# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', '..', '..', 'notebook_format'))
from formats import load_style
load_style(css_style='custom2.css', plot_style=False)
os.chdir(path)
%load_ext watermark
%load_ext autoreload
%autoreload 2
import math
import peft
import faiss
import torch
import datasets
import transformers
import numpy as np
import pandas as pd
import torch.nn as nn
import pytorch_lightning as pl
import torch.nn.functional as F
import torch.distributed as dist
from torch.optim import AdamW
from torch.distributed import nn as dist_nn
from torch.utils.data import DataLoader
from datasets import load_dataset
from peft import LoraConfig, TaskType, get_peft_model
from transformers.utils import PaddingStrategy
from transformers import PreTrainedTokenizerBase
from transformers.data.data_collator import DataCollatorMixin
from transformers import (
AutoModel,
AutoTokenizer,
PretrainedConfig,
PreTrainedModel,
PreTrainedTokenizerBase
)
from dataclasses import dataclass
from typing import List, Optional, Dict, Any, Union
%watermark -a 'Ethen' -d -u -v -iv
Multilingual Sentence Embedding with LLM and PEFT LORA¶
In this article, we'll be taking a look at training a multilingual sentence embedding with Large Language Model (LLM) and a parameter efficient fine tuning technique: LoRA (Low Rank Adaption).
LLM For Retrieval¶
Large Language Model (LLM) with billion of parameters, fine-tuned to follow instructions have showcased remarkable capabilities on many NLP tasks. Consequently, there's a growing interest in harnessing these models as retrieval systems, such as LLAMA-2 [7], GPT [10], Mistral [11].
RepLLaMA/RankLLaMA [7] leverages LLAMA-2-7B as backbone model for training retrieval and re-ranker model. Previous work on dense retriever models often uses bi-directional encoder model like BERT, taking the representation of prepended special [CLS] token or average pooling as sentence embedding. Given LLAMA is a uni-directional decoder only, an end of sentence token <\s> is appended to serve as embedding.
For addressing high GPU memory cost associated with fine tuning large models with contrastive learning, they leverage memory efficiency solutions such as LoRA, flash attention, and gradient checkpointing. The model is trained on 16 x 32G V100 GPUs with a batch size of 128, hard negatives from a blend of BFM25 and CoCondenser to ensure hard negatives are derived from both sparse and dense retrieval results.
Apart from potent performance when evaluated on in-domain dataset MS MARCO and zero shot evaluation on BEIR benchmark suite, it also offers the advantage that modern LLM are often pre-trained with longer context window.
LoRA¶
In modern transformer pre-trained model era, many application rely on fine tuning one large pre-trained model to multiple down stream applications. Given the higher associated cost with fine tuning, many sought to adapt only partial parameters, i.e. freezing base layers. LoRA (Low Rank Adaptation) [9] presents an alternative approach by representing the weight update with two low rank matrices.
Quoting the LoRA paper: Given a weight matrix $W_0 \in \mathbb{R}^{d \times d}$, we would constrain its update $W_0 + \Delta W = W_0 + BA$, where $B \in \mathbb{R}^{d \times r}$, $B \in \mathbb{R}^{r \times d}$. During training $W_0$ is frozen, while $A$ and $B$ contain trainable parameters. Both set of matrices would receiving the same input during forward pass: $W_0 x + \alpha \Delta W x = W_0 x + \alpha BA x$, where $\alpha$ is a scaling constant. At the beginning, $A$ is initialized with random Gaussian, and zero for $B$.
