%load_ext watermark
%load_ext autoreload
%autoreload 2
import ray
import math
import json
import torch
import string
import numpy as np
import pandas as pd
from textwrap import dedent
from typing import List, Dict
from datasets import load_dataset
from vllm import LLM, SamplingParams
from sklearn.metrics import ndcg_score
from scipy.stats import kendalltau, rankdata
from transformers import AutoTokenizer, AutoModelForCausalLM
%watermark -a 'Ethen' -d -v -u -p transformers,datasets,torch,numpy,pandas,vllm
LLM Listwise Reranker¶
Early implementation of LLM for listwise reranking employs the following prompt template [1] [4]
Input:
Rank these passages based on their relevance to the {query} in descending order
1. {passage 1}
2. {passage 2}
...
Output:
[2, 1, ...]Where given an input query and multiple candidate messages, LLM is prompted or instruction fine tuned to generate a ranked ordering based on some relevance criteria. The expected output is a sequence of indices representing descending order of relevance. While this approach offers intuitive simplicity, it leaves a lot to be desired both from a training as well as inference perspective.
Training¶
From training perspective, supervised/instruction fine-tuning's next token prediction loss applies uniform penalties across all ranking errors. This fails to differentiate between critical errors, such as misranking highly relevant passages, versus minor inconsistencies, like reordering non-relevant items.
To address this limitation, we propose adopting established learning-to-rank methodologies by implementing NDCG/MRR-based reward functions during RL phase [6]. This enhancement serves dual purposes: it better aligns the objective function with task requirements while enabling more dense reward signals.
Dense reward in this context refers to moving beyond optimizing for a sparse binary feedback such as single relevance definition or behavioral signals including purchase or click for our ground truth array [1 (purchase/click/relevance), 0 (other), 0 (other)]. Instead, we categorize ground truth into distinct hierarchical interaction levels, e.g. [4 (purchase), 2 (click), 1 (relevance), 0 (others)] [7]. This refined approach addresses critical challenges in standard RL with binary reward: model collapse due to sparse positive signals or skews optimization towards simpler cases. Exemplars of applying dense reward includes defining a curriculum learning regime where we warm up with fine-grained reward signals before transitioning to strict pass/fail [8] or a hybrid reward system that combine both model and rule-base reward which captures more grandular signals to better differentiate diverse rollouts [9].
Inference¶
On inference side, ranked list output lacks efficiency due its sequential nature. On the other hand, single token decoding utilizes the first generated identifier from LLM head's output logits to directly determine ranking order [2] [3]. This method significantly accelerate inference speed for closed vocab style list-wise re-ranking applications.
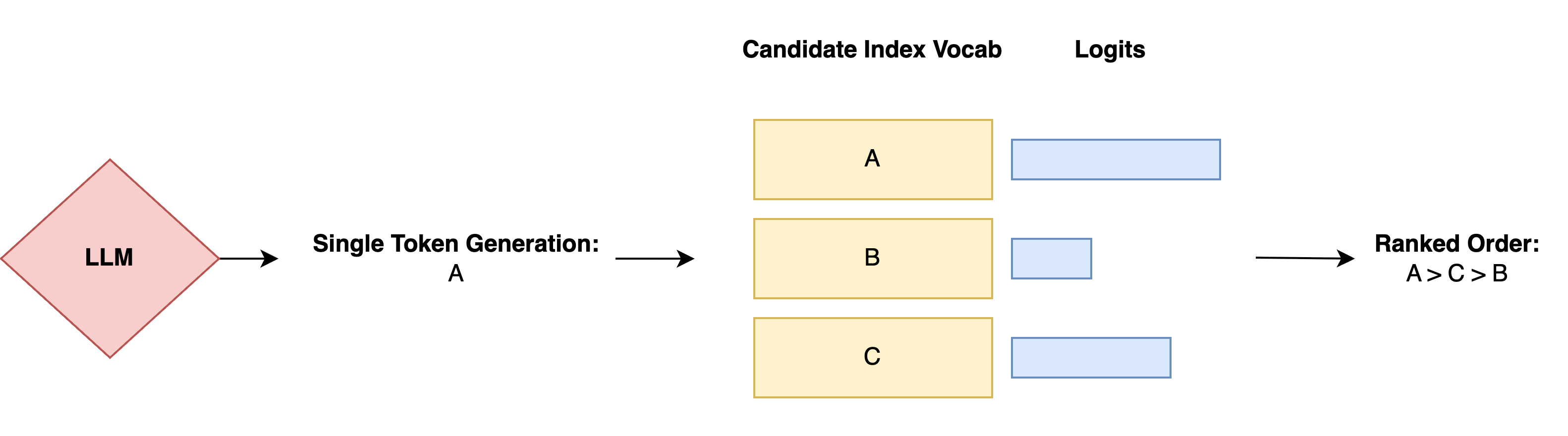
Two important clarifications. This fundamentally differs from standard multiple-choice evaluation methods, specifically the generation and cloze-style formulations [10], and this is not suitable for open vocab style generation.
