# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
import os
import torch
import scipy
import datasets
import transformers
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.nn.functional as F
from time import perf_counter
from torch.utils.data import DataLoader
from datasets import (
load_dataset,
concatenate_datasets,
disable_progress_bar,
DatasetDict
)
from datasets.utils.logging import set_verbosity_error
from transformers import (
Trainer,
TrainingArguments,
AutoModel,
AutoTokenizer,
DataCollatorWithPadding,
EarlyStoppingCallback,
IntervalStrategy
)
from scipy.stats import pearsonr, spearmanr
from sklearn.metrics.pairwise import paired_cosine_distances
device = "cuda" if torch.cuda.is_available() else "cpu"
cache_dir = None
%watermark -a 'Ethen' -d -u -iv
Sentence Transformer: Training Bi-Encoder via Contrastive Loss¶
In modern recommendation system, it is common to have two major distinct stages, a recall/retrieval stage, and a ranking stage [2] [3]. In this article, we'll be discussing these two stages in the context of a pre-trained encoder model, where different types of architectures are commonly used at different stages to reflect their own strength.
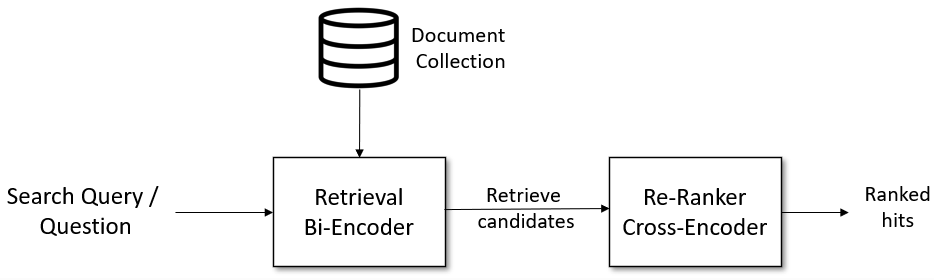
Recall/Retrieval focuses on candidate generation, given we have a million things be it inventories, passages, etc. stored in our database, we need a way to efficiently retrieve a subset of them that are more relevant for the given context. In encoder model's paradigm, this means we need a way to represent our incoming context be it query, questions, etc. in a vector representation, often times referred to as sentence embedding and perform a similarity search between that with entities that are also already represented in a sentence embedding. This step is often done using the bi-encoder architecture, where we can pass individual sentences/entities through our encoder and then perform similarity search using metrics such as cosine similarity. Being able to input individual entities through our encoder is the key to an effient retrieval stage, where we need to quickly scan through our database, as it means we can often times pre-compute these results apriori.

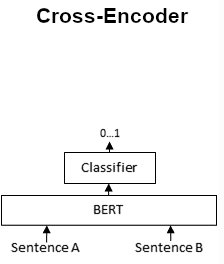
These subsets are then passed to the ranker, where given we now have our pairs, we need to score these pairs so the system can assign a score to rank these retrieved inventories in a sorted order. This step is often done using cross encoder, a.k.a. cross attention architectures. Cross encoder doesn't produce sentence embeddings for our data but instead relies on classification mechansim for out input pairs, hence whenever we have a fixed set of data pairs we wish to score, cross encoder often times achieves better performance than their bi encoder counterparts even when using less training data.
In this document, our focus will be how to train bi-encoder style architecture using contrastive loss [1] [4].
Contrastive Loss¶
For Bi-encoder, our input data at the bare minimum needs to contain positive pairs, where we need to be creative and define what's the definition for positive pairs based on our use case. These pairs are often referred to as anchors $a$ and positives, $p$. Given our dataset, the standard architecture for these type of task is a siamese network. Each base arm involves using a pre-trained encoder followed by a pooling operator for deriving a fix sized sentence embedding vector. During each step we feed both our anchor and positive one at time through the same encoder plus pooling arm. This encoder plus pooling arm's weights are often tied for our pairs. Tying weights ensure similar entities are mapped to similar locations in the representation space.