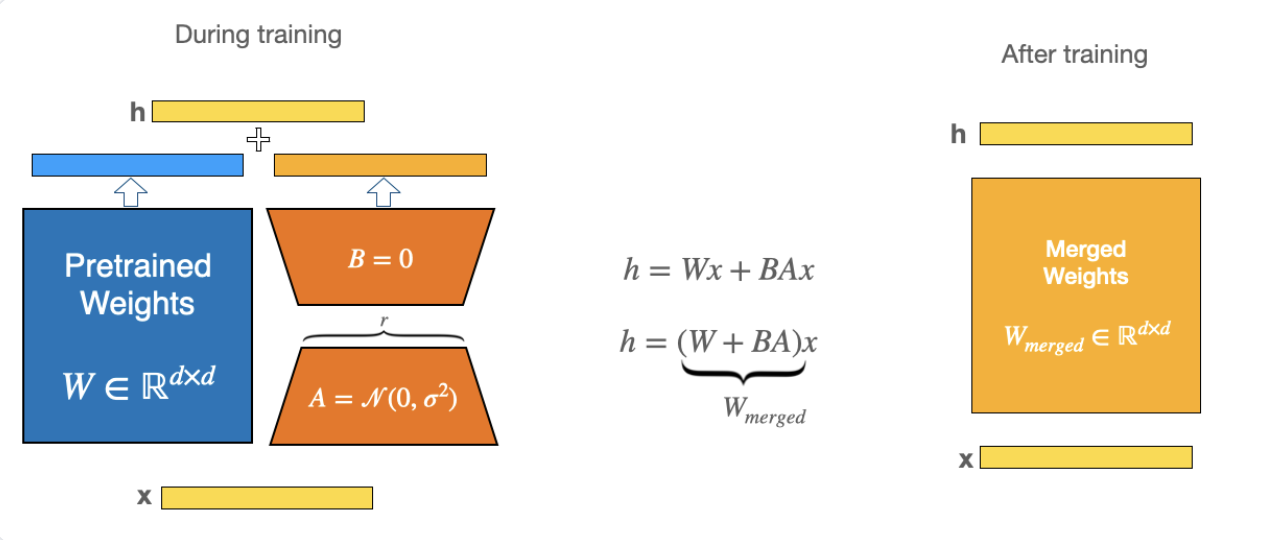
Its advantages:
- A pre-trained model can be shared, and use to build many small LoRA modules for different tasks.
- Compared to full fine tuning, training becomes more efficien as it drastically reduces the number of trainable parameters. Lowering the hardware barrier as well as accelerating training cycle, especially when it comes to billion sized pre-trained models.
- Its linear design allows us to merge LoRA's trainable matrices with the original frozen weights, effectively introducing zero additional inference latency compared to the original model.
# simplified lora linear layer
class LoraLinear(nn.Module):
def __init__(
self,
in_features,
out_features,
rank,
alpha,
bias=True,
device=None,
dtype=None
):
super().__init__(in_features, out_features, bias, device, dtype)
self.rank = rank
self.alpha = alpha
self.lora_A = nn.Parameters(torch.rand(in_features, rank))
self.lora_B = nn.Parameters(torch.zeros(rank, out_features))
# freeze the original linear layer's weight matrix
self.weight.requires_grad = False
def forward(self, x):
lora_weights = x @ self.lora_A @ self.lora_B * self.alpha
return super().forward(x) + lora_weights
Data¶
We'll be utilizing the bloomz model family as our tokenizer/model. We have the flexibility to substitute it with any other Language Model Models (LLMs), we've opted for the bloomz model family for its multilingual capabilities.
ESCI¶
For our dataset, we taking inspiration from one of the examples from peft library's [2] documentation. Specifically, we'll be using a small subset of ESCI e-commerce search query dataset that's conveniently available on huggingface dataset. The ESCI dataset [3] [8], available in multiple languages including English, Japanese, and Spanish, consists of challenging search queries (such as those involving negations: "energy bar without nuts" or "gluten-free biscuits") paired with up to 40 search results, along with their ESCI (Exact, Substitute, Complement, Irrelevant) judgments. Our task at hand will be to train a model for retrieving similar products for a given query.
# https://huggingface.co/bigscience/bloomz-1b7
model_name_or_path = "bigscience/bloomz-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
dataset_name = "smangrul/amazon_esci"
dataset_dict = load_dataset(dataset_name).filter(lambda example: example["relevance_label"] == 1)
print(dataset_dict["train"][0])
dataset_dict
@dataclass
class DataCollatorForSentenceEmbedding(DataCollatorMixin):
"""
tokenize raw text as well as padding while forming a batch for data loader.