Distinction from standard multi choice formulation: In a generation formulation, the model is presented with a prompt, answer choices. Evaluation uses exact match between the answer label and generated choice.
Question: {question}
A. [Option A]
B. [Option B]
Answer:While this matches how multiple choice questions are typically presented to humans, weaker base LLM models can struggle with this formulation. The alternative cloze formulation, i.e. the multi_choice setup in eval framework such as lm eval harness:
Question: {question}
Answer: {Insert individual options}evaluates each option's logit score independently by substituting individual answer choices after Answer: and picking the most probable choice.
In single token decoding, we still maintain a generation based formulation, while directly extracting additional each answer option's score/logits from LLM head's vocab. Contrasting with cloze formulation's separate substitution approach which scales poorly for re-ranking task given inference complexity scales linearly with number of input candidates.
Open-vocab vs closed-vocab: For open-vocab use cases such as query or semantic id generation [7], LLM's role extends beyond pure re-ranking. Input candidates only serves as contextual signals or anchors rather than strict constraints, allowing generation result to fall outside initial candidate set. Rendering this single token decoding using candidate identifier less suitable for open-vocabulary tasks.
Additional Notes¶
One of the most closely related work is Rank-R1 [13], where they employ GRPO style reinforcement learning to train a document re-ranker. The model is trained on MS-MARCO dataset provided by the Tevatron IR toolkit, comprises training queries, human-labeled relevant documents, and the top 100 documents retrieved by BM25. For each training query, they sample 19 documents from BM25-retrieved set alongside one labeled relevant document. As for benchmark, they evaluated on both in-domain benchmarks (TREC DL19 and DL20) and out-of-domain datasets (BRIGHT).
Problem formulation wise, they also chose to output the most relevant document among the candidates given a query. This allows direct comparison between SFT and RL approaches. Ranked list output are harder to directly compare given ground truth rankings are typically unavailable in training data (MS-MARCO contains only one judged relevant document per query on average).
For in domain benchmark, their results shows RL exhibits significantly greater data efficiency than SFT during early training stages, achieving equivalent performance with substantially less data. However, this efficiency advantage diminishes as training progresses. Beyond 5-7% of the training data (400k), both approaches converge to similar performance trajectories. On out of domain dataset, their experiment shows RL outperforms or matches SFT models in most benchmark scenarios. For 14B model, SFT's effectiveness plateaus and occasionally underperforms its zero-shot counterparts. In contrast, RL model achieves the largest performance gains.
- Following IFT stage's common best practice of including diverse mix of data/format, sequence generation training objective can also improve the quality of LLM's logit-induced ranking. Whereas during RL stage, reward should handle various edge cases including wrong format, repetition, missing ordering.
- Candidate set: For closed-vocab re-ranking, input candidates typically relies on first stage retrieval or early stage ranking system. This initial stage output not only determines the ceiling/room-for-improvement of a re-ranker, but also determine the optimal candidate pool size we should consider for subsequent re-ranking phase.
- Shuffle candidate ordering:
- Implementing this data augmentation exposes the model to more challenging reordering scenarios [14], achieving a balance between effectiveness and robustness. This approach reduces re-ranker's sensitivity to first stage system's candidate ordering, and mitigates position bias from behavioral logs. During RL stage, shuffling helps prevent reward collapse by discouraging default ordering output, measurable through rank ordering metrics such as Kendall-tau.
- Permutation self consistency [5] is comprised of two main stages, analogous to self-consistency. Multiple responses are generated from shuffled input orderings, with the expectation that output errors will vary across permutations. These diverse ordering biases are then consolidated using established rank aggregation techniques such as Kemeny-Young or Borda count.