For training this network, what we wish to accomplish is have our anchor and positive pairs $a_i$ and $p_i$ become closer in the vector space, whereas $a_i$ and some random negative examples $p_j$ becomes distant in vector space.
\begin{align} L = -\frac{1}{n} \sum^n_{i=1} \frac{exp(sim(a_i, p_i))}{\sum_j exp(sim(a_i, p_j))} \end{align}Where $sim$ is a similarity function such as cosine similarity or dot product. This can then be treated as a classification task using cross entropy loss. $p_j$ is often times sampled using in batch negatives, meaning for each example in a batch, other examples' positives will be taken as its negatives, this effectively re-uses the already sampled data in our current batch without the need to implement additional negative sampling logic.
Dataset¶
For our dataset, we'll be using Stanford Natural Language Inference (SNLI) and Multi-Genre NLI (MNLI), refer to its link for more details on these two datasets. For constrastive loss, we will filter out premise and hypothesis pairs that has a label 0 assigned to it. These are positive samples where the premise suggests the hypothesis.
We'll also use the Semantic Textual Similarity Benchmark (stsb) dataset each contains sentence pairs with human annotated similarity score from 1 to 5 for evaluating our model's performance
# prevents progress bar and logging from flooding our document
disable_progress_bar()
set_verbosity_error()
stsb = load_dataset('glue', 'stsb', cache_dir=cache_dir)
# we normalize the score to a range of 0 ~ 1
stsb = stsb.map(lambda x: {'label': x['label'] / 5.0})
stsb = stsb.rename_column("sentence1", "anchor_text")
stsb = stsb.rename_column("sentence2", "positive_text")
stsb = stsb.remove_columns(["idx"])
stsb
stsb["validation"][1]
snli = load_dataset('snli', cache_dir=cache_dir)
mnli = load_dataset('glue', 'mnli', cache_dir=cache_dir)
mnli = mnli.remove_columns(['idx'])
snli = snli.cast(mnli["train"].features)
dataset_train = concatenate_datasets([snli["train"], mnli["train"]])
dataset_train = dataset_train.filter(lambda x: x['label'] == 0)
dataset_train = dataset_train.rename_column("premise", "anchor_text")
dataset_train = dataset_train.rename_column("hypothesis", "positive_text")
# note that we are evaluating the performance of our sentence embedding on
# stsb dataset without using any stsb samples in our training dataset
dataset_dict = DatasetDict({
"train": dataset_train,
"validation": stsb["train"],
"test": stsb["validation"]
})
dataset_dict
dataset_dict["train"][0]
# we can experiment with different pre-trained model checkpoint, e.g. "roberta-base"
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
model = AutoModel.from_pretrained(model_name, cache_dir=cache_dir)
As usual, we tokenize our anchor and positive text.
def tokenize_fn(examples):
tokenized = tokenizer(examples["anchor_text"], truncation=True, max_length=128)
examples["anchor_input_ids"] = tokenized["input_ids"]
examples["anchor_attention_mask"] = tokenized["attention_mask"]
tokenized = tokenizer(examples["positive_text"], truncation=True, max_length=128)
examples["positive_input_ids"] = tokenized["input_ids"]
examples["positive_attention_mask"] = tokenized["attention_mask"]
return examples
dataset_dict_tokenized = dataset_dict.map(
tokenize_fn,
batched=True,
num_proc=8,
remove_columns=["anchor_text", "positive_text"]
)
dataset_dict_tokenized
dataset_dict_tokenized["train"][0]
Here we also define a customize collate function for batching our dataset.
from dataclasses import dataclass
from typing import List, Dict, Optional, Union
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
from transformers.file_utils import PaddingStrategy
@dataclass
class DataCollatorForSiamese:
"""
Huggingface's DataCollatorWithPadding is for a single input, here we extend it
to take paired inputs.