Append eos token for downstream embedding representation.
"""
tokenizer: Optional[PreTrainedTokenizerBase] = None
max_seq_len_1: int = 512
max_seq_len_2: int = 512
id_field: str = "__index_level_0__"
text_field_1: str = "query"
text_field_2: str = "product_title"
process_tower: Optional[str] = None
padding: Union[bool, str, PaddingStrategy] = True
return_tensors: str = "pt"
def __call__(self, features: List[Dict[str, Any]], return_tensors=None) -> Dict[str, Any]:
# id could be a string column, and is also not part module's forward pass
# hence converting to torch tensor isn't needed
ids = [feature[self.id_field] for feature in features]
if self.process_tower == "tower_1":
formatted_text = [feature[self.text_field_1] + tokenizer.eos_token for feature in features]
tokenized_text_1 = self.tokenizer(
text=formatted_text,
padding=self.padding,
max_length=self.max_seq_len_1,
truncation=True,
return_attention_mask=True,
return_tensors=self.return_tensors
)
batch = {
"ids": ids,
"input_ids": tokenized_text_1["input_ids"],
"attention_mask": tokenized_text_1["attention_mask"]
}
elif self.process_tower == "tower_2":
formatted_text = [feature[self.text_field_2] + tokenizer.eos_token for feature in features]
tokenized_text_2 = self.tokenizer(
text=formatted_text,
padding=self.padding,
max_length=self.max_seq_len_2,
truncation=True,
return_attention_mask=True,
return_tensors=self.return_tensors
)
batch = {
"ids": ids,
"input_ids": tokenized_text_2["input_ids"],
"attention_mask": tokenized_text_2["attention_mask"]
}
else:
formatted_text_1 = [feature[self.text_field_1] + tokenizer.eos_token for feature in features]
tokenized_text_1 = self.tokenizer(
text=formatted_text_1,
padding=self.padding,
max_length=self.max_seq_len_1,
truncation=True,
return_attention_mask=True,
return_tensors=self.return_tensors
)
formatted_text_2 = [feature[self.text_field_2] + tokenizer.eos_token for feature in features]
tokenized_text_2 = self.tokenizer(
text=formatted_text_2,
padding=self.padding,
max_length=self.max_seq_len_2,
truncation=True,
return_attention_mask=True,
return_tensors=self.return_tensors
)
batch = {
"ids": ids,
"input_ids_1": tokenized_text_1["input_ids"],
"input_ids_2": tokenized_text_2["input_ids"],
"attention_mask_1": tokenized_text_1["attention_mask"],
"attention_mask_2": tokenized_text_2["attention_mask"]
}
return batch
data_collator = DataCollatorForSentenceEmbedding(tokenizer)
dataloader_train = DataLoader(
dataset_dict["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=2,
pin_memory=True,
)
batch = next(iter(dataloader_train))
batch
Model¶
The following next code chunk defines a huggingface compatible SentenceEmbeddingModel for training retrieval model using contrastive learning. For actual LoRA experimentation, we'll directly leverage peft library.
class SentenceEmbeddingModelConfig(PretrainedConfig):
model_type = "sentence_embedding"
def __init__(
self,
model_name: str,
normalize: bool = True,
cross_gpu_negatives: bool = False,
enable_gradient_checkpointing: bool = True,
peft_config = None
):
self.model_name = model_name
self.normalize = normalize
self.cross_gpu_negatives = cross_gpu_negatives and torch.cuda.device_count() > 1
self.enable_gradient_checkpointing = enable_gradient_checkpointing
self.peft_config = peft_config
class SentenceEmbeddingModel(PreTrainedModel):
"""
InfoNCE style contrastive loss sentence embedding.
