# code for loading the format for the notebook
import os
# path : store the current path to convert back to it later
path = os.getcwd()
os.chdir(os.path.join('..', 'notebook_format'))
from formats import load_style
load_style(plot_style = False)
os.chdir(path)
# 1. magic for inline plot
# 2. magic to print version
# 3. magic so that the notebook will reload external python modules
# 4. magic to enable retina (high resolution) plots
# https://gist.github.com/minrk/3301035
%matplotlib inline
%load_ext watermark
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pyspark.sql.functions as F
from pyspark.conf import SparkConf
from pyspark.sql import SparkSession
# create the SparkSession class,
# which is the entry point into all functionality in Spark
# The .master part sets it to run on all cores on local, note
# that we should leave out the .master part if we're actually
# running the job on a cluster, or else we won't be actually
# using the cluster
spark = (SparkSession.
builder.
master('local[*]').
appName('crime').
config(conf = SparkConf()).
getOrCreate())
# set the log level to ERROR to prevent
# the terminal from showing too many information
sc = spark.sparkContext
sc.setLogLevel('ERROR')
%watermark -a 'Ethen' -d -t -v -p numpy,pandas,matplotlib,pyspark
Spark Exercise¶
Note that the following notebook is not a tutorial on the basics of spark, it assumes you're already somewhat familiar with it or can pick it up quickly by checking documentations along the way. Please use the following link to download the dataset.
Question 1¶
By using SparkSQL generate a bar chart of average crime events by month. Find an explanation of results
# have a peek at the data
data_path = 'Crimes_-_2001_to_present.csv'
df = spark.read.csv(data_path, sep = ',', header = True)
df.take(1)
# extract the month and year from the date column
split_col = F.split(df['Date'], ' ')
df = df.withColumn('Day', split_col.getItem(0))
split_col = F.split(df['Day'], '/')
df = df.withColumn('Month', split_col.getItem(0))
df = df.withColumn('Year', split_col.getItem(2))
df.take(1)
# register the DataFrame as a SQL temporary view, so
# we can directly use SQL query to interact with spark DataFrame
df.createOrReplaceTempView('crime')
sql_query = ("""
SELECT Month, COUNT(*) / COUNT(DISTINCT Year) AS Average
FROM crime
GROUP BY Month
ORDER BY Month
""")
avg_month = spark.sql(sql_query).toPandas()
avg_month.to_csv('avg_month.txt', index = False)
avg_month
plt.rcParams['figure.figsize'] = 8, 6
plt.rcParams['font.size'] = 12
plt.bar(avg_month['Month'].astype('float64'), avg_month['Average'])
plt.title('Average Crime Count Throughout the Year')
plt.xticks(range(1, 13))
plt.show()

Judging from the plot below, we can see that the average crime count tends to be higher during the summer. The reason behind this phenomenon might be:
- Elevated temperature makes people more irritable, which leads to a rise in aggressive behavior and crime.
- During the summer, people tend to leave their windows open more often to cool down or spend more time outside to enjoy outdoor activities. Both of them gives burglars more opportunity to break into people's home.
Question 2¶
- Find the top 10 blocks in crime events in the last 3 years
- Find the two beats that are adjacent with the highest correlation in the number of crime events (this will require you looking at the map to determine if the correlated beats are adjacent to each other) over the last 5 years
- Determine if the number of crime events is different between Mayors Daly and Emanuel at a granularity of your choice (not only at the city level). Find an explanation of results. Side information: Rahm Emanuel is the current mayor of Chicago, and Richard Daley was his predecessor (left the office in 2011)
The following section also contains a small example of how to use the mapPartition function.
# suppose our task if to find the maximum temperature of the year 1901, 1902
temp = sc.parallelize(['1901,52', '1901,45', '1902,50', '1902,70', '2000,100'])
# since map works with a single record, for each input there has to be an output
# hence we have to write a separate map and filter function to filter out the record
# that does not belong to 1901, 1902
(temp.
map(lambda x: x.split(',')).
filter(lambda x: x[0] in {'1901', '1902'}).
reduceByKey(lambda x, y: max(x, y)).
collect())
def filter_year(iterable):
# loop through each data point in
# the chunk of data and do whatever
for line in iterable:
year, temperature = line.split(',')
if year in {'1901', '1902'}:
yield year, temperature
# by using mapPartition we can use a function to work
# with each partition (i.e. chunk of data), thus we
# can combine the map and filter logic within each partition
(temp.