References
----------
https://huggingface.co/docs/transformers/main_classes/data_collator#transformers.DataCollatorWithPadding
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
return_tensors: str = "pt"
def __call__(self, features: List[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
anchor_features = {
"input_ids": [feature["anchor_input_ids"] for feature in features],
"attention_mask": [feature["anchor_attention_mask"] for feature in features],
"label": [feature["label"] for feature in features]
}
pos_features = {
"input_ids": [feature["positive_input_ids"] for feature in features],
"attention_mask": [feature["positive_attention_mask"] for feature in features]
}
anchor_batch = self.tokenizer.pad(
anchor_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
pos_batch = self.tokenizer.pad(
pos_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
batch = {
"anchor_input_ids": anchor_batch["input_ids"],
"anchor_attention_mask": anchor_batch["attention_mask"],
"positive_input_ids": pos_batch["input_ids"],
"positive_attention_mask": pos_batch["attention_mask"],
"labels": anchor_batch["label"]
}
return batch
# sample output from a data loader
batch_size = 2
data_collator = DataCollatorForSiamese(tokenizer)
data_loader = DataLoader(dataset_dict_tokenized["train"], batch_size=batch_size, collate_fn=data_collator)
batch = next(iter(data_loader))
batch
Model¶
This section defines our transformer followed by pooling encoder, siamese network, evaluation metric, then proceed with using transformer library's Trainer class for training our network.
class TransformerPoolingEncoder(nn.Module):
def __init__(self, model_name: str, pooling_mode: str = "avg", cache_dir = None):
super().__init__()
if pooling_mode not in {"avg", "cls"}:
raise ValueError(f"{pooling_mode} needs to one of avg, cls")
self.base_model = AutoModel.from_pretrained(model_name, cache_dir=cache_dir)
self.pooling_mode = pooling_mode
def forward(self, input_ids, attention_mask):
output = self.base_model(input_ids=input_ids, attention_mask=attention_mask)
if self.pooling_mode == "avg":
# reshape attention mask to cover all hidden dimension
mask = attention_mask.unsqueeze(dim=-1).expand_as(output.last_hidden_state)
# perform mean pooling, but excluding attention mask
pooled = torch.sum(output.last_hidden_state * mask, dim=1) / torch.clamp(
mask.sum(dim=1), min=1e-9
)
elif self.pooling_mode == "cls":
pooled = output.last_hidden_state[:, 0, :]
return pooled
class SiameseModel(nn.Module):
"""
The loss function we are using is similar to Multiple Negative Ranking Loss that's mentioned
in the sentence bert package.
The similarity function implemented here is cosine similarity, with cosine similarity, we often
times add a scaling multiplier. As cosine similarity's range is between -1 and 1, this scaling
factor ensures our loss are large enough between positive and negative samples for the network
to train.
References
----------
https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss
"""
def __init__(self, model_name: str, scale: float = 20.0, pooling_mode: str = "avg", cache_dir = None):
super().__init__()
self.encoder = TransformerPoolingEncoder(model_name, pooling_mode, cache_dir)
self.scale = scale
def forward(
self,
anchor_input_ids,
anchor_attention_mask,
positive_input_ids,
positive_attention_mask,
labels=None
):
# [batch size, hidden dim]
anchor_embedding = self.encoder(
input_ids=anchor_input_ids,
attention_mask=anchor_attention_mask
)
positive_embedding = self.encoder(
input_ids=positive_input_ids,
attention_mask=positive_attention_mask
)
# cosine similarity
anchor_norm = F.normalize(anchor_embedding, p=2, dim=1)
positive_norm = F.normalize(positive_embedding, p=2, dim=1)
scores = torch.mm(anchor_norm, positive_norm.transpose(0, 1)) * self.scale
# Example a[i] should match with p[i]
labels = torch.arange(scores.size()[0], device=scores.device)
loss = F.cross_entropy(scores, labels)
return loss, anchor_embedding, positive_embedding
model = SiameseModel(model_name, cache_dir=cache_dir).to(device)
# sample forward output from the model given our input batch
for key, tensor in batch.items():
batch[key] = tensor.to(device)
with torch.no_grad():
output = model(**batch)
output
For our evaluation metric, we will first compute the cosine similarity of our pairs' embedding, then calculate pearson and spearman correlation with our ground truth similarity score.