Uses last token (eos) as embedding representation,
gradient checkpointing, LoRA for memory efficient training
"""
config_class = SentenceEmbeddingModelConfig
def __init__(self, config):
super().__init__(config)
self.config = config
model = AutoModel.from_pretrained(config.model_name)
if config.enable_gradient_checkpointing:
model.gradient_checkpointing_enable(
gradient_checkpointing_kwargs={"use_reentrant": False}
)
self.model = model
if config.peft_config:
self.model = get_peft_model(model, config.peft_config)
self.model.print_trainable_parameters()
self.loss = CLIPLoss(config.cross_gpu_negatives)
def forward(
self,
input_ids_1,
attention_mask_1,
input_ids_2,
attention_mask_2,
):
embeddings_1 = self.encode(input_ids_1, attention_mask_1)
embeddings_2 = self.encode(input_ids_2, attention_mask_2)
loss = self.loss(embeddings_1, embeddings_2)
return loss, embeddings_1, embeddings_2
def encode(self, input_ids, attention_mask):
model_output = self.model(input_ids=input_ids, attention_mask=attention_mask)
embeddings = last_token_pooling(model_output.last_hidden_state, attention_mask)
if self.config.normalize:
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
def last_token_pooling(last_hidden_states, attention_mask):
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
class CLIPLoss(nn.Module):
"""
Symmetric contrastive learning, a.k.a. CLIP loss or
Multiple Negative Ranking Loss that's mentioned in the sentence bert package.
References
----------
- https://arxiv.org/abs/2103.00020
- https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss
"""
def __init__(self, cross_gpu_negatives: bool = True):
super().__init__()
self.cross_gpu_negatives = cross_gpu_negatives
# trainable temperature parameters
# This initial value is based on open clip
# https://github.com/mlfoundations/open_clip/blob/4b929357093bfbb0986b61cfa23776f1dc740370/src/open_clip/model.py
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def forward(self, anchor_embedding, positive_embedding):
with torch.no_grad():
self.logit_scale.clamp_(0, math.log(100))
logit_scale = self.logit_scale.exp()
if self.cross_gpu_negatives:
anchor_embedding_all_gathered = torch.cat(dist_nn.all_gather(anchor_embedding), dim=0)
positive_embedding_all_gathered = torch.cat(dist_nn.all_gather(positive_embedding), dim=0)
anchor_scores = anchor_embedding @ positive_embedding_all_gathered.T * logit_scale
positive_scores = positive_embedding @ anchor_embedding_all_gathered.T * logit_scale
rank = dist.get_rank()
else:
anchor_scores = anchor_embedding @ positive_embedding.T * logit_scale
positive_scores = positive_embedding @ anchor_embedding.T * logit_scale
rank = 0
# Example a[i] should match with p[i]
batch_size = anchor_scores.size()[0]
labels = torch.arange(batch_size, device=anchor_scores.device, dtype=torch.long)
labels = labels + batch_size * rank
loss = (F.cross_entropy(anchor_scores, labels) + F.cross_entropy(positive_scores, labels)) / 2
return loss
As part of our LoraConfig, we need to specify target_modules, which checks if the specified substring is in module's full name. LoRA can be applied to any module in our model, though the most common practice for transformer style model is applying to to attention layer's key, value, query matrices as well as its immediate feed forward layer.
With our LoRA setup along with gradient checkpointing, we are able to train a 1.7B model using a single V100 GPU with micro batch size of 64.