mapPartitions(filter_year).
reduceByKey(lambda x, y: max(x, y)).
collect())
# extract the year from the date column
data_path = 'Crimes_-_2001_to_present.csv'
df = spark.read.csv(data_path, sep = ',', header = True)
split_col = F.split(df['Date'], ' ')
df = df.withColumn('Day', split_col.getItem(0))
split_col = F.split(df['Day'], '/')
df = df.withColumn('Month', split_col.getItem(0).cast('int'))
df = df.withColumn('Year', split_col.getItem(2).cast('int'))
# obtain the starting year for the notion of last three year
unique_years = (df.
select(df['Year']).
distinct().
orderBy('Year').
rdd.map(lambda x: x.Year).
collect())
n_years = 3
year_threshold = unique_years[-n_years]
year_threshold
# top 10 blocks in terms of crime events
n_top = 10
crime_per_block = (df.
filter(df['Year'] >= year_threshold).
groupBy('Block').
count().
orderBy('count', ascending = False).
limit(n_top).
toPandas())
crime_per_block
For part 1, the top 10 blocks in terms of number of crime events are places either in downtown Chicago or the South part of Chicago. This is probably due to the fact that those areas are densely populated, hence increases the chance of crime occurence.
For the problem of finding the two beats that are adjacent with the highest correlation in the number of crime events, I decided to use the rdd corr function from the mllib package to perform the operation. Even thought there's a DataFrame corr function, I couldn't find an easy way to utilize that API.
# compare correlation across years
n_years = 5
year_threshold = unique_years[-n_years]
def filter_year(iterable):
for beat, year in iterable:
if year >= year_threshold:
yield (beat, year), 1
# the sort by key is just to make the output
# cleaner, we don't actually need it
crime_per_group = (df.
select(df['Beat'], df['Year']).
rdd.mapPartitions(filter_year).
reduceByKey(lambda x, y: x + y).
sortByKey())
crime_per_group.take(10)
def beat2key(x):
(beat, year), count = x
# choose a random delimiter to separate the
# two values and the next value that will be
# concatenated to it
value = str(year) + ',' + str(count) + ';'
return beat, value
# combine the count for each beat together
# into one string value
crime_per_beat = (crime_per_group.
map(beat2key).
reduceByKey(lambda x, y: x + y))
crime_per_beat.take(3)
def get_count_per_year(iterable):
for beat, value in iterable:
# filter out the last ';'
year_and_count = value.split(';')[:-1]
if len(year_and_count) == n_years:
year_and_count = [tuple(e.split(',')) for e in year_and_count]
for year, count in year_and_count:
value = beat + ',' + count + ';'
yield year, value
# convert the single string value into numeric value and
# filter out any beat that does not have all the values,
# i.e. does not have records for all the year;
# also convert year as key since the correlation function
# assumes that each column is a record as oppose to each row
count_per_year = (crime_per_beat.
mapPartitions(get_count_per_year).
reduceByKey(lambda x, y: x + y))
count_per_year.take(1)
def get_unique_beats(count_per_year):
unique_beats = []
_, value = count_per_year
beat_and_count = value.split(';')[:-1]
beat_and_count = [tuple(e.split(',')) for e in beat_and_count]
beat_and_count = sorted(beat_and_count)
for beat, _ in beat_and_count:
unique_beats.append(beat)
return unique_beats
# load all the distinct beat into memory,
# feasible since there's only around 300 of them
unique_beats = get_unique_beats(count_per_year.first())
len(unique_beats)
from pyspark.mllib.stat import Statistics
def get_beat_count(x):
_, value = x
beat_and_count = value.split(';')[:-1]
beat_and_count = [tuple(e.split(',')) for e in beat_and_count]
beat_and_count = sorted(beat_and_count)
count = [int(count) for _, count in beat_and_count]
return count
raw_count = count_per_year.map(get_beat_count)
corr_m = Statistics.corr(raw_count, method = 'pearson')
corr_m.flags['WRITEABLE'] = True
corr_m
def most_similar_pair(pairwise, topn = 3, ascending = False):
"""
Obtain the topn most/least similar pair of the input
similarity matrix.