- With single token decoding approach, we need to ensure candidate identifier can be represented by one single token. Adopting alphabetic identifiers A-Z imposes a 26 candidate limitation. Larger candidate pools require extended identifier sets such as greek letters or special tokens, etc.
- When implementing RL reward, we can consider normalization, where we calculate the reward as relative improvement [14]
VLLM Evaluation¶
The following implementation section is organized as follows:
- We will re-use first stage retrieval results data from the community.
- Implement single token decoding inference as well as metric calculation using vllm with ray data.
- Use Qwen2.5 7B in a zero shot manner to demonstrate the improvements of performing a stage 2 re-ranking.
Data Preprocessing¶
# https://huggingface.co/datasets/abdoelsayed/reranking-datasets
dataset = load_dataset("abdoelsayed/reranking-datasets", data_files={"test": "bm25/nq-test.json"}, cache_dir="/data", streaming=True)
sample = next(iter(dataset["test"]))
print(sample["question"])
print(sample["answers"])
print(sample["ctxs"][:1])
def format_reranker_dataset(dataset, choices):
processed_samples = []
for sample in dataset:
question = sample["question"]
answers = sample["answers"]
target_labels = []
candidates = []
contexts = sample["ctxs"][:len(choices)]
for i, context in enumerate(contexts):
has_answer = int(context["has_answer"])
text = context["text"]
target_labels.append(has_answer)
candidate = f'{choices[i]}. {text}'
candidates.append(candidate)
if sum(target_labels) == 1:
candidates = "\n ".join(candidates)
prompt_template = dedent("""
Pick the most relevant candidate to the query: **{query}**
**candidates:**
{candidates}
**Output Requirement**
Return **only** the corresponding letter index
Your answer:"""
)
prompt = prompt_template.format(
query=question,
candidates=candidates,
)
max_index = np.argmax(target_labels)
answer = choices[max_index]
messages = [
{
"role": "user",
"content": prompt
},
{
"role": "assistant",
"content": answer
},
]
target_labels_str = json.dumps({"target_labels": target_labels})
processed_sample = {
"question": question,
"answers": answers,
"messages": messages,
"target_labels_str": target_labels_str
}
processed_samples.append(processed_sample)
df_processed_samples = pd.DataFrame(processed_samples)
return df_processed_samples
choices = list(string.ascii_uppercase)
df_processed_samples = format_reranker_dataset(dataset["test"], choices)
print(df_processed_samples.shape)
df_processed_samples.head()
processed_path = "/data/processed_nq.json"
df_processed_samples.to_json(processed_path, orient="records", lines=True)
Evaluation¶
ray.init(
num_cpus=8,
num_gpus=4,
# avoid polluting notebook with log info
log_to_driver=False,
)
ds = ray.data.read_json(processed_path)
@ray.remote
class MetricsAggregator:
"""
Accumulates and computes NDCG scores, position baseline scores, and Kendall Tau
correlations between predicted rank vs position baseline across multiple samples.
"""
def __init__(self, k: int):
self.k = k
self.total_score = 0.0
self.total_baseline_score = 0.0
self.total_kendall_tau_score = 0.0
self.n_samples = 0
def update(self, scores: List[float], labels: List[float]):
"""Update metrics counter with new scores and labels."""
metric_score = ndcg_score([labels], [scores], k=self.k)
baseline_scores = [1 / (i + 1) for i in range(len(labels))]
baseline_score = ndcg_score([labels], [baseline_scores], k=self.k)
kendall_tau_score = compute_kendall_tau(scores)
self.total_kendall_tau_score += kendall_tau_score
self.total_baseline_score += baseline_score
self.total_score += metric_score
self.n_samples += 1
return {
f"ndcg_{self.k}": metric_score,
f"baseline_ndcg_{self.k}": baseline_score,
"kendall_tau": kendall_tau_score
}
def compute(self) -> Dict[str, float]:
"""Compute final averaged metrics across all samples."""
