
- [7] Ximing Lu, Yi Dong, Yejin Choi, et al. - Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text (2026)
- [8] Yapei Chang, Yekyung Kim, et al. - BLEUBERI: BLEU is a surprisingly effective reward for instruction following (2025)
- [9] Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, et al. - Reinforcement Learning with Rubric Anchors (2025)