Paramters
---------
pairwise : 2d ndarray
Pairwise similarity matrix.
topn : int, default 3
Top N most similar/dissimilar pair's N.
ascending : bool, default False
Whether to find the most similar of dissimilar pair.
Returns
-------
rows, cols : 1d ndarray
Indices of the pair.
"""
pairwise = pairwise.copy()
if not ascending:
# the item is always most similar to itself
# exclude that from the calculation if
# we're computing the most similiar
np.fill_diagonal(pairwise, 0.)
# flatten the 2d correlation matrix and
# sort it by decreasing order
corr_result = np.ravel(pairwise)
indices = np.argsort(corr_result)
if not ascending:
indices = indices[::-1]
# we then grab the top n elements;
# since correlation matrix is symmetric,
# we take the largest n * 2 and with a stride of 2
largest_indices = indices[:(topn * 2):2]
# obtain the corresponding index in the
# original correlation matrix (e.g. element (3, 2)
# contains the largest value thus it comes first)
rows, cols = np.unravel_index(largest_indices, pairwise.shape)
return rows, cols
n_largest = 100
rows, cols = most_similar_pair(corr_m, topn = n_largest)
rows, cols
After computing the year-level crime number correlation between all the pairwise beats combination and outputting the top 100 combination, the two adjacent beats that have the highest correlation is listed below (this is done by manually inspecting the top 100 pairs).
results = []
for i, j in zip(rows, cols):
result = [unique_beats[i], unique_beats[j], corr_m[i, j]]
results.append(result)
df_corr = pd.DataFrame(results, columns = ['beat1', 'beat2', 'corr'])
df_corr[ (df_corr['beat1'] == '1121') & (df_corr['beat2'] == '1122') ]
For part 3, determining if the number of crime events is different between Mayors Daly and Emanuel, we will compute the monthly crime occurences per beat and perform a pair t-test to evaluate whether the difference is significant or not.
df = spark.read.csv(data_path, sep = ',', header = True)
split_col = F.split(df['Date'], ' ')
df = df.withColumn('Day', split_col.getItem(0))
split_col = F.split(df['Day'], '/')
df = df.withColumn('Month', split_col.getItem(0).cast('int'))
df = df.withColumn('Year', split_col.getItem(2).cast('int'))
emanuel = (df.
filter(df['Year'] > 2011).
groupBy('Beat', 'Month').
count().
withColumnRenamed('count', 'EmanuelCount'))
daley = (df.
filter(df['Year'] <= 2011).
groupBy('Beat', 'Month').
count().
withColumnRenamed('count', 'DaleyCount'))
joined = (emanuel.
join(daley, on = ['Beat', 'Month']).
withColumn('Diff', (F.col('EmanuelCount') - F.col('DaleyCount')).alias('double')))
joined.show()
# compute the pair t-test
test_info = (joined.
select(F.mean(F.col('Diff')).alias('Mean'),
F.stddev(F.col('Diff')).alias('Std'),
F.count(F.col('Diff')).alias('Count')).
rdd.map(lambda x: (x.Mean, x.Std, x.Count)).
collect())
test_info
# the t value is extremely large,
# indicating that there is a difference in crime
mean, std, count = test_info[0]
standard_error = std / np.sqrt(count)
tvalue = mean / standard_error
tvalue
We observe a large pair t-statistic when comparing monthly crime numbers between mayor Daley and Emanuel. This indicates the data provides strong evidence against the null hypothesis in which there is no difference in the number of crimes between the two mayors. And based on the way the number is calculated, a large negative number means there's significantly less number of crimes when Rahm Emanuel (the current mayor of Chicago) is mayor.
Question 3¶
Predict the number of crime events in the next week at the beat level.
- Framed the problem as a supervised machine learning problem, thus lagged features were created. i.e. we use week 1, 2, 3's number to predict the number for week 4. We could have framed it as a time series problem, but here we're simply using it as a chance to familarize ourselves with Spark ML's API
- Trained a RandomForest model for every beat level. This decision is due to the fact that if we were to only train one model, it would require us to one-hot encode around 300 different beat values, which is often times not ideal as a categorical variable with too many distinct levels often leads to overfitting
- For the RandomForest model, 3-fold cross validation and a grid search on the
maxDepthparameter was performed
A quick intro into the SQL window function:
Window functions operate on a set of rows and return a single value for each row from the underlying query. When we use a window function in a query, we define the window using the OVER() clause, which has the folloiwing capabilities:
- Defines window partitions to form groups of rows. (PARTITION BY clause)
- Orders rows within a partition. (ORDER BY clause)
e.g.
The following query uses the AVG() window function with the PARTITION BY clause to determine the average car sales for each dealer in Q1:
SELECT
emp_name, dealer_id, sales,
AVG(sales) OVER (PARTITION BY dealer_id) AS avgsales
FROM
q1_sales;
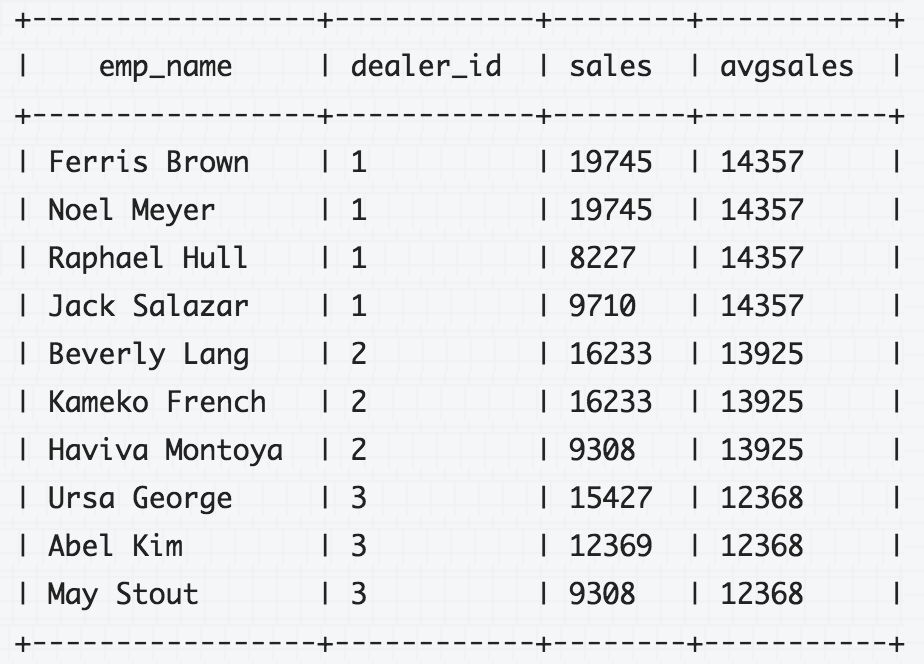
For more information, including different types of window function the following link gives a very nice overview. Drill Documentation: SQL Window Functions Introduction
from pyspark.sql.window import Window
# Reference
# ---------
# https://stackoverflow.com/questions/34295642/spark-add-new-column-to-dataframe-with-value-from-previous-row
d = sc.parallelize([(4, 9.0), (3, 7.0), (2, 3.0), (1, 5.0)]).toDF(['id', 'num'])
d.show()
# here we define a window to create a lagged feature,
# so every row gets shifted up by 1 (determined by the
# count parameter of the lag function); remember to drop
# the na value since there's no record before id1
w = Window().partitionBy().orderBy('id')
d = (d.
withColumn('new_col', F.lag(F.col('num'), count = -1).over(w)).
na.drop())
d.show()
from pyspark.sql.window import Window
from pyspark.sql.types import StringType
data_path = 'Crimes_-_2001_to_present.csv'
df = spark.read.csv(data_path, sep = ',', header = True)
def date2weeknumber(date):
"""
append a 0 in front of single digit week number,
this is used when sorting the week number so that
week 02 will still come before week 10
"""
if len(date) == 2:
return date
else:
return '0' + date
udf_date2weeknumber = F.udf(date2weeknumber, StringType())
# convert the Date column to spark timestamp format to retrieve the time,
# date formats follow the formats at java.text.SimpleDateFormat
#
# Reference
# ---------
# http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html
# https://stackoverflow.com/questions/25006607/how-to-get-day-of-week-in-sparksql
timestamp_format = 'MM/dd/yyyy'
crime = (df.
withColumn('DateTime',
F.unix_timestamp(F.col('Date'), timestamp_format).cast('timestamp')).
withColumn('WeekOfYear', F.weekofyear(F.col('DateTime')).cast('string')).
withColumn('WeekOfYear', udf_date2weeknumber(F.col('WeekOfYear'))).
withColumn('Year', F.year(F.col('DateTime')).cast('string')).
withColumn('Time', F.concat(F.col('Year'), F.col('WeekOfYear'))))
crime.take(1)
# 1. don't really need orderBy, it's
# just to make the output cleaner;
# 2. rename the count column to label to
# make it the label column for the modeling part;
# 3. we will be using the crime count dataframe a lot
# to perform the modeling, thus cache it to store it
# in memory
crime_count = (crime.
select('Beat', 'Time').
groupby('Beat', 'Time').
count().
withColumnRenamed('count', 'label').
orderBy('Beat', 'Time').
cache())
crime_count.show()
# find all the distinct beat and train the model on each
# beat to generate the prediction for next week
beats = (crime_count.
select('Beat').
distinct().
rdd.map(lambda x: x.Beat).
collect())
# we will use one of the beat to demonstrate the modeling for now
beat = '1011'
subset = (crime_count.
filter(F.col('Beat') == beat).
drop('Beat'))
subset.show()
def create_lagged_features(spark_df, window_col, feature_col, n_lags):
"""
Reference
---------
https://stackoverflow.com/questions/34295642/spark-add-new-column-to-dataframe-with-value-from-previous-row
"""
w = Window().partitionBy().orderBy(window_col)
lagged = (subset.
withColumn('Lag1', F.lag(F.col(feature_col), count = 1).over(w)).
na.drop())
for lag in range(1, n_lags):
previous_col = 'Lag' + str(lag)
current_col = 'Lag' + str(lag + 1)
lagged = (lagged.
withColumn(current_col, F.lag(F.col(previous_col), count = 1).over(w)).
na.drop())
# after creating the lag sort the time by descending order
# so it will be easier to project to the future
lagged = lagged.orderBy(window_col, ascending = False)
return lagged
# after creating the lagged features
n_lags = 4
window_col = 'Time'
feature_col = 'label'
lagged = create_lagged_features(subset, window_col, feature_col, n_lags)
lagged.show()
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
# assemble all the columns into one single 'features' column and train
# a randomforest model (includes cross validation and grid search on the
# maxDepth parameter); we will use r squared to pick to best model; when
# having a multi-step process, the recommended way is to define every
# stage inside a pipeline
input_cols = ['Lag' + str(j) for j in range(1, n_lags + 1)]
assembler = VectorAssembler(inputCols = input_cols, outputCol = 'features')
rf = RandomForestRegressor(numTrees = 30)
stages = [assembler, rf]
pipeline = Pipeline(stages = stages)
param_grid = ParamGridBuilder().addGrid(rf.maxDepth, [5, 6, 7]).build()
evaluator = RegressionEvaluator(labelCol = 'label',
predictionCol = 'prediction',
metricName = 'r2')
rf_grid = CrossValidator(
estimator = pipeline,
estimatorParamMaps = param_grid,
evaluator = evaluator,
numFolds = 3
).fit(lagged)
lagged_fitted = rf_grid.transform(lagged)
lagged_fitted.show()
eval_metric = evaluator.evaluate(lagged_fitted)
eval_metric
# to predict for next week, the prediction column will now become one of
# the latestest lagged feature and everything will also get shifted down
# by 1 time slot (i.e. prediction -> Lag1, Lag1 -> Lag2 and so on)
next_week = lagged_fitted.limit(1).drop('features', 'label', 'Lag' + str(n_lags))
for lag in reversed(range(1, n_lags)):
current_col = 'Lag' + str(lag)
next_col = 'Lag' + str(lag + 1)
next_week = next_week.withColumnRenamed(current_col, next_col)
next_week = next_week.withColumnRenamed('prediction', 'Lag1')
next_week_pred = rf_grid.transform(next_week)
prediction = (next_week_pred.
rdd.map(lambda x: x.prediction).
collect()[0])
next_week_pred.show()
The following section ties everything together: loop through all the beats, create the lagged feature, make the prediction for the next week, report the prediction and the model's performance.
import pandas as pd
from tqdm import tqdm
# switch to loop over the unqiue_beats variable to predict on all the beats
results = []
for beat in tqdm(['1011', '2033']):
subset = (crime_count.
filter(F.col('Beat') == beat).
drop('Beat'))
# some beats might not have enough records,
# here we simply leave them out
if subset.count() > 30:
# create lagged column for 4 time period
# e.g. use week 1, 2, 3's number to predict the
# number for week 4
n_lags = 4
window_col = 'Time'
feature_col = 'label'
lagged = create_lagged_features(subset, window_col, feature_col, n_lags)
# tune the max depth of a random forest with a 5 fold cross validation
input_cols = ['Lag' + str(j) for j in range(1, n_lags + 1)]
assembler = VectorAssembler(inputCols = input_cols, outputCol = 'features')
rf = RandomForestRegressor(numTrees = 30)
stages = [assembler, rf]
pipeline = Pipeline(stages = stages)
param_grid = ParamGridBuilder().addGrid(rf.maxDepth, [5, 6, 7]).build()
evaluator = RegressionEvaluator(labelCol = 'label',
predictionCol = 'prediction',
metricName = 'r2')
rf_grid = CrossValidator(
estimator = pipeline,
estimatorParamMaps = param_grid,
evaluator = evaluator,
numFolds = 3
).fit(lagged)
lagged_fitted = rf_grid.transform(lagged)
# transform the data to perform the prediction for the next week
next_week = (lagged_fitted.
limit(1).
drop('features', 'label', 'Lag' + str(n_lags)))
for lag in reversed(range(1, n_lags)):
current_col = 'Lag' + str(lag)
next_col = 'Lag' + str(lag + 1)
next_week = next_week.withColumnRenamed(current_col, next_col)
next_week = next_week.withColumnRenamed('prediction', 'Lag1')
next_week_pred = rf_grid.transform(next_week)
prediction = (next_week_pred.
rdd.map(lambda x: x.prediction).
collect()[0])
eval_metric = evaluator.evaluate(lagged_fitted)
result = beat, prediction, eval_metric
results.append(result)
df_results = pd.DataFrame(results, columns = ['beat', 'prediction', 'r2'])
df_results
Question 4¶
Find patterns of crimes with arrest with respect to time of the day, day of the week, and month.
Base on the results below, we see crimes mostly happen during the evening, the summer and on weekdays. The rationale behind why summer time has the most crimes was already mentioned in question 1 and the fact that most crime happens during the evening is not that surprising as well as that's when there are less people on the street to help you and the lack of sunlight also gives the criminial an advantage (i.e. you might not notice them approaching or remember how their face looks like).
As for why there is a huge drop in the number of crimes during Sunday, one possible reason is people tend to spend the evening at home to get ready for Monday. Thus there's less chance of being a subject of criminal activities.
data_path = 'Crimes_-_2001_to_present.csv'
df = spark.read.csv(data_path, sep = ',', header = True)
# convert the Date column to spark timestamp format to retrieve the time,
# date formats follow the formats at java.text.SimpleDateFormat
#
# Reference
# ---------
# http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html
# https://stackoverflow.com/questions/25006607/how-to-get-day-of-week-in-sparksql
timestamp_format = 'MM/dd/yyyy HH:mm:ss aa'
crime = (df.
withColumn('Arrest', df['Arrest'].cast('boolean')).
filter(F.col('Arrest')).
withColumn('DateTime',
F.unix_timestamp(F.col('Date'), timestamp_format).cast('timestamp')))
crime.take(1)
crime_per_hour = (crime.
select(F.hour(F.col('DateTime')).alias('Hour')).
groupby('Hour').
count().
orderBy('Hour').
toPandas())
crime_per_hour.to_csv('crime_per_hour.csv', index = False)
crime_per_hour
# 'EEEE' stands for the full name of the weekday
crime_per_day = (crime.
select(F.date_format(F.col('DateTime'), 'EEEE').alias('Day')).
groupby('Day').
count().
toPandas())
crime_per_day.to_csv('crime_per_day.csv', index = False)
crime_per_day
crime_per_month = (crime.
select(F.month(F.col('DateTime')).alias('Month')).
groupby('Month').
count().
orderBy('Month').
toPandas())
crime_per_month.to_csv('crime_per_month.csv', index = False)
crime_per_month
# terminate the spark session
spark.stop()