if self.n_samples == 0:
metric_score = 0.0
baseline_score = 0.0
kendall_tau_score = 0.0
else:
metric_score = self.total_score / self.n_samples
baseline_score = self.total_baseline_score / self.n_samples
kendall_tau_score = self.total_kendall_tau_score / self.n_samples
return {
f"ndcg_{self.k}": metric_score,
f"baseline_ndcg_{self.k}": baseline_score,
"kendall_tau": kendall_tau_score,
"n_samples": self.n_samples,
}
def compute_kendall_tau(scores):
"""kendall tau used as a guard rail measurement to ensure we don't output
consecutive rank. i.e. just blindly following the order of the original input candidate set"""
# higher score = better rank, rankdata's rank starts at 1
pred_ranks = rankdata(-np.array(scores))
consecutive_ranks = np.arange(1, len(scores) + 1)
tau, p_value = kendalltau(pred_ranks, consecutive_ranks)
# kendall tau value can be nan if input is constant
tau = 0.0 if math.isnan(float(tau)) else tau
return tau
class LLMRerankerSingleTokenEvaluator:
def __init__(
self,
pretrained_model_name_or_path: str,
sampling_params: SamplingParams,
vllm_engine_kwargs,
choices,
metric,
apply_chat_template_kwargs = None,
id_field: str = "id",
tensor_parallel_size: int = 1,
):
self.llm = LLM(
pretrained_model_name_or_path,
tensor_parallel_size=tensor_parallel_size,
**vllm_engine_kwargs,
)
self.sampling_params = sampling_params
self.choices = choices
self.metric = metric
self.id_field = id_field
self.apply_chat_template_kwargs = apply_chat_template_kwargs if apply_chat_template_kwargs else {}
tokenizer = self.llm.get_tokenizer()
self.choice_token_ids = [tokenizer.encode(choice)[0] for choice in choices]
self.think_end_token_id = tokenizer.encode("</think>")[-1]
# for white space, qwen3 series treats \n\n as a single token
whitespace_tokens = list(string.whitespace) + ["\n\n"]
self.whitespace_token_ids = [tokenizer.encode(whitespace_token)[0] for whitespace_token in whitespace_tokens]
def __call__(self, batch):
"""
Logic for inference on 1 batch of data. Example:
messages: array([array([{"role": "user", "content": "prompt"}, {"role": "assistant", "content": "response"}])])
target_labels_str: array(['{"target_labels": [1, 0, 0]}', '{"target_labels": [0, 1, 0]}']
id (optional identifier for each sample):
Returns
-------
Dictionary containing:
- generated_texts: Model generation output
- finished_reasons: Generation completion states. Useful for debugging whether generation successfully completed
- answers: Single token decoding answer. Useful for debugging whether it's outputing/parsing intended candidate choices
- prediction_scores: scores for each candidate choices
- metric_scores: Sample level evaluation metrics in dictionary format
- id: Optional sample identifiers
"""
batch_labels = [json.loads(target_labels_str)["target_labels"] for target_labels_str in batch["target_labels_str"]]
request_outputs = self.generate(batch["messages"])
finished_reasons = []
generated_texts = []
answers = []
prediction_scores = []
metric_scores = []
for request_output, batch_label in zip(request_outputs, batch_labels):
# we assume only sampling 1 output
output = request_output.outputs[0]
# extract answer position's corresponding top log-prob,
# logprob is a dictionary of token id -> Logprob object
position = self.cleanup_reasoning(output)
token_id = output.token_ids[position]
answer = self.llm.get_tokenizer().decode(token_id)
logprobs = output.logprobs[position]
choice_logprobs = []
for choice_token_id in self.choice_token_ids:
logprob = 0.0
if choice_token_id in logprobs:
logprob = math.exp(logprobs[choice_token_id].logprob)
choice_logprobs.append(logprob)
# ensure scores and labels' length lines up, cover edge cases where
# records might not have all the intended candidates
choice_logprobs = choice_logprobs[:len(batch_label)]
metric_score = ray.get(self.metric.update.remote(choice_logprobs, batch_label))
generated_texts.append(output.text)
finished_reasons.append(output.finish_reason)
answers.append(answer)
prediction_scores.append(choice_logprobs)
metric_scores.append(metric_score)
result = {
"generated_texts": generated_texts,
"finished_reasons": finished_reasons,
"answers": answers,
"prediction_scores": prediction_scores,
"metric_scores": metric_scores,
}