# https://huggingface.co/docs/peft/en/package_reference/lora
peft_config = LoraConfig(
r=8,
lora_alpha=16,
bias="none",
task_type=TaskType.FEATURE_EXTRACTION,
# check each model's corresponding module name,
# e.g. for BERT, target_modules=["key", "query", "value"],
target_modules=["query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h"],
# parameters that were not injected with LoRA are automatically
# frozen, if we wish to train them, specify them via
# modules_to_save
)
sentence_embedding_model_config = SentenceEmbeddingModelConfig(
model_name_or_path,
peft_config=peft_config
)
sentence_embedding_model = SentenceEmbeddingModel(sentence_embedding_model_config)
sentence_embedding_model
ids = batch.pop("ids")
output = sentence_embedding_model(**batch)
class SentenceEmbeddingLightningModule(pl.LightningModule):
def __init__(self, sentence_embedding_model: SentenceEmbeddingModel):
super().__init__()
self.sentence_embedding_model = sentence_embedding_model
# huggingface auto model loads model in eval mode. Latest version of
# pytorch lightning no longer auto converts model to train mode during
# trainer fit stage, end user need to explicitly call them
# https://github.com/Lightning-AI/pytorch-lightning/issues/19467#issuecomment-1942741283
self.sentence_embedding_model.train()
def forward(self, **batch):
return self.sentence_embedding_model(**batch)
def training_step(self, batch, batch_idx):
ids = batch.pop("ids")
outputs = self(**batch)
loss = outputs[0]
self.log("train_loss", loss, prog_bar=True)
return loss
def predict_step(self, batch, batch_idx):
ids = batch.pop("ids")
embeddings = self.sentence_embedding_model.encode(**batch)
prediction_output = {"ids": ids, "embeddings": embeddings}
return prediction_output
def configure_optimizers(self):
model = self.sentence_embedding_model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": 0.001,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=0.0001)
return optimizer
sentence_embedding_module = SentenceEmbeddingLightningModule(sentence_embedding_model)
trainer = pl.Trainer(
accelerator="gpu",
devices=-1,
max_steps=2000,
precision="16-mixed",
# note, we purpose-fully disabled the progress bar to prevent flooding our notebook's console
# in normal settings, we can/should definitely turn it on
enable_progress_bar=False,
log_every_n_steps=50,
)
dataloader_train = DataLoader(
dataset_dict["train"],
shuffle=True,
collate_fn=data_collator,
num_workers=2,
batch_size=64,
pin_memory=True,
)
trainer.fit(sentence_embedding_module, dataloader_train)
Evaluation¶
Evaluation process involves:
- Generating embeddings for both distinct queries and products (corpus).
- Retrieve top-k products using FAISS's flat index, i.e. exact cosine similarity.
- Compute evaluation metrics, in this case recall@k.
# get the original model back for running inference
sentence_embedding_module.sentence_embedding_model.model = sentence_embedding_module.sentence_embedding_model.model.merge_and_unload()
sentence_embedding_module
def postprocess_predictions(predictions):
prediction_outputs = {"ids": [], "embeddings": []}
for prediction in predictions:
prediction_outputs["ids"].extend(prediction["ids"])
embeddings = [embedding for embedding in prediction["embeddings"].cpu().numpy()]
prediction_outputs["embeddings"].extend(embeddings)
return pd.DataFrame(prediction_outputs)
df_validation = dataset_dict["validation"].to_pandas()
df_validation
df_query = df_validation[["query"]].drop_duplicates().reset_index(drop=True)
dataset_query = datasets.Dataset.from_pandas(df_query)
data_collator = DataCollatorForSentenceEmbedding(
tokenizer,
process_tower="tower_1",
id_field="query"
)
dataloader = DataLoader(
dataset_query,
shuffle=False,
collate_fn=data_collator,
batch_size=64,
pin_memory=True,
num_workers=2
)
predictions = trainer.predict(sentence_embedding_module, dataloader)
df_query = postprocess_predictions(predictions)
df_query
df_product = df_validation[["product_id", "product_title"]].drop_duplicates().reset_index(drop=True)
dataset_product = datasets.Dataset.from_pandas(df_product)
data_collator = DataCollatorForSentenceEmbedding(
tokenizer,
process_tower="tower_2",
id_field="product_id"
)
dataloader = DataLoader(
dataset_product,
shuffle=False,
collate_fn=data_collator,
batch_size=64,
pin_memory=True,
num_workers=2
)
predictions = trainer.predict(sentence_embedding_module, dataloader)
df_corpus = postprocess_predictions(predictions)
df_corpus
index_ids = df_corpus["ids"].tolist()
index_embeddings = np.vstack(df_corpus["embeddings"]).astype(np.float32)
query_embeddings = np.vstack(df_query["embeddings"]).astype(np.float32)
dim = index_embeddings.shape[1]
topk = 10
knn_index = faiss.IndexFlatIP(dim)
knn_index = faiss.index_cpu_to_all_gpus(knn_index)
knn_index.add(index_embeddings)
knn_scores, knn_indices = knn_index.search(query_embeddings, k=topk)
knn_indices
# convert knn retrieval result to {query -> [list of knn retrieved corpus id]}
knn_dict = {}
for query, knn_indices_per_row in zip(df_query["ids"], knn_indices):
corpus_indices_per_row = [index_ids[index] for index in knn_indices_per_row]
knn_dict[query] = corpus_indices_per_row
# convert validation dataset to {query -> [list of ground truth corpus id]}
eval_dict = {}
for query, product_id in zip(df_validation["query"], df_validation["product_id"]):
if query not in eval_dict:
eval_dict[query] = [product_id]
else:
eval_dict[query].append(product_id)
def compute_metrics(
knn_dict,
eval_dict,
top_k: int
):
recalls = []
for query, knn_results in knn_dict.items():
knn_set = set(knn_results)
eval_set = set(eval_dict[query])
numerator = len(knn_set.intersection(eval_set))
denominator = min(len(eval_set), top_k)
recall = numerator / denominator
recalls.append(recall)
avg_recall = np.mean(recalls)
return avg_recall
compute_metrics(knn_dict, eval_dict, topk)
We conclude our article by offering some guidance when training with LoRA as well as decoder based retrieval models.
LoRA:
- The most critical LoRA hyperparameter is how many LoRA adapters are used in total and LoRA on all linear transformer block layers are required to match full fine tuning's performance. Other parameters such as projection dimension $r$ doesn't affect performance much. i.e. It's more preferable to adapt more weight matrices than adapting a single type of weights with a larger rank.
- When training with LoRA a lower learning rate as well as more steps might be required for matching full fine tuning's performance.
- The effective of LoRA might be task dependent. Compared to full fine tuning, LoRA might stumble when ecountering more challenging tasks such as mathematical reasoning [5].
Personally, LoRA feels very much akin to matrix factorization, factorization machines family of methods with a twist.
Decoder retrieval models:
- Exploring LLMs' usage in embedding have garnered quite some interest with good reason, e.g. Improving text embeddings with LLMs [11] showed that using LLMs (Mistral 7B) as an initial backbone using synthetic data along with some moderate amount of labeled text pairs is sufficient, foregoing the need for large amounts of text pairs to obtain high quality embeddings.
- Keep in mind that apart from performance, there's also the cost of operating these large LLMs for embedding use case. This is from a inference speed perspective as well as storage (billion parameter scale LLM typically involves generating a larger embedding hidden dimension, 2048+)[6]
Reference¶
- [1] PEFT Documentation: LoRA
- [2] PEFT Documentation: LoRA for semantic similarity tasks
- [3] Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
- [4] LoRA From Scratch – Implement Low-Rank Adaptation for LLMs in PyTorch
- [5] Fine-Tuning LLMs: LoRA or Full-Parameter? An in-depth Analysis with Llama 2
- [6] OpenAI GPT-3 Text Embeddings - Really a new state-of-the-art in dense text embeddings?
- [7] Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, Jimmy Lin - Fine-Tuning LLaMA for Multi-Stage Text Retrieval (2023)
- [8] Chandan K. Reddy, Lluís Màrquez, Fran Valero, Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopadhyay, Arnab Biswas, Anlu Xing, Karthik Subbian - Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search (2022)
- [9] Edward J. Hu, Yelong Shen, et al. - LoRA: Low-Rank Adaptation of Large Language Models (2021)
- [10] Arvind Neelakantan, Tao Xu, et al. - Text and Code Embeddings by Contrastive Pre-Training (2022)
- [11] Liang Wang, Nan Yang, Furu Wei, et al. - Improving Text Embeddings with Large Language Models (2024)