def compute_metrics(eval_prediction):
anchor_embedding, positive_embedding = eval_prediction.predictions
labels = eval_prediction.label_ids
cosine_sim = 1 - paired_cosine_distances(anchor_embedding, positive_embedding)
pearson, _ = pearsonr(labels, cosine_sim)
spearman, _ = spearmanr(labels, cosine_sim)
return {"pearson": round(pearson, 3), "spearman": round(spearman, 3)}
os.environ['DISABLE_MLFLOW_INTEGRATION'] = 'TRUE'
finetuned_checkpoint = f"{model_name}-siamese"
training_args = TrainingArguments(
output_dir=finetuned_checkpoint,
num_train_epochs=2,
learning_rate=0.0001,
per_device_train_batch_size=64,
per_device_eval_batch_size=256,
weight_decay=0.01,
fp16=True,
evaluation_strategy=IntervalStrategy.STEPS,
save_strategy=IntervalStrategy.STEPS,
eval_steps=500,
save_steps=500,
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="spearman"
)
trainer = Trainer(
model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset_dict_tokenized['train'],
eval_dataset=dataset_dict_tokenized['validation'],
compute_metrics=compute_metrics,
callbacks = [EarlyStoppingCallback(early_stopping_patience=3)]
)
result = trainer.train()
trainer.evaluate(dataset_dict_tokenized["test"])
Evaluation¶
Quantitative benchmark on our test set shows we are capable of achieving a 80+% spearman correlation. This section performs a manual inspection on some sample input sentences, where some are more similar compared to others.
# tokenize our input sentences
sentences = [
"it caught him off guard that space smelled of seared steak",
"she could not decide between painting her teeth or brushing her nails",
"he thought there'd be sufficient time is he hid his watch",
"the bees decided to have a mutiny against their queen",
"the sign said there was road work ahead so she decided to speed up",
"on a scale of one to ten, what's your favorite flavor of color?",
"flying stinging insects rebelled in opposition to the matriarch"
]
batch = tokenizer(sentences, padding=True, max_length=128, truncation=True, return_tensors="pt")
batch
# feed it through our siamese network's encoder
with torch.no_grad():
embeddings = model.encoder(batch["input_ids"].to(device), batch["attention_mask"].to(device))
embeddings = embeddings.cpu().numpy()
embeddings
Given our sentence embedding, we then perform a cosine similarity for finding semantically similar sentences. Notice our trained model was able to capture sentences that have very few matching words but are semantically similar.
The comparison is not shown here, but we can compare this with results from out of the box pre-trained models and see that further training these networks with constrastive loss makes day and night differences. i.e. if we were to directly retrieve sentence embeddings by either pooling its last hidden output/layer or extracting first token ([CLS] token)'s embedding, it often times yield rather poor sentence embeddings as mentioned in sentence BERT [5].
input_embedding = embeddings[-1].reshape(1, -1).repeat(embeddings[:-1].shape[0], axis=0)
candidate_embedding = embeddings[:-1]
scores = 1 - paired_cosine_distances(input_embedding, candidate_embedding)
scores
print(sentences[-1])
for i, score in enumerate(scores):
score = round(float(score), 4)
sentence = sentences[i]
print(f"{score} | {sentence}")
In this document, we walked through a modern baseline approach for training sentence transformers. Modern in a sense that we are building on top of pre-trained language models instead of training from scratch, baseline meaning there're a lot more we can do to improve these models' performance, we'll take a look at those tricks in future documents.
Reference¶
- [1] Blog: Next-Gen Sentence Embeddings with Multiple Negatives Ranking Loss
- [2] Blog: Real World Recommendation System – Part 1
- [3] Sentence Transformers Documentation: Retrieve & Re-Rank
- [4] Github: Sentence Transformers Training Natural Language Inference
- [5] Paper: Nils Reimers, Iryna Gurevych - Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks - 2019