# If the input has an id field, add it to the result
if self.id_field in batch:
id_fields = batch[self.id_field].tolist() if isinstance(batch[self.id_field], np.ndarray) else batch[self.id_field]
result[self.id_field] = id_fields
return result
def generate(self, messages):
formatted_texts = []
for message in messages:
if len(message) < 2:
raise ValueError("Expect message length to be at least 2 where last message content is from assistant")
# this assumes the last message content is from assistant, hence we remove it from the input prompt
message = message[:-1].tolist()
formatted_text = self.llm.get_tokenizer().apply_chat_template(
message,
tokenize=False,
add_generation_prompt=True,
**self.apply_chat_template_kwargs
)
formatted_texts.append(formatted_text)
request_outputs = self.llm.generate(formatted_texts, self.sampling_params)
return request_outputs
def cleanup_reasoning(self, output):
"""Return position id of the first none-reasoning token"""
token_ids = output.token_ids
try:
think_end_index = token_ids.index(self.think_end_token_id)
except ValueError:
think_end_index = -1
# loop through each white space token and find the one with the max index position
token_ids = token_ids[think_end_index:]
last_whitespace_index = think_end_index
for whitespace_token_id in self.whitespace_token_ids:
try:
pos = token_ids.index(whitespace_token_id)
last_whitespace_index = max(last_whitespace_index, think_end_index + pos)
except ValueError:
continue
position = last_whitespace_index + 1
return position
pretrained_model_name_or_path = "Qwen/Qwen2.5-7B-Instruct"
tensor_parallel_size = 1
concurrency = 4
batch_size = 4
sampling_params = SamplingParams(n=1, max_tokens=4096, temperature=0.0, logprobs=50)
vllm_engine_kwargs = {
"max_model_len": 32768,
"max_logprobs": 50,
"enable_chunked_prefill": True,
"gpu_memory_utilization": 0.85
}
resources_kwarg = {"num_gpus": 1}
apply_chat_template_kwargs = {"enable_thinking": True}
k = 10
id_field = "id"
metric = MetricsAggregator.remote(k=k)
ds_prediction = ds.map_batches(
LLMRerankerSingleTokenEvaluator,
concurrency=concurrency,
batch_size=batch_size,
fn_constructor_kwargs={
"pretrained_model_name_or_path": pretrained_model_name_or_path,
"tensor_parallel_size": tensor_parallel_size,
"sampling_params": sampling_params,
"vllm_engine_kwargs": vllm_engine_kwargs,
"choices": choices,
"metric": metric,
"id_field": id_field,
"apply_chat_template_kwargs": apply_chat_template_kwargs
},
**resources_kwarg,
)
prediction_path = "/data/vllm_evaluate.parquet"
ds_prediction.write_parquet(prediction_path)
pd.read_parquet(prediction_path)
final_metrics = ray.get(metric.compute.remote())
final_metrics
References¶
- [1] Weiwei Sun - Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents (2023)
- [2] Zhenrui Yue, Sara Rabhi, Gabriel de Souza Pereira Moreira, Dong Wang, Even Oldridge - LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking (2023)
- [3] Revanth Gangi Reddy, JaeHyeok Doo, Yifei Xu, et al. - FIRST: Faster Improved Listwise Reranking with Single Token Decoding (2024)
- [4] Ronak Pradeep, Sahel Sharifymoghaddam et al. - RankVicuna: Zero-Shot Listwise Document Reranking with Open-Source Large Language Models (2023)
- [5] Raphael Tang, Xinyu Zhang et al. - Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models (2023)
- [6] Jiacheng Lin, Tian Wang, Kun Qian - Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning (2025)
- [7] Xian Guo, Ben Chen et al. - OneSug: The Unified End-to-End Generative Framework for E-commerce Query Suggestion
- [8] Yiyou Sun, Yuhan Cao et al. - RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs? (2025)
- [9] Leitian Tao, Ping Yu et al. - Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense (2025)
- [10] Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, Hannaneh Hajishirzi - OLMES: A Standard for Language Model Evaluations (2024)
- [11] What's going on with the Open LLM Leaderboard?
- [12] Yanzhao Zhang, Mingxin Li, et al. - Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models (2025)
- [13] Shengyao Zhuang, Xueguang Ma, et al. - Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning (2025)
- [14] Le Zhang, Bo Wang, et al. - REARANK: Reasoning Re-ranking Agent via Reinforcement Learning (2025)