import os
%load_ext watermark
%load_ext autoreload
%autoreload 2
import torch
import requests
from PIL import Image
from transformers import AutoProcessor, LlavaForConditionalGeneration
%watermark -a 'Ethen' -d -u -v -iv
Mixed Modality LLM Inputs - LLaVA¶
This document introduces a potent method for processing multimodal inputs. LLaVA (Large Language and Vision Assistant) [1] [2] demonstrated connecting pre-trained vision encoder with large language model through a MLP projection layer can achieve impressive multimodal understanding capabilities. Details are illustrated in the diagram below:
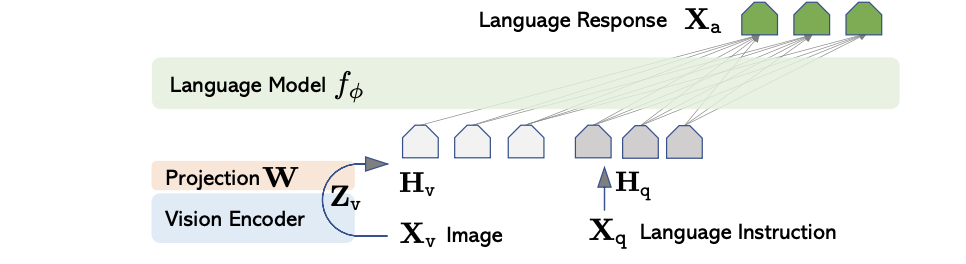
Given an input image $X_v$, they employ a pre-trained CLIP visual encoder ViT-L/14 to extract visual features $Z_v$ from the last two layers. To bridge visual and linguistic modalities, a MLP projection layer is used to maps image features into language model's word embedding space $H_v$.
As for training:
- The model is first pre-trained on image text pairs to align the features of LLM and vision encoder, keeping both frozen, while only training the projection layer. This stage can be understood as training a visual tokenizer for the frozen LLM.
- Next, they keep the vision encoder frozen, while training both projection layer and LLM.
Implementation¶
Our implementation will demonstrate using a pre-trained Llava model for generating image caption, and show how to implement the modality merging part.
model_name = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(model_name, dtype=torch.bfloat16, cache_dir="/data")
processor = AutoProcessor.from_pretrained(model_name, cache_dir="/data")
print("number of parameters: ", model.num_parameters())
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
print(raw_image.size)
raw_image

conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": image_file},
{"type": "text", "text": "What is shown in this image?"},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
print(processor.decode(inputs["input_ids"][0]))
generated_ids = model.generate(**inputs, max_new_tokens=128)
output_ids = [
generated_id[len(input_id):]
for input_id, generated_id in zip(inputs["input_ids"], generated_ids)
]
output_text = processor.batch_decode(
output_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
print(output_text)
Forward Pass¶
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
pixel_values = inputs["pixel_values"]
print(input_ids.shape)
print(pixel_values.shape)
We extract language model's word embedding.
inputs_embeds = model.language_model.get_input_embeddings()(input_ids)
inputs_embeds.shape
Vision transformer such as CLIP prepend a special CLS token to the patch embedding sequence. The original intended purpose was to aggregate global image information, designed for image classification task. For vision language model, we usually require fine-grain spatial features from individual patches, hence we remove the CLS token via [1:].
image_outputs = model.vision_tower(pixel_values, output_hidden_states=True)
# we have the freedom to select how to extract visual features, for simplicity, we choose last hidden layer
selected_image_feature = image_outputs.hidden_states[-1][:, 1:]
selected_image_feature.shape
MLP projection layer for converting image to language space, other projection strategies can be explored, though the hidden dimension should match the one from language model.
print(model.multi_modal_projector)
image_features = model.multi_modal_projector(selected_image_feature)
image_features.shape
Our input ids contains special tokens for marking our image features. Our goal is to replace their values with actual image features.
# replace placeholder embeddings with image features
special_image_mask = (input_ids == model.config.image_token_id)
special_image_mask = special_image_mask.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
print(special_image_mask.shape)
# masked_scatter copies elements from source into self tensor at positions where the mask is True
inputs_embeds = inputs_embeds.masked_scatter(special_image_mask, image_features)
inputs_embeds.shape
Given our mixed modality embeddings, we now feed input embeddings instead of input ids to our language model, which concludes the implementation.
output = model.language_model(inputs_embeds=inputs_embeds)
output.last_hidden_state.shape
Model Architecture:
From an architectural perspective, LLaVA's modular design philosophy is particularly compelling. Its decoupled structure allows each component: the visual encoder, language model, and projection layer, to be independently upgraded without requiring a complete re-train from scratch. This modularity not only facilitates rapid iteration but also enables researchers to leverage advances in individual components as they emerge.
Regarding fusion strategies, the prevailing consensus suggests that early fusion architectures generally demonstrate superior performance compared to their late fusion counterparts. In the context of vision-language models, LLaVA's fusion approach integrate visual and textual information at earlier levels of the model, allowing for richer cross-modal interactions. This stands in contrast to late fusion approaches such as ALBEF (Align Before Fuse) [3], which process modalities separately before combining their representations at later stages through cross attention, potentially limiting the depth of multimodal reasoning.
Mixed Modality Inputs:
This document presents an architecture for integrating heterogeneous modalities within large language models (LLMs). While the concept is commonly associated with multimodal inputs such as images, video, or audio, this fusion paradigm extends naturally to other domains, including user behavior modeling and item representation in recommendation systems.
User-LLM [4] Conventional approaches to incorporating user information into LLMs typically convert user interactions into extensive textual descriptions before processing. While conceptually straightforward, this methodology introduces substantial computational overhead due to the resulting long context lengths that must be processed during inference. Rather than textual representations, User LLM adopts an analogous strategy and leverages compact user embeddings to contextualize LLM with historical interaction patterns. This embedding-based representation maintains semantic richness while dramatically reducing the token budget required for user context.
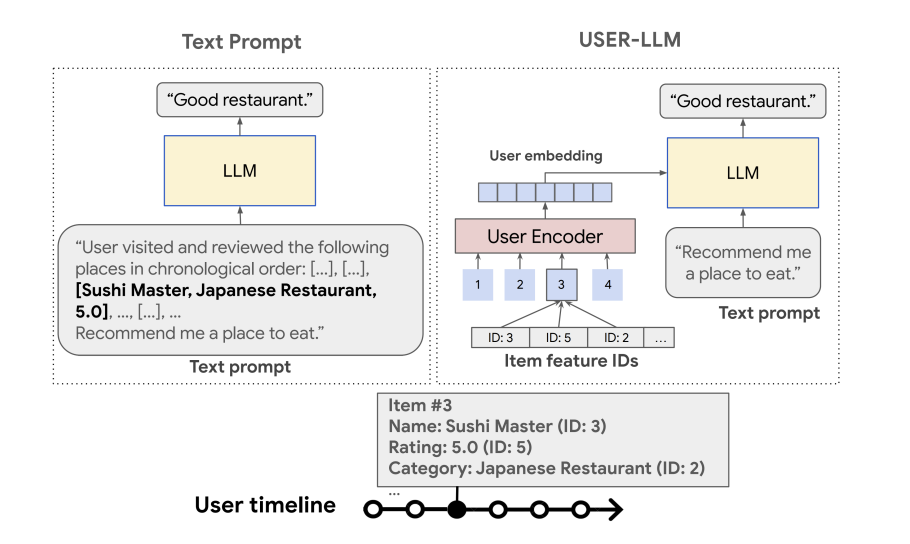
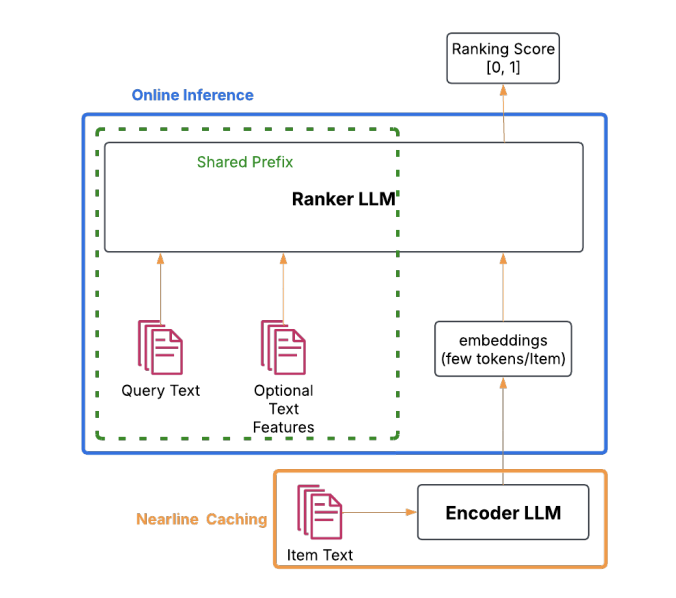
Mix-LLM [5] addresses the computational challenges of ranking systems by replacing candidate item descriptions with compact embedding tokens, thereby significantly reducing prompt length for ranker LLMs. Since item embeddings can be pre-computed and cached, the number of tokens requiring processing during online inference is substantially reduced, enabling more efficient real-time ranking. The training methodology employs a knowledge distillation framework: a textual teacher model is first trained on full item descriptions to capture rich semantic relationships, then distilled into a mixed-input student model. This distilled model is deployed for online inference, enabling the capture of complex query-item-feature interactions that surpasses the representational capacity of bi-encoder architectures, while maintaining the computational efficiency necessary for production deployment.
References¶
- [1] Haotian Liu, Chunyuan Li, et al. - Visual Instruction Tuning (2023)
- [2] Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee - Improved Baselines with Visual Instruction Tuning (2024)
- [3] Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, Steven Hoi - Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (2021)
- [4] Lin Ning, Luyang Liu, et al. - USER-LLM: Efficient LLM Contextualization with User Embeddings (2024)
- [5] Ran He, Shusen Jing, Kayhan Behdin, Yubo Wang, Sundara Raman Ramachandran, Chanh Nguyen, Jian Sheng, Xiaojing Ma, Chuanrui Zhu, et al. - MixLM: High-Throughput and Effective LLM Ranking via Text-Embedding Mix-Interaction